{kind=link}
Changelog#
Note
This is not exhaustive. For an exhaustive list of changes, see the git log.
2026.7.0#
Highlights#
Support composite expressions with the
__dask_exprs__protocol and avoid graph materialization when checking expr-wrapper Dask collections (dask#12457, dask#12476) Matthew RocklinUpdate compatibility for NumPy 2.5 type stubs, pandas 3 nightlies, pytest 9.1, and free-threaded msgpack builds (dask#12483, dask#12469, dask#12465, dask#12467, distributed#9312, distributed#9304, distributed#9303, distributed#9302) Guido Imperiale
Return all workers from
scheduler_info()by default (distributed#9308) Matthew RocklinKeep
Client.scatterfrom unpacking custom containers (distributed#9298) Adrin JalaliFix Distributed worker startup and aborted TCP communication races (distributed#9313, distributed#9315) Guido Imperiale
Additional changes
Upgrade pixi (dask#12460) Matthew Rocklin
Fix release publisher warnings (dask#12456, distributed#9299) Matthew Rocklin
XFAIL
test_concat_categorical(again) (dask#12463) Guido ImperialeCI: Suppress warning about slow disk (dask#12464) Guido Imperiale
Support for pytest 9.1 (dask#12465, distributed#9303) Guido Imperiale
Free-threading: use upstream msgpack (dask#12467, distributed#9302) Guido Imperiale
CI: Suppress numpy
generictimedelta deprecation from pandas (dask#12468) Guido ImperialePin pandas 3 nightlies (dask#12469, distributed#9304) Guido Imperiale
Bump actions/checkout from 6 to 7 (dask#12473, distributed#9306)
Fix randomly failing s3fs checkouts in nightly CI (dask#12474) Guido Imperiale
Avoid graph materialization in
is_dask_collectionfor expr wrappers (dask#12476) Matthew RocklinBump prefix-dev/setup-pixi from 0.9.6 to 0.10.0 (dask#12478, distributed#9310)
Bump actions/cache from 5 to 6 (dask#12479, distributed#9309)
Avoid NumPy 2.5 type stubs (dask#12483, distributed#9312) Guido Imperiale
Bump actions/download-artifact from 7 to 8 (dask#12461, distributed#9301)
Support composite expressions with
__dask_exprs__protocol (dask#12457) Matthew RocklinReturn all workers from
scheduler_info()by default (distributed#9308) Matthew RocklinClient.scattershould not unpack custom containers (distributed#9298) Adrin JalaliSuppress mindeps warning when running a single test in CI crusaderky
AI agent skill to debug flaky tests (distributed#9319) Guido Imperiale
Fix Nanny race conditions when worker fails to start (distributed#9313) Guido Imperiale
Fix server hanging on aborted TCP comms (distributed#9315) Guido Imperiale
Fix conda build CI (distributed#9314) Guido Imperiale
Update deprecated CUDA system requirements in Pixi (distributed#9311) Guido Imperiale
2026.6.0#
Highlights#
Improve pandas 3.1 compatibility, including
add_prefix/add_suffixandDataFrame.dropchanges (dask#12414, dask#12447) Guido ImperialeFix groupby compatibility with pandas 2.2 and 2.3 and test against intermediate NumPy and pandas versions (dask#12372) Guido Imperiale
Store empty arrays with Zarr 3.2.0 (dask#12366) Guido Imperiale
Fix quantile and nanquantile behavior (dask#12380) Guido Imperiale
Add support for Cholesky decomposition with complex dtypes (dask#12416) Niclas Rieger
Fix dataframe correctness issues in
DataFrame.mergeandSeries.map(dask#12430, dask#12432) nn, Mike EvdokimovOverhaul the
publish_datasetextension (distributed#9217) Guido ImperialeOverhaul task stream handling (distributed#9230, distributed#9282, distributed#9293) Guido Imperiale, MohammadYusif
Fix a race condition in
SubprocessClusterstartup (distributed#9292) Guido ImperialeClean up deprecated Distributed APIs across scheduler, worker, CLI, plugin, and progress handling (distributed#9222, distributed#9225, distributed#9238, distributed#9240, distributed#9250) Guido Imperiale
Migrate CI and local workflows to Pixi (dask#12389, distributed#9276) Guido Imperiale
Add AI contribution guidance with AGENTS.md and CLAUDE.md (dask#12415, distributed#9279) Guido Imperiale
Add PyPI release workflows with GitHub Actions Trusted Publishing (dask#12452, distributed#9297) Matthew Rocklin
Additional changes
Pandas 3.1: The inplace keyword in DataFrame.drop is deprecated (dask#12447) Guido Imperiale
test_concat_categoricalis still flaky on Pandas 2.0 (dask#12454) Guido ImperialeAdd tests for the array
assert_eqhelper (dask#12441) きょうすけRevert security autoescape change in HTML reprs (dask#12451) Guido Imperiale
Fix Dataframe.merge losing data when there are 128 or 129 partitions (dask#12430) nn
Security: enable Jinja2 autoescape to prevent XSS in HTML reprs (dask#12423) dfgvaetyj3456356-hash
Test vs. NumPy 1.26 and PyArrow 18 (dask#12445) Guido Imperiale
Do not build the dask-core pixi package twice (dask#12443) Guido Imperiale
Fix broken condition in
test_cpu_affinity_taskset(dask#12399) Elliott Sales de AndradeFix flaky
test_interrupt(dask#12437) Guido ImperialeFree-threading: enable msgpack C extension (dask#12439) Guido Imperiale
Fix
Series.map(Series)producing wrong results for non-co-aligned inputs (dask#12432) Mike EvdokimovRepair Upstream CI (dask#12436) Guido Imperiale
Strictly expect test failures (dask#12435) Guido Imperiale
Update pixi lockfile (dask#12433) Guido Imperiale
Add more thorough tests for
Series.mapand fix pandas nightly CI (dask#12425) Guido ImperialeAdd AGENTS.md / CLAUDE.md and clarify guidelines for AI pull requests (dask#12415) Guido Imperiale
Tweak local coverage HTML report (dask#12422) Guido Imperiale
Make tests less dependent on urllib3 and requests (dask#12419) Guido Imperiale
Fix trivial Sphinx warning crusaderky
Do not run scheduled tests on forks (dask#12418) Guido Imperiale
Only upload conda packages from main branch crusaderky
Repair conda upload (dask#12417) Guido Imperiale
Fix
add_prefix/add_suffixin pandas nightly and support explicit axis (dask#12414) Guido ImperialeRemove legacy pandas dtype testing strings vs. decimals (dask#12413) Guido Imperiale
Better type annotations for
import_optional_dependency(dask#12412) Guido ImperialeResurrect PySpark tests (dask#12410) Guido Imperiale
Test on Linux ARM (dask#12408) Guido Imperiale
Fix failures in
test_describevs. pandas nightly (dask#12409) Guido ImperialeMigrate CI to Pixi (dask#12389) Guido Imperiale
Fix typos (dask#12405) Guido Imperiale
XFAIL regression in click 8.4.0 (dask#12407) Guido Imperiale
Fix flaky
test_shared_tasksin free-threading (dask#12398) Guido ImperialeEnforce Python 3.10 compatibility in black (dask#12397) Guido Imperiale
Update Optuna+Dask example to use optuna-integration (dask#12385) Mike Evdokimov
Fix flaky
test_store_locks(dask#12393) Guido ImperialeXFAIL flaky
test_len(dask#12396) Guido ImperialeRun some tests serially in pytest-xdist (dask#12395) Guido Imperiale
test_orcsegfaults with PyArrow 16 (dask#12394) Guido ImperialeUnskip
test_map_block_series(dask#12392) Guido ImperialeSpeed up
test_from_delayed_future(dask#12391) Guido ImperialeFix duplicated words in dask.array routines and slicing docstrings (dask#12390) lphuc2250gma
Simplify
test_dotand suppress spurious test outputs (dask#12388) Guido ImperialeTest vs. intermediate versions of numpy and pandas (dask#12372) Guido Imperiale
Clean up obsolete version check in
test_http(dask#12387) Guido ImperialeFix LaTeX formula for split_every in docstrings (dask#12379) stephenworsley
Remove numexpr (dask#12384) Guido Imperiale
Unit-less timedelta64 is deprecated in NumPy nightly (dask#12383) Guido Imperiale
Require
pyyaml >=5.4.1(dask#12382) Guido ImperialeRe-raise ModuleNotFoundError instead of ImportError (dask#12381) Guido Imperiale
Fix flaky
test_ffill_bfill(dask#12378) Guido ImperialeRaise NotImplementedError for
da.quantilewith weights on NumPy < 2.0 (dask#12370) Dr Alex MitreFix typo in array-chunks.rst (dask#12375) Henry
Minor docs tweaks (dask#12377) Guido Imperiale
Clean up minimum pyarrow version checks (dask#12376) Guido Imperiale
Use Python 3.14 in additional and upstream envs and dev docs (dask#12373) Guido Imperiale
More test fixes for pandas-nightly (dask#12369) Guido Imperiale
Switch back to conda (dask#12368) Guido Imperiale
Disable CI for Windows 3.14t (dask#12367) Guido Imperiale
Use f-strings (dask#12362) Dimitri Papadopoulos Orfanos
Store empty arrays with zarr 3.2.0 (dask#12366) Guido Imperiale
Fix some pandas nightly deprecation warnings (dask#12341) Trevin Chow
3.14t CI: tweak notes (dask#12363) Guido Imperiale
Use f-strings (dask#12354) Dimitri Papadopoulos Orfanos
Docs: order array arguments in docstring (dask#12342) Peter A. Jonsson
numba is now available on conda-forge for 3.14t (dask#12358) Guido Imperiale
__package__to__spec__.parent(dask#12333) Dimitri Papadopoulos OrfanosUpdate pre-commit black hook (dask#12344) Dimitri Papadopoulos Orfanos
Update pre-commit ruff hook (dask#12345) Dimitri Papadopoulos Orfanos
Fix typos (dask#12339) Dimitri Papadopoulos Orfanos
Add numba, sparse, and h5py to 3.14t CI (dask#12338) Guido Imperiale
Improve Contribution Policy (dask#12320) Jacob Tomlinson
Fix test failures caused by port 8787 already in use (distributed#9296) Guido Imperiale
Migrate from black to
ruff format(distributed#9295) Guido ImperialeFix race condition in SubprocessCluster startup (distributed#9292) Guido Imperiale
Refactor
get_task_stream(distributed#9293) Guido ImperialeDo not build the distributed pixi package twice (distributed#9289) Guido Imperiale
Fix flaky
test_steal_twiceandtest_steal_when_more_tasks(distributed#9288) Guido ImperialeClarify scheduler unpickling in protocol docs (distributed#9286) Peter Chen J.
Reinstate no-queue tests (distributed#9287) Guido Imperiale
Clarify unsatisfied resource restrictions in resource docs (distributed#9269) Peter Chen J.
Fix import-time coverage (distributed#9284) Guido Imperiale
Improve CLI error message for unknown options to dask worker (distributed#9281) Zeus Almightee
Run most CUDA tests in pixi (distributed#9285) Guido Imperiale
Migrate CI to pixi (distributed#9276) Guido Imperiale
Add AGENTS.md / CLAUDE.md and guidelines for AI pull requests (distributed#9279) Guido Imperiale
Fix tests vs. NumPy nightly builds (distributed#9280) Guido Imperiale
uvloop tests (distributed#9278) Guido Imperiale
Fix flaky
test_call_stack_future(distributed#9277) Guido ImperialeDrop dependency on urllib3 (distributed#9273) James Lamb
Remove
avoid_cimark (distributed#9275) Guido ImperialePrint host_info in CI without needing NumPy (distributed#9274) Guido Imperiale
Fix typos (distributed#9268) Guido Imperiale
Support pixi in dask/dask CI (distributed#9264) Guido Imperiale
Truncate large coro repr in retry log output (distributed#9197) Ernest Provo
Add explicit check for name not None (distributed#9265) Maneesh Sutar
XFAIL
test_scheduler_bokeh.py::test_simplein Windows (distributed#9266) Guido ImperialeClean up deprecated loop properties (distributed#9231) Guido Imperiale
Clean up deprecations in Scheduler, Worker, Nanny (distributed#9238) Guido Imperiale
Clean up deprecated client context in different tasks/threads (distributed#9233) Guido Imperiale
Clean up deprecated Prometheus metrics (distributed#9249) Guido Imperiale
Clean up deprecations in
distributed.deploy(distributed#9244) Guido ImperialeClean up deprecated
streamRPC handler argument (distributed#9242) Guido ImperialeDeprecations in CLI (distributed#9240) Guido Imperiale
Clean up deprecations in
security(distributed#9239) Guido ImperialeClean up deprecated rpc synchronous context manager (distributed#9235) Guido Imperiale
Clean up deprecated async
listener.stop()(distributed#9234) Guido ImperialeClean up deprecations in
register_plugin(distributed#9225) Guido ImperialeClean up deprecations in
remove_worker(distributed#9222) Guido ImperialeClean up minimum pyarrow version checks (distributed#9260) Guido Imperiale
Partial review of task streams (distributed#9230) Guido Imperiale
Update outdated work stealing docs regarding worker restrictions (distributed#9214) Kevin Ziroldi
Fix memray CI; move back from mamba to conda (distributed#9258) Guido Imperiale
Install keras with conda (distributed#9259) Guido Imperiale
Clean up Cython (distributed#9257) Guido Imperiale
Use
@dataclass(slots=True)with constraints from Python <3.14 (distributed#9256) Guido ImperialeType annotations for
client.Future(distributed#9255) Guido ImperialeClean up deprecated Lock client parameter (distributed#9237) Guido Imperiale
Clean up deprecated nested_deserialize (distributed#9243) Guido Imperiale
Deprecations in
distributed.compatibility(distributed#9232) Guido ImperialeClean up deprecations in
utils_test(distributed#9226) Guido ImperialeClean up deprecations in
distributed.utils(distributed#9236) Guido ImperialeClean up deprecations in ProgressBar (distributed#9250) Guido Imperiale
Run more tests when requests is not installed (distributed#9251) Guido Imperiale
Standardize and increase
async_poll_fortimeout (distributed#9248) Guido ImperialeRelax unreasonably short test timeouts (distributed#9247) Guido Imperiale
Use f-strings (distributed#9245) Dimitri Papadopoulos Orfanos
Update link to bokeh sources in comment (distributed#9241) Guido Imperiale
Apply ruff/pyupgrade rule UP031 (distributed#9204) Dimitri Papadopoulos Orfanos
Homogeneous environment names (distributed#9209) Dimitri Papadopoulos Orfanos
Overhaul
publish_datasetextension (distributed#9217) Guido ImperialeFix flaky
test_mixing_clients_same_scheduler(distributed#9229) Guido ImperialeType hints:
@contextmanagershould returnGenerator[T](distributed#9228) Guido ImperialeFix flaky
test_actor.py::test_failed_worker(distributed#9227) Guido ImperialeClean up info parameters in transition to memory (distributed#9221) Guido Imperiale
Move state validation from Scheduler to SchedulerState (distributed#9224) Guido Imperiale
Bump to black 26.3.1 (distributed#9223) Guido Imperiale
Tweak scheduler annotations (distributed#9220) Guido Imperiale
Fix typos (distributed#9203) Dimitri Papadopoulos Orfanos
Bug: dashboard would not show no-worker tasks (distributed#9215) Guido Imperiale
2026.3.0#
Highlights#
Preliminary Python 3.14t support (dask#12223) Guido Imperiale
Bokeh 3.9.0 compatibility (distributed#9205) Dimitri Papadopoulos Orfanos
Additional changes
docs: document approximate algorithm and Dask-specific params in describe() (dask#12300) `Maxime Grenu`_
docs: clarify coarsen reduction function contract (dask#12314) `monkeyjack123`_
Fix misleading TypeError for scalar overflow in dask.array elemwise (dask#12301) `Maxime Grenu`_
Stricter warnings filter (dask#12274) Guido Imperiale
Clean up obsolete PANDAS_GE markers (dask#12279) Guido Imperiale
Remove mention of obsolete default value for ‘boundary’ parameter. (dask#12304) `Marianne Corvellec`_
Pandas in 3.14t CI (dask#12284) Guido Imperiale
Quadratic definition time in xarray.DataArray.to_zarr(compute=False) (dask#12299) Guido Imperiale
test_tokenize_range_indexfails if cityhash is not installed (dask#12286) Guido ImperialeBump minimum version of scipy (dask#12271) Guido Imperiale
Fix flaky categorical concat test (dask#12276) `Harshith J`_
Doc: document Zarr compression options for to_zarr (dask#12269) `Harshith J`_
Disable the GIL on 3.14t Windows CI (dask#12280) Guido Imperiale
Update obsolete pandas URLs (dask#12278) Guido Imperiale
Suppress warning: Consolidated metadata is not part of Zarr 3 (dask#12273) Guido Imperiale
Pandas4Warning: Copy-on-Write is always enabled with pandas >= 3.0 (dask#12272) Guido Imperiale
Disable the GIL in 3.14t CI (dask#12270) Guido Imperiale
Propagate contextvars to worker threads; catch warnings in 3.14t (dask#12224) Guido Imperiale
Fix bugs in env.yaml / pytest.xml upload (dask#12266) Guido Imperiale
Added
full_matricesparameter todask.array.linalg.svd(dask#12292) `Ayan Bag`_fix:
zarr.create_arrayfor better backward compatibility (dask#12291) Wouter-Michiel VierdagSilence deprecations in global config if local config overrides them (dask#12315) Guido Imperiale
Fix Total CPU % on /workers tab to normalize by total nthreads (distributed#9195) Ernest Provo
setproctitle: avoid being caught by dask.config; add to test envs (distributed#9202) Guido Imperiale
Add return type annotation for Client._register_plugin (distributed#9201) Simon-Martin Schröder
docs: fix Scheduler.close docstring (distributed#9198) `Chase Naples`_
Fix Total CPU % on /workers tab to normalize by total nthreads (distributed#9195) Ernest Provo
XFAIL test_handle_null_partitions_2 (distributed#9191) Guido Imperiale
Type hints for Future.status (distributed#9188) `Navid`_
Pin sphinx=8 (distributed#9190) Guido Imperiale
2026.2.0#
Highlights#
Additional changes
Minimum version of optional dependency scipy bumped to 1.10.0 (was 1.7.2)
2026.1.2#
Highlights#
dask.dataframe now requires PyArrow 16 or greater (was 14)
Have
**kwargsinto_zarrfollow zarr-python API and addmodeargument (dask#12205) Wouter-Michiel Vierdag
Note
Passing on io-related arguments in **kwargs in to_zarr will be deprecated
and read_kwargs argument as well as zarr_array_kwargs (dict) introduced in 2025.12.0
has been removed.
If you passed on either mode or read_only as **kwargs or read_kwargs in
to_zarr, please use the new mode argument. The read_only argument can still
be passed on, but it will give a warning and have no effect (given that to_zarr
is meant to write this should not be an issue). For now no error will be thrown.
**kwargs in to_zarr has been renamed as **zarr_array_kwargs to indicate
that this directly follows the zarr-python API of Group.create_array
when zarr>v3.0.0 and zarr.create for zarr<v3.0.0. Please see
dask.array.to_zarr() for more.
Additional changes
Minimum version of optional dependency h5py bumped to 3.7.0 (was 3.4.0)
Minimum version of optional dependency python-snappy bumped to 0.7.1 (was 0.6.0)
Minimum version of optional dependency tiledb bumped to 0.27.0 (was 0.12.0)
2026.1.1#
Highlights#
Fix XSS vulnerability CVE-2026-23528 Jacob Tomlinson
Support duck-typed Futures in task graph processing (dask#12213) Matthew Rocklin
Additional changes
Remove the Python 2 Comment (dask#12229) Vipin Kataria
Fix changelog: distributed-pr -> pr-distributed (dask#12227) Matthew Plough
Support duck-typed Futures in task graph processing (dask#12213) Matthew Rocklin
Relax test_serialization (dask#12226) Guido Imperiale
[cosmetic] Reorganise dependency groups in CI environment files (dask#12222) Guido Imperiale
Review _array_expr_enabled() (dask#12217) Guido Imperiale
Increase coverage; lower codecov threshold to pass (dask#12214) Guido Imperiale
Test array expr on mindeps (dask#12216) Guido Imperiale
Disable some Mac builds (dask#12218) Guido Imperiale
Typing tweaks (dask#12215) Guido Imperiale
[CI] unbreak codecov (dask#12211) Guido Imperiale
Test array expr on Python 3.14 (dask#12212) Guido Imperiale
Fix pickle compatibility for Python 3.14 (dask#12206) Matthew Rocklin
Remove deprecated dask._compatibility.entry_points (dask#12202) Guido Imperiale
Tweak MacOS CI (dask#12200) Guido Imperiale
Remove obsolete CI pins (dask#12199) Guido Imperiale
Fix XSS vulnerability CVE-2026-23528 Jacob Tomlinson
Clean up obsolete pins in CI (distributed#9172) Guido Imperiale
Fix incompatibility of pyparsing vs. packaging in mindeps CI (distributed#9170) Guido Imperiale
Bump mypy; fix mypy failure (distributed#9171) Guido Imperiale
2026.1.0#
Broken yanked release, please ignore.
2025.12.0#
Highlights#
More improvements for pandas 3.x Tom Augspurger
Support zarr sharding through create_array (dask#12153) Wouter-Michiel Vierdag
Various improvements for project linting and type hinting Dimitri Papadopoulos Orfanos
Add new “optimization.tune.active” configuration option to disable partition fusion (dask#12194) Richard (Rick) Zamora
Additional changes
Stable sort in Series.value_counts for pandas 3.x (dask#12191) Tom Augspurger
Add new “optimization.tune.active” configuration option to disable partition fusion (dask#12194) Richard (Rick) Zamora
Build llms.txt files in Sphinx documentation (dask#12192) Jacob Tomlinson
Support zarr sharding through create_array (dask#12153) Wouter-Michiel Vierdag
Support min/max of datetime (dask#12183) Julia Signell
pandas 3.x compatibility (dask#12180) Tom Augspurger
Minimal version of setuptools-scm (dask#12184) Dimitri Papadopoulos Orfanos
Update test_ufunc_meta for upstream-dev failure (dask#12170) Tom Augspurger
Upstream compat (dask#12165) Tom Augspurger
Enforce a few more ruff rules (dask#12157) Dimitri Papadopoulos Orfanos
Enforce ruff/refurb rules (FURB) (dask#12144) Dimitri Papadopoulos Orfanos
DEP: bump minimal requirement on toolz (0.10.0 -> 0.12.0) (dask#12163) Clément Robert
Fix execution stop in da.to_zarr due to (misleading) PerformanceWarning raised as exception (dask#12161) Marvin Albert
Use f-string interpolation where possible (dask#12140) Dimitri Papadopoulos Orfanos
pre-commit black hook: use implicit defaults (dask#12156) Dimitri Papadopoulos Orfanos
Enforce ruff/pygrep-hooks rules (PGH) (dask#12143) Dimitri Papadopoulos Orfanos
Apply Repo-Review rules (dask#12148) Dimitri Papadopoulos Orfanos
Document groupby: split_every, split_out (dask#12135) Jayesh Manani
isort → ruff (dask#12149) Dimitri Papadopoulos Orfanos
Enforce ruff/pyupgrade rule UP031 (dask#12137) Dimitri Papadopoulos Orfanos
Replace pre-commit hook with ruff rule (dask#12142) Dimitri Papadopoulos Orfanos
Fix reify to handle sparse arrays and other objects without __len__ (dask#12103) Gautham Hullikunte
Ruff supersedes absolufy-imports (dask#12141) Dimitri Papadopoulos Orfanos
Enforce ruff/pyupgrade rule UP032 (dask#12136) Dimitri Papadopoulos Orfanos
Typing fixes (distributed#9159) Jacob Tomlinson
Explicit setuptools-scm minimum version (distributed#9160) Jacob Tomlinson
Enforce ruff rules (RUF) (distributed#9153) Dimitri Papadopoulos Orfanos
Clean up MANIFEST.in (distributed#9149) Dimitri Papadopoulos Orfanos
isort → ruff (distributed#9152) Dimitri Papadopoulos Orfanos
Ruff supersedes absolufy-imports (distributed#9154) Dimitri Papadopoulos Orfanos
Bump minimum supported
toolzto 0.12.0 (distributed#9151) James Bourbeauflake8, bugbear, pyupgrade → ruff (distributed#9147) Dimitri Papadopoulos Orfanos
Fix typos found by codespell (distributed#9145) Dimitri Papadopoulos Orfanos
Clean up setuptools-specific configuration (distributed#9150) Dimitri Papadopoulos Orfanos
PEP 639 compliance (distributed#9146) Dimitri Papadopoulos Orfanos
Update black (distributed#9148) Dimitri Papadopoulos Orfanos
Fix empty progress bar (distributed#9144) Jacob Tomlinson
Exclude broken tblib versions in CI (distributed#9141) Jacob Tomlinson
2025.11.0#
Highlights#
Use shard shape when available in
to_zarr(dask#12105) Davis BennettImprove worker and nanny support for ipv6 (distributed#9133) Jianyu Sun
Linting and type hinting improvements across the codebase
Additional changes
Replace
versioneerwithsetuptools-scm(dask#12133) Jacob TomlinsonApply ruff/Pylint Refactor rules (PLR) (dask#12010) Dimitri Papadopoulos Orfanos
Remove files from
MANIFEST.in(dask#12041) Dimitri Papadopoulos OrfanosStabilize
test_filter_nonpartition_columns(dask#12131) DongWonEnforce ruff/pyupgrade rules UP007 and UP033 (dask#12125) Dimitri Papadopoulos Orfanos
Update
np.accumulateworkaround comment (dask#12129) Jacob Tomlinsonflake8,bugbear,pyupgrade→ruff(dask#12002) Dimitri Papadopoulos OrfanosAdjust pyarrow version skip in
test_parquet(dask#12124) Tom AugspurgerFix ufunc in
dask.array.cumreduction(dask#12119) Tony DingFix docs footer (dask#12120) Jacob Tomlinson
Use integer multiple of shard shape when rechunking in
to_zarr(dask#12106) Davis BennettEnsure that the shard shape is used as the default chunk shape for sharded Zarr arrays (dask#12104) Davis Bennett
Skip
test_parquetforpyarrow==22.0(dask#12116) Tom AugspurgerClean up setuptools-specific configuration (dask#12040) Dimitri Papadopoulos Orfanos
PEP 639 compliance (dask#12024) Dimitri Papadopoulos Orfanos
Fix deprecated quantile
interpolationbeing passed to numpy (dask#12108) David HoeseAdd
uv.lockto.gitignore(dask#12110) Jacob TomlinsonUse shard shape when available in
to_zarr(dask#12105) Davis BennettAdd more optional dependencies to Python 3.13 CI builds (dask#12100) James Bourbeau
Remove
pippin for docs (dask#12102) James BourbeauAddress collection-based
metaarguments inGroupByApply(dask#12099) Richard (Rick) ZamoraReplace versioneer with setuptools-scm (distributed#9137) Jacob Tomlinson
Improve worker and nanny support for ipv6 (distributed#9133) Jianyu Sun
Fix CI Multiple aliased keys in file
/Users/runner/.condarc(distributed#9136) Jacob TomlinsonRemove
pippin for docs (distributed#9132) James BourbeauRemove UCX configuration schema (distributed#9127) Peter Andreas Entschev
Add generic type support to
FutureandClientmethods (distributed#9123) Simon-Martin Schröder
2025.10.0#
Highlights#
Several Dask Array bug fixes including dask#12097, dask#12089, dask#12088, and dask#12090.
Additional changes
Use updated docs theme (dask#12093) Jacob Tomlinson
Fix:
dask.array.cumproddoes not deal withdtype(dask#12097) Tony DingCuPy compatibility for percentile (dask#12098) Tom Augspurger
Avoid using
methods.concaton empty lists (dask#12096) Tony DingAdd distribution check for optional dependencies (dask#12087) James Bourbeau
Fix percentile inconsistencies (dask#12088) Oisin-M
Fix warning in
test_ufunc_where_no_out(dask#12094) Tom AugspurgerFix/choose trivial case (dask#12090) Oisin-M
Add input validation on
dask.dataframe.read_sql_query()(dask#12091) Jacob TomlinsonNumpy 2.2 updates for
covfunction with tests (dask#12079) Mike McCartyFix
nanvar(dask#12089) Oisin-MDocument manually triggering the conda-forge bots (dask#12083) Jacob Tomlinson
Fix mixed HLG/Expr handling in
_ExprSequence._simplify_down(dask#12081) Richard (Rick) ZamoraAdd
dask.tokenizeto API docs (dask#12080) Username46786CreateOverlappingPartitions: Add before and after to prepend name (dask#11965) Fabien AulaireFix
scipy.sparce.csc_matrixscalar declaration in_array_like_safe(dask#12078) Ilan GoldUpdate docs theme and remove docs env pins (distributed#9125) Jacob Tomlinson
Add worker name as prefix to
ThreadPoolExecutorname (distributed#9120) Maneesh SutarSkip hanging SSH tests on Windows (distributed#9115) Jacob Tomlinson
Fix macOS CI failure during job startup (distributed#9113) Jacob Tomlinson
Prevent task stream dashboard showing 1970 date (distributed#9109) Guillaume Eynard-Bontemps
2025.9.2#
This is a backport security release only.
See CVE-2026-23528 for more details.
2025.9.1#
Highlights#
Avoid unconditional pyarrow dependency in dataframe.backends (dask#12075) Tom Augspurger
pandas 3.x compatibility for .groups (dask#12071) Tom Augspurger
Additional changes
Avoid unconditional pyarrow dependency in dataframe.backends (dask#12075) Tom Augspurger
pandas 3.x compatibility for .groups (dask#12071) Tom Augspurger
Expose details about worker start timeout in the exception message (distributed#9092) Taylor Braun-Jones
pynvml => nvidia-ml-py in CI (distributed#9111) Jacob Tomlinson
2025.9.0#
Highlights#
pandas 3.x compatibility (dask#12025) Tom Augspurger
Remove protocol=”ucx” support in favor of distributed-ucxx (distributed#9105) Peter Andreas Entschev
Additional changes
Fix 0 scalar setting for scipy.sparse (dask#12027) Ilan Gold
Workaround failing upstream-dev tests (dask#12061) Tom Augspurger
avoid instantiating a potentially very large arange in take (dask#11998) Justus Magin
MAINT: address NumPy deprecation in np.minimum (dask#12059) Marco Edward Gorelli
CI fixes (dask#12058) Tom Augspurger
MAINT: Address NumPy DeprecationWarning (dask#12056) Marco Edward Gorelli
Fix
test_enforce_columnson Python 3.14 (dask#12047) Elliott Sales de AndradeFix “th” –> “the” typo in DataFrame SQL docs (dask#12038) Peter A. Jonsson
Advance rng state in permutation (dask#12031) James Bourbeau
Fix
pyarrowchunked array conversion (dask#12034) James BourbeauFix
xfailcondition forpyarrowlarge_stringissue (dask#12032) James Bourbeaupandas 3.x compatibility (dask#12025) Tom Augspurger
Fix name not propagated correctly in map_blocks (dask#11952) Ilan Gold
Clean tuples dict keys from workers_info in /api/v1/retire_workers. (distributed#8996) Florian Courtial
Remove protocol=”ucx” support in favor of distributed-ucxx (distributed#9105) Peter Andreas Entschev
2025.7.0#
Highlights#
Account for
__main__inpicklenormalization (dask#11970) James BourbeauEnable column projection in
MapPartitions(dask#11875) Richard (Rick) ZamoraAdd config option for
direct-to-workers(distributed#9097) James Bourbeau
Additional changes
CI: update actions location (dask#12019) Brigitta Sipőcz
Apply
ruff/flake8-comprehensionsrules (C4) (dask#12004) Dimitri Papadopoulos OrfanosApply
ruff/flake8-pierules (PIE) (dask#12006) Dimitri Papadopoulos OrfanosApply
ruff/Pylint Errorrules (PLE) (dask#12013) Dimitri Papadopoulos OrfanosApply
ruff/Pylint Conventionrules (PLC) (dask#12012) Dimitri Papadopoulos OrfanosApply
ruff/flake8-pyirules (PYI) (dask#12007) Dimitri Papadopoulos OrfanosApply
ruff/flake8-simplifyrules (SIM) (dask#12008) Dimitri Papadopoulos OrfanosApply
ruff/PylintWarning rules (PLW) (dask#12011) Dimitri Papadopoulos OrfanosApply
ruff/flake8-implicit-str-concatrules (ISC) (dask#12005) Dimitri Papadopoulos OrfanosApply
ruff/pycodestylerule E714 (dask#12000) Dimitri Papadopoulos OrfanosFix typos found by
codespell(dask#12001) Dimitri Papadopoulos OrfanosUpdate PyPI URL for official nightly
pyarrowrepository (dask#11996) Raúl CumplidoFall-back to textual repr in case
jinja2is not installed (dask#11987) Lukas BindreiterPrevent
builtins.anyfrom being shadowed indask.array.reductions(dask#11988) Marvin AlbertBump
conda-incubator/setup-minicondafrom 3.1.1 to 3.2.0 (dask#11982)Skip groupby cov test for pandas 3.x (dask#11977) Tom Augspurger
Fix
upstreamCI installation (dask#11976) James BourbeauMake module name logic more resilient in
Dispatch(dask#11974) James BourbeauEnsure
memrayprofiler runs on all workers (distributed#9095) James BourbeauUpdate
deftoclasstypo in actors docs (distributed#9091) Peter FackeldeyBump
conda-incubator/setup-minicondafrom 3.1.1 to 3.2.0 (distributed#9090)Update persist in tests for async clients (distributed#9089) Tom Augspurger
Fix
pyarrowFileInfoimport (distributed#9078) James BourbeauMake module name logic more resilient in
_always_use_pickle_for(distributed#9086) James BourbeauTemporarily pin
pytestin CI to avoid coverage error (distributed#9088) James BourbeauRemove
s3fsfrom testing CI environment (distributed#9087) James BourbeauReuse
Commobjects inScheduler.broadcast(distributed#9083) Tom AugspurgerFix
test_resubmit_nondeterministic_task_different_deps(distributed#9085) James Bourbeau
2025.5.1#
Highlights#
Fixed Dask Array slicing regression introduced in the 2025.5.0 release. See dask#11947 from Florian Jetter for more details.
Additional changes
Speed up slicing graph generation (dask#11945) Florian Jetter
Revert “Don’t handle tuple in
task_spec.parse_input” (dask#11953) Florian JetterOptimize slicing graph generation (dask#11946) Florian Jetter
Fix
xarrayslicing regression (dask#11947) Florian JetterDon’t handle tuple in
task_spec.parse_input(dask#11948) Florian Jetter
2025.5.0#
Highlights#
Fixed Array
setitemwhen both the array and the indexer have unknown shape. See dask#11753 from Tom Augspurger for more details.Fixed several
delayedgraph handling issues introduced in the 2025.4.0 release. See dask#11917, dask#11907, and distributed#9071 from Florian Jetter for more details.
Additional changes
Speed up slicing graph generation (dask#11945) Florian Jetter
Optimize dask order for worst case of
get_target(dask#11935) Florian JetterRaise on local executor if tasks are missing dependency (dask#11944) Florian Jetter
Fix
to_dask_arrayfor single partition (dask#11931) James BourbeauEnsure parquet plan is fully cached during optimization (dask#11933) Florian Jetter
Better documentation for expression system (dask#11915) Florian Jetter
Simplify (and speed up) culling (dask#11899) Florian Jetter
Update pre-commit (dask#11926) Florian Jetter
Don’t run post
setup-minicondastep in CI (dask#11925) James BourbeauTry to pin pip for readthedocs (dask#11923) Florian Jetter
Fix windows CI (dask#11919) Florian Jetter
Use stable
crickfor py310 (distributed#9072) Florian JetterRemove internal dependencies mapping in
update_graph(distributed#9036) Florian JetterPartially forgotten dependencies (distributed#9068) Florian Jetter
Replace
filesystem-specin CI environment withfsspec(distributed#9069) James BourbeauEnsure actors set erred state properly in case of worker failure (distributed#9067) Florian Jetter
Refactor timeouts in start cluster (distributed#9062) Florian Jetter
Fix workers / threads / memory displayed in client repr (distributed#9066) James Bourbeau
Pin pip for readthedocs (distributed#9063) Florian Jetter
Skip TLS functional tests (distributed#9061) Florian Jetter
Ensure client submit does not serialize unnecessarily (distributed#9057) Florian Jetter
2025.4.1#
Highlights#
This release contains several graph optimization fixes for issues introduced in the 2025.4.0 release.
See dask#11906, dask#11898, dask#11903, and dask#11904 by Florian Jetter for more details.
Additional changes
Implement
ufuncsandgufuncfor array-expr (dask#11818) Patrick HoeflerImplement
map_overlapfor array-expr (dask#11822) Patrick Hoefler
2025.4.0#
Highlights#
When computing multiple Dask-Expr backed collections like DataFrames, they are now optimized together instead of individually.
Graph materialization and low level optimization is now being performed on the scheduler of a distributed cluster (if available).
New kwarg
forceforDataFrame.shufflewhich signals the optimizer to not drop the shuffle during optimization.Collections that are passed to Dask methods as arguments are now properly optimized. If multiple collections are passed as arguments they will be optimized together. Collections passed this way are prohibited from being being reused, i.e. if the collection is used again in another function call it will be computed again. This pattern is used to avoid pipeline breakers which typically drive memory usage. Avoiding those should reduce memory pressure on the cluster but can cause runtime regressions.
(Special case of above point) Collections passed to Delayed objects are now optimized automatically.
Breaking changes#
Support for custom low level optimizers removed.
Top level
dask.optimizewill now always trigger graph materialization. Previously this was not always the case. This also causes any low level HLG annotations to be dropped.DataFrame and Array compute results are now always concatenated on the cluster. Previously, the behavior was dependent on the API used to call compute (
dask.compute,DaskCollection.compute, orClient.compute).dask.base.collections_to_dskhas been renamed tocollections_to_exprand no longer returns aHighLevelGraphordictobject but instead guarantees andask._expr.Exprobject. Further, it no longer performs low level optimization immediately but instead delays until theExprinstance is materialized, i.e. the returned object is no longer a mapping such that converting it todictor iterating over it is not possible any more.
Additional changes
Ensure
Futurevalue is inda.from_delayedtask graph (dask#11896) Tom AugspurgerFix annotations passed to
delayed(dask#11893) Florian JetterMigrate
delayedunpack_collections(dask#11881) Florian JetterRemove
Pub/Subreferences from docs (dask#11891) James BourbeauEnsure only classes without custom init are singletons (dask#11886) Florian Jetter
Remove custom initializers for
delayedexpressions (dask#11888) Florian JetterFix persisting multiple DFs at the same time (dask#11887) Florian Jetter
Avoid always parsing list inputs to
DataFrame.isinas object typenumpyarrays (dask#11869) Matthew RoeschkeUnskip pandas-dev
cov/corrtests (dask#11873) Tom AugspurgerHLG
blockwisefix (dask#11871) Florian JetterEnsure annotations for HLG objects are properly generated (dask#11866) Florian Jetter
Factor out singleton logic from base
Exprclass (dask#11868) Florian JetterEnsure HLGs are using dependencies properly in optimization (dask#11859) Florian Jetter
Ensure dictionaries tokenize deterministically (dask#11867) Florian Jetter
Ensure default dask scheduler only compute what’s needed (dask#11861) Florian Jetter
Faster tokenization of
pd.RangeIndex(dask#11863) Florian JetterUpdate link to Quansight in community doc (dask#11860) Pavithra Eswaramoorthy
Relax tolerance in
autocorrtest (dask#11857) Tom AugspurgerUse
map_blocksinarray.storeto avoid materialization and dropping of annotations (dask#11844) Florian JetterEnsure
repartitiondoes not trigger memory size computation during lowering (i.e. on the scheduler) (dask#11855) Florian JetterSupport
argsandkwargsfor rolling aggregations (dask#11856) Florian JetterRemove nightly
h5pyfromupstreamCI job (dask#11847) James BourbeauEnsure
HLGExprtokenize uniquely (dask#11849) Florian JetterDo not inject median in describe for
pandas3 (dask#11846) Florian JetterFixed
Expr.__setattr__for subclasses (dask#11845) Tom AugspurgerWrap HLGs in an
Exprto avoidClientside materialization (dask#11736) Florian JetterImprove error when submitting work from a closed client (distributed#9049) James Bourbeau
Return a default value if address resolution fails (distributed#9051) Sandro
Avoid
deepcopywhen submitting graph (distributed#8633) Florian JetterDynamically scale heartbeat and
scheduler_infointervals (distributed#9046) Florian JetterSpeed up process startup time by avoiding importing packages on version check (distributed#9048) Florian Jetter
Reduce size of
scheduler_info(distributed#9045) Florian JetterCache
WorkerStatehost property (distributed#9044) Florian JetterClear ci env cache (distributed#9047) Florian Jetter
Remove deprecated
Pub/Sub(distributed#9039) Florian JetterPerform explicit culling step only if LLG is submitted (distributed#9040) Florian Jetter
Do not fully materialize global annotations by type (distributed#9035) Florian Jetter
Allow nested
worker_clientcalls (distributed#9038) George SakkisDump ci cache (distributed#9037) Florian Jetter
Scheduler type annotations (distributed#9030) Florian Jetter
Reduce
dask.orderoverhead by removingstripped_depcomputation (distributed#9031) Florian JetterUse
Exprinstead of HLG (distributed#9008) Florian Jetter
2025.3.0#
Highlights#
Automatically adjust chunksizes in xarray.apply_ufunc#
apply_ufunc requires the core dimension to have chunksize=-1. The underlying
rechunking operation will automatically adjust the chunksize of the core dimension
but keep the other dimensions the same. This can cause exploding chunksizes under the hood.
This release adds an intermediate step that resizes the non-core dimensions by the same factor
that the core dimension will increase to keep the maximum chunksize under control. This behavior
is automatically enabled when allow_rechunk=True is set.
import xarray as xr
import dask.array as da
arr = xr.DataArray(
da.random.random((1, 750, 45910), chunks=(1, "auto", -1)),
dims=["band", "y", "x"],
)
result = arr.interp(
y=arr.coords["y"],
method="linear",
)
Previously
Individual chunks are exploding to 25 GiB, likely causing out of memory errors.
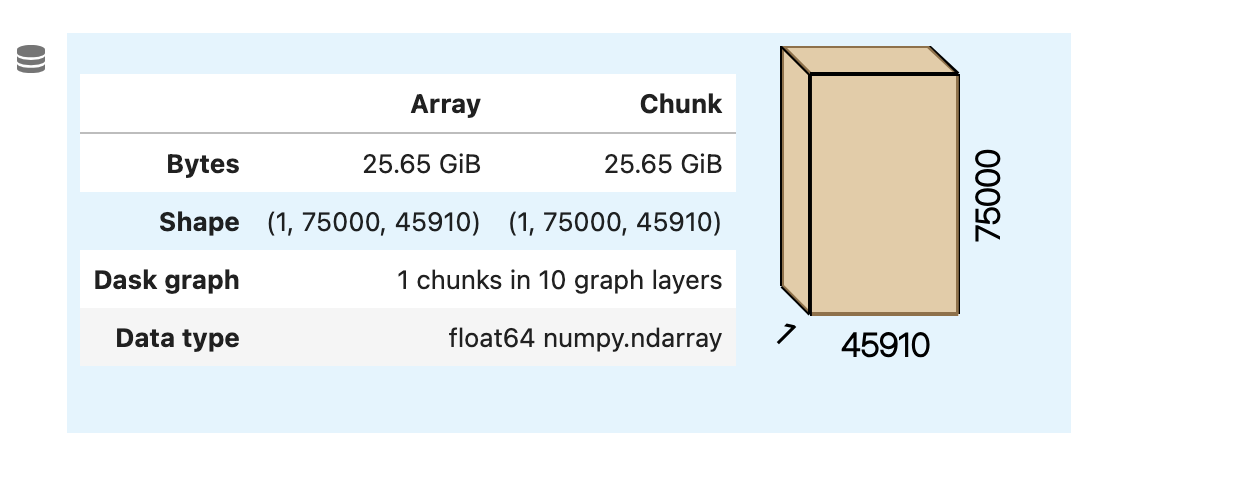
Now
Dask will now automatically split individual chunks into chunks that will have the same chunksize minus a small tolerance.
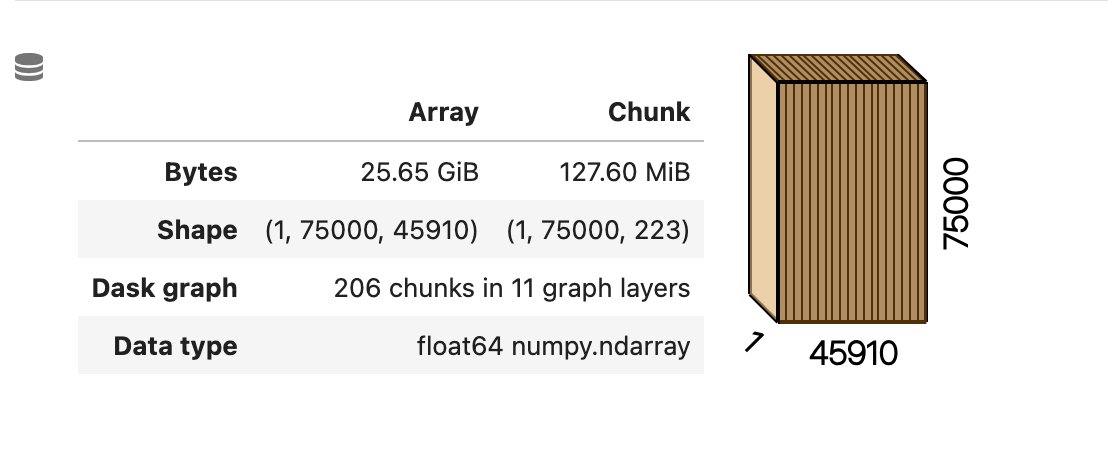
Additional changes
Fix dataset info cache assignment (dask#11840) Florian Jetter
Expr
setattr(dask#11836) Florian JetterFollow up to expression tokenization caching (dask#11837) Florian Jetter
Consolidate
getattrfor expr classes (dask#11835) Florian JetterReduce pickle size of
ReadParquetexpression (dask#11797) Florian Jetterarangeloses precision on~2**63(dask#11801) Guido ImperialeRemove
numbaggfrom upstream build (dask#11821) Patrick HoeflerDispatch to
numbaggfornanmedianandnanquantile(dask#11817) Patrick HoeflerMake missing
metawarning more ergonomic (dask#11814) Patrick HoeflerRemove
namedoc fromfrom_pandas(dask#11812) Patrick HoeflerImplement an Array Scalar (dask#11810) Patrick Hoefler
Added
to_orcto DataFrame API (dask#11807) Tom AugspurgerImplement reverse indexing for DataFrames (dask#11803) Patrick Hoefler
Add lazy
to_pandas_dispatchregistration forcudf(dask#11799) Richard (Rick) ZamoraFix missing imports in array-expr (dask#11796) Florian Jetter
Cache tokens on expressions and restore after pickle roundtrip (dask#11791) Florian Jetter
Use random dashboard ports for
LocalClusterin distributed tests (dask#11795) Florian JetterImplement slicing for array-expr (dask#11783) Patrick Hoefler
Never use an asynchronous
Clientwhen calling top level compute function (dask#11790) Florian JetterRefactor import tests (dask#11794) Florian Jetter
Migrate
base.unpack_collectionstoTaskclass (dask#11793) Florian JetterEnsure
map_blocksgenerates unique tokens (dask#11792) Florian JetterSpeed up
normalize_pickleby 50 percent (dask#11788) Florian JetterFix divisions calculation with duplicates (dask#11787) Patrick Hoefler
Fix assign align for duplicated divisions (dask#11786) Patrick Hoefler
Ensure concat optimize project does not raise (dask#11784) Florian Jetter
Add array-expr from_array (dask#11772) Patrick Hoefler
Keep chunksizes consistent in
apply_gufunc(dask#11683) Patrick HoeflerTest
dask.dataframe.__all__(dask#11782) Philipp A.Add
__all__todask.bag(dask#11781) Philipp A.Add test for
dask.array.__all__(dask#11780) Philipp A.Bump
JamesIves/github-pages-deploy-actionfrom 4.7.2 to 4.7.3 (dask#11777)Export
dask.arraymembers (dask#11779) Philipp A.Fix
sorted_divisions_locationswith duplicates (dask#11773) Tom AugspurgerFix small typo in
best-practices.rst(dask#11775) Sergey KolesnikovAllow unknown chunks in
blockwiseadjust_chunks(dask#11769) Lindsey GrayFix crash in
asarray(..., like=...)vs.scipy.sparseobjects (dask#11755) Guido ImperialeRemove flaky optional dependency (dask#11771) Tom Augspurger
Add support for scipy sparray (dask#11750) Philipp A.
Added
flakyto tests extra (dask#11770) Tom AugspurgerEnsure divisions are plain scalars (dask#11767) Tom Augspurger
Remove divisions code duplication (dask#11764) Florian Jetter
Ensure divisions not diverging from
npartitionsin Merge (dask#11762) Florian JetterSkip
test_visualize_int_overflowon windows (dask#11761) Florian JetterReduce pickle size for tasks (dask#11687) Florian Jetter
Implement
unify_chunksand Rechunk (dask#11692) Patrick HoeflerFix expression getitem to avoid alignment (dask#11760) Patrick Hoefler
arange(..., like=x)embeds the graph of x (dask#11754) Guido ImperialeSimplify
assert_divisions(dask#11745) Florian JetterFix Projection logic for Series objects (dask#11747) Patrick Hoefler
Remove bytes as keys (dask#11757) Florian Jetter
Ensure
map_partitionsreturns Series object if function returns scalar (dask#11756) Florian JetterDon’t upload env twice (dask#11748) Patrick Hoefler
Fix badges in readme (distributed#9029) Florian Jetter
Properly forward cancellation reason (distributed#9028) Florian Jetter
Fix
bokehcircle (distributed#9026) Florian JetterEnsure
FileInfocan be serialized (distributed#9025) Florian JetterAdd ipykernel to skipped modules in code sampling (distributed#9022) Matthew Rocklin
SpecCluster: add option to not shut down the scheduler when the cluster is closed (distributed#9021) Taylor Braun-Jones
Fix CI by using
client.persist(collection)instead ofcollection.persist()(distributed#9020) Hendrik MakaitAdd redirect from prefix root to status (distributed#9015) Isaac
Bump
JamesIves/github-pages-deploy-actionfrom 4.7.2 to 4.7.3 (distributed#9018)Remove bytes keys from tests (distributed#9017) Jacob Tomlinson
2025.2.0#
Highlights#
This release includes a critical fix that fixes a deadlock that can arise when seceded task are rescheduled, or cancelled and resubmitted, e.g. due to a worker being lost.
See distributed#8991 by Hendrik Makait for more details.
Additional changes
Add big array example (dask#11744) James Bourbeau
Fix exploding chunksizes in pad for constant padding (dask#11743) Patrick Hoefler
Move optimize method to base class (dask#11742) Florian Jetter
Add changelog entry for fixed deadlock (dask#11741) Hendrik Makait
Fix graph creation in
dask-exprto_delayed(dask#11739) Patrick HoeflerRemove culling from delayed optimisation (dask#11737) Patrick Hoefler
Compute meta for from_map on the cluster (dask#11738) Patrick Hoefler
Bugs in
__setitem__with dask bool mask (dask#11728) Guido ImperialeImplement infrastructure, random, blockwise and Elemwise (dask#11689) Patrick Hoefler
array/asarraywith bothlike=anddtype=(dask#11733) Guido ImperialeFix annotations warnings test (dask#11734) Patrick Hoefler
Catch warnings when writing to remote storage with to_parquet (dask#11731) Patrick Hoefler
Remove LocalCluster from tests (dask#11729) Patrick Hoefler
Fix partition pruning when using from_array (dask#11725) Patrick Hoefler
Fix concatentation with mixed dtype columns (dask#11727) Patrick Hoefler
arange: fix extreme values (dask#11707) Guido ImperialeGraph corruption on scalar
getitem->setitem(dask#11723) Guido ImperialeNever share buffers after compute() (dask#11697) Guido Imperiale
Extract Dask Array from xarray DataArray in from_array (dask#11712) Patrick Hoefler
arange: support kwargs (dask#11710) Guido ImperialeEnsure
normalize_tokenis threadsafe (dask#11709) Florian JetterExpand advise for instance types and processes (dask#11705) Florian Jetter
Drop legacy timeseries implementation (dask#11704) Florian Jetter
Update Dask Cloud Provider documentation to include Nebius as a supported cloud option (dask#11703) Alexander
Fix
normalize_chunkswhen squashing into a single chunk (dask#11702) Patrick HoeflerFix positional indexing with
newaxis(dask#11699) Patrick HoeflerSet array backend in scipy-sparse-indexing (dask#11700) Tom Augspurger
Fix
value_countsshuffling strategy (dask#11698) Patrick HoeflerDisentangle core expression class from dataframe specific code (dask#11688) Patrick Hoefler
Bump
conda-incubator/setup-minicondafrom 3.1.0 to 3.1.1 (dask#11685)Fixup dataframe conversion from array methods (dask#11684) Patrick Hoefler
Remove remaining artifacts of
fastparquet(dask#11682) Patrick HoeflerRemove traceback from
sizeoffailure warning (distributed#9006) Jacob TomlinsonHotfix: Ignore negative occupancy (distributed#9012) Hendrik Makait
Remove expensive tokenization for key uniqueness check (distributed#9009) Patrick Hoefler
Fix CI for changes in
from_map(distributed#9011) Patrick HoeflerAvoid handling stale long-running messages on scheduler (distributed#8991) Hendrik Makait
Bump
test_stresstimeout (distributed#9002) Tom AugspurgerPoll in
test_rmm_metricstest (distributed#9004) Tom AugspurgerCache occupancy in
WorkStealing.balance()(distributed#9005) Hendrik MakaitHomogeneous balancing by accounting for in-flight requests (distributed#9003) Hendrik Makait
Consistent estimation of task duration between stealing, adaptive and occupancy calculation (distributed#9000) Hendrik Makait
Increase default work-stealing interval by 10x (distributed#8997) Hendrik Makait
Remove occupancy plot from status dashboard (distributed#8995) Hendrik Makait
Bump
conda-incubator/setup-minicondafrom 3.1.0 to 3.1.1 (distributed#8990)
2025.1.0#
Highlights#
Legacy Dask DataFrame Implementation removed#
This release drops the legacy Dask DataFrame implementation. The API with query planning is now the only available Dask DataFrame implementation.
This enforces the deprecation of the configuration:
dask.config.set({"dataframe.query-planning": False})
Dask-Expr was merged into the dask package as well as the dask/dask repository. It is no longer necessary to install dask-expr separately.
Reducing Memory Pressure for Xarray Workloads#
Dask introduced a mechanism that is called root task queuing in 2022. This mechanism allows Dask to detect tasks that are reading data from storage and schedule them defensively to avoid memory pressure on the cluster through overproduction of these tasks. The underlying mechanism was very fragile and failed for specific types of computations like opening multiple zarr stores or loading a large number of netcdf files.
The recent changes in Dask’s task graph representation allow for more robust detection of root tasks. This change makes the detection mechanism independent of the workload running and is especially beneficial for Xarray workloads.
This results in significantly more memory stability and a reduced memory footprint for workloads where root task detection was previously failing and makes the expected memory profile deterministic and independent of the topology of the task graph.
2024.12.1#
Highlights#
Improved scheduler responsiveness for large task graphs#
This release reduces the number of Python object references related to tracking tasks by the Dask scheduler. This increases scheduler responsiveness by reducing the time needed to run garbage collection on the scheduler.
See dask#8958, dask#11608, dask#11600, dask#11598, dask#11597, and distributed#8963 from Hendrik Makait for more details.
Additional changes
Fix
map_overlapbug where rechunking andtrim=Falsecaused inconsistent chunkings (dask#11605) Patrick HoeflerAvoid legacy implementation in read-csv (dask#11603) Patrick Hoefler
Remove legacy DataFrame import (dask#11604) Patrick Hoefler
asarrayignoresdtypefor array inputs (dask#11586) crusaderkyAdd back LLM chatbot to Dask docs (dask#11594) dchudz
Bump
JamesIves/github-pages-deploy-actionfrom 4.6.9 to 4.7.2 (dask#11593)Migrate dask array creation routines to task spec (dask#11582) James Bourbeau
Migrate most of dask array random to task spec (dask#11581) James Bourbeau
Do not use local function in
array.push(dask#11576) Florian JetterBump
conda-incubator/setup-minicondafrom 3.0.3 to 3.1.0 (distributed#8922)Pick random dashboard port in tests (distributed#8965) Hendrik Makait
Fix formatting for
NoValidWorkerExceptionmessage (distributed#8967) Hendrik MakaitSupport
pynvml>=11.5in WSL (distributed#8962) Richard (Rick) ZamoraBump
JamesIves/github-pages-deploy-actionfrom 4.6.9 to 4.7.2 (distributed#8960)
2024.12.0#
Highlights#
Python 3.13 Support#
This release adds support for Python 3.13. Dask now supports Python 3.10-3.13.
See dask#11456 and distributed#8904 from Patrick Hoefler and James Bourbeau for more details.
Additional changes
Revert “Add LLM chatbot to Dask docs (dask#11556)” (dask#11577) dchudz
Automatically rechunk if array in
to_zarrhas irregular chunks (dask#11553) Patrick HoeflerBlockwise uses
Taskclass (dask#11568) Florian JetterMigrate
rechunkandreshapeto task spec (dask#11555) Patrick HoeflerCache svg-representation for arrays (dask#11560) Deepak Cherian
Fix empty input for containers (dask#11571) Florian Jetter
Convert
Baggraphs toTaskSpecgraphs during optimization (dask#11569) Florian JetterAdd LLM chatbot to Dask docs (dask#11556) dchudz
Fuse data nodes in linear fusion too (dask#11549) Patrick Hoefler
Migrate slicing code to task spec (dask#11548) Patrick Hoefler
Speed up
ArraySliceDeptokenization (dask#11551) Patrick HoeflerFix fusing of
p2pbarrier tasks (dask#11543) Patrick HoeflerRemove infra/mentions of GPU CI (dask#11546) Charles Blackmon-Luca
Temporarily disable gpuCI update CI job (dask#11545) James Bourbeau
Use
BlockwiseDepto implementmap_blockskeywords (dask#11542) Patrick HoeflerRemove
optimize_slices(dask#11538) Patrick HoeflerMake
reshape_blockwisea noop if shape is the same (dask#11541) Patrick HoeflerRemove read-only flag from
open_arryinopen_zarr(dask#11539) Patrick HoeflerImplement
linear_fusionfor task spec class (dask#11525) Patrick HoeflerRemove recursion from
TaskSpec(dask#11477) Florian JetterFixup test after dask-expr change (dask#11536) Patrick Hoefler
Bump
codecov/codecov-actionfrom 3 to 5 (dask#11532)Create dask-expr frame directly without roundtripping (dask#11529) Patrick Hoefler
Add
scikit-imagenightly back to upstream CI (dask#11530) James BourbeauRemove
from_dask_dataframeimport (dask#11528) Patrick HoeflerEnsure that
from_arraycreates a copy (dask#11524) Patrick HoeflerSimplify and improve performance of normalize chunks (dask#11521) Patrick Hoefler
Fix flaky
nanquantiletest (dask#11518) Patrick HoeflerFix tests for new
read_onlykwarg inzarr=3(dask#11516) Patrick HoeflerFix
test_jupyter.py::test_shutsdown_cleanly(distributed#8954) Hendrik MakaitInstall
tornadofromconda-forgein Python 3.13 CI (distributed#8951) James BourbeauRestore retire workers API (distributed#8939) Florian Jetter
Properly convert finalize dependencies to references (distributed#8949) Hendrik Makait
Block fusion for barrier tasks (distributed#8944) Patrick Hoefler
Remove infra/mentions of GPUCI (distributed#8946) Charles Blackmon-Luca
Temporarily disable gpuCI update CI job (distributed#8945) James Bourbeau
Remove recursion in task spec (distributed#8920) Florian Jetter
Less verbose log messages for remove and register worker (distributed#8938) Florian Jetter
Do not log full worker info in
retire_workers(distributed#8935) Florian Jetter
2024.11.2#
Note
Versions 2024.11.0 and 2024.11.1 included a critical performance regression and should be skipped by every user.
Highlights#
Legacy Dask DataFrame Deprecated#
This release deprecates the legacy Dask DataFrame implementation. The old implementation will be removed completely in a future release. Users are encourage to switch to the new implementation now and to report any issues they are facing.
Users are also encourage to check that they are only importing functions from dask.dataframe
and not any of the submodules.
New quantile methods for Dask Array API#
Dask Array added new quantile and nanquantile methods.
Previously, Dask dispatched to the NumPy implementation, which blocked the GIL
a lot. This caused large slowdowns on workers with more than one tread and could lead
to runtimes over 200s per chunk.
The new quantile implementation avoids many of these problems and reduces runtime
to around 1s per chunk independently of the number of threads.
Consistent chunksize in Xarray rolling-construct#
Using Xarrays rolling(...).construct(...) with Dask Arrays led to very large
chunksizes that rarely fit into memory on a single worker.
The underlying operations is a view on the smaller NumPy array, but triggering a copy of the data will lead to very large memory usage.
import xarray as xr
import dask.array as da
arr = xr.DataArray(
da.ones((93504, 721, 1440), chunks=("auto", -1, -1)),
dims=["time", "lat", "longitude"],
) # Initial chunks are ~128 MiB
arr.rolling(time=30).construct("window_dim")
Previously
Individual chunks are exploding to 10 GiB, likely causing out of memory errors.
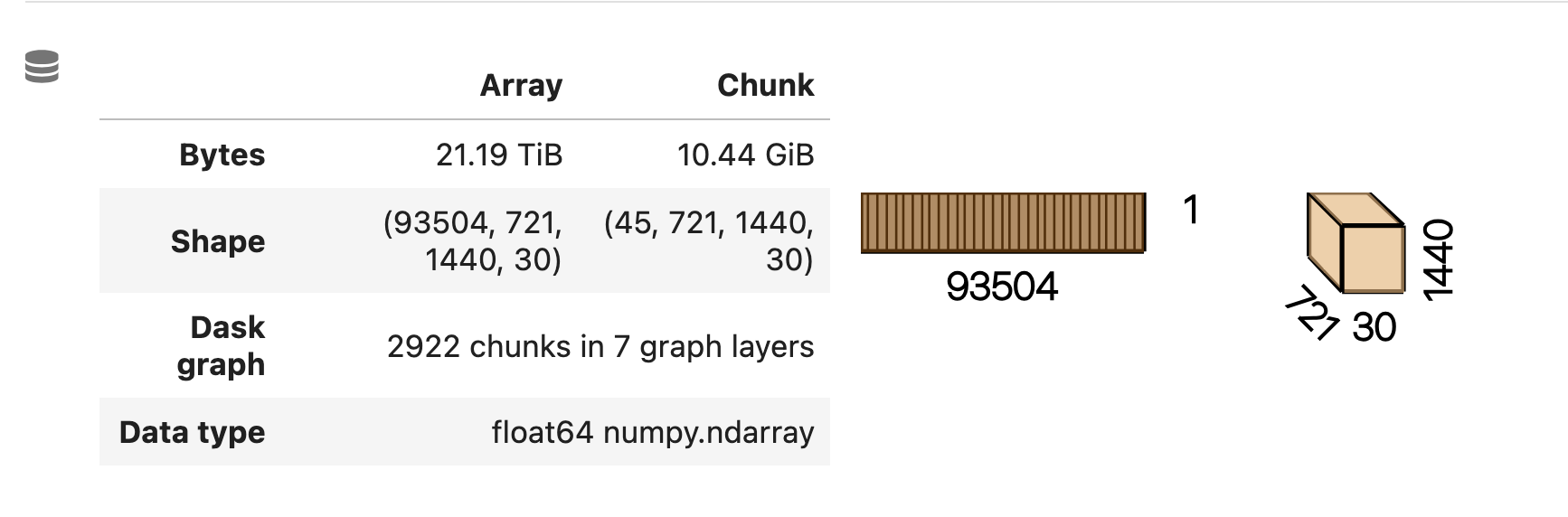
Now
Dask will now automatically split individual chunks into chunks that will have the same chunksize minus a small tolerance.

Improved efficiency of map overlap#
map_overlap now creates smaller and more efficient graphs to keep task graphs
generally a lot smaller.
The previous version injected a lot of tasks that weren’t necessary, increasing the number of tasks by a factor of 2-10x of what actually necessary. This caused a lot of stress on the scheduler.
Consistent chunksizes for Einstein summation#
Einstein summation historically led to very large chunksizes if applied to more than one Dask Array. This behavior is inherited from NumPy but led to out of memory errors on workers:
import dask.array as da
arr = da.random.random((1024, 64, 64, 64, 64), chunks=(256, 16, 16, 16, 16)) # Initial chunks are 128 MiB
result = da.einsum("aijkl,amnop->ijklmnop", arr, arr)
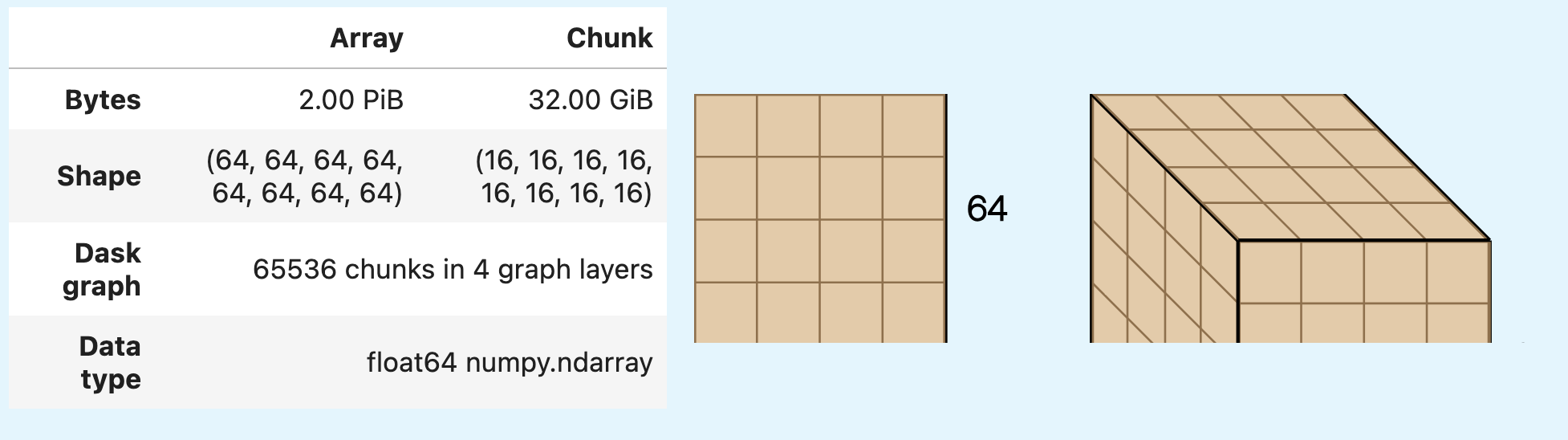
Previously
Individual chunks are exploding to 32 GiB, very likely causing out of memory errors.
Now
The operation keeps individual chunksizes the same.
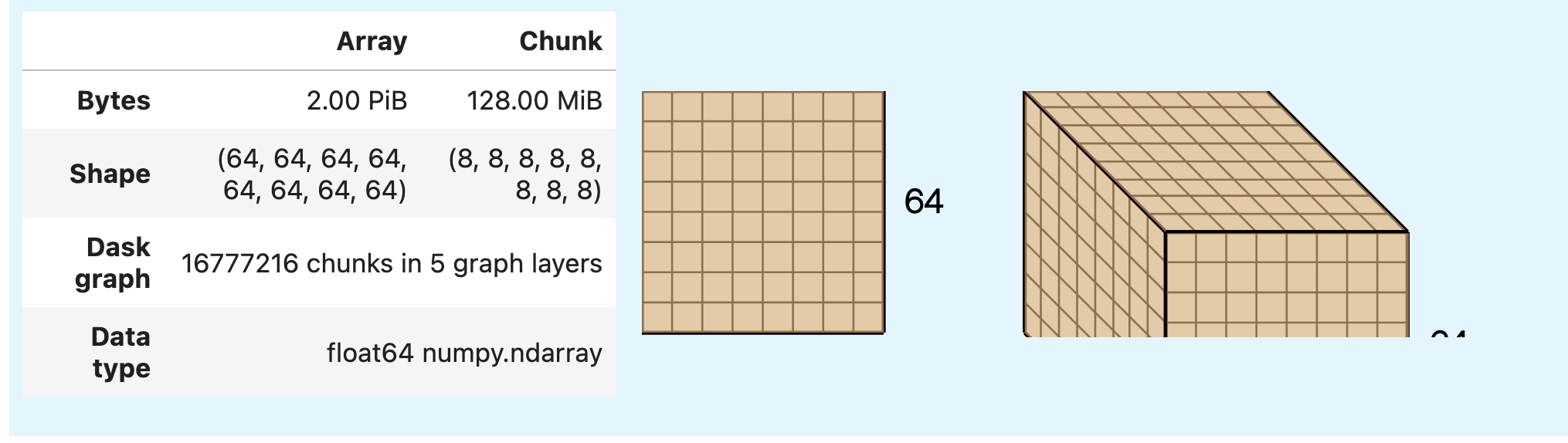
Additional changes
Add changelog for Dask release (dask#11502) Patrick Hoefler
Minor updates to optional dependencies table (dask#11503) James Bourbeau
Add
pushforffilllike operations (dask#11501) Patrick HoeflerRemove
funcpacking forTaskSpec(dask#11496) Florian JetterMake tokenization for
vindexmore efficient (dask#11493) Patrick HoeflerCut down runtime of einstein summation test (dask#11499) Patrick Hoefler
Improve test runtime for
test_rot90(dask#11498) Florian JetterDisable low level optimization for
TaskSpecin Bags (dask#11495) Florian JetterAdd automatic rechunking to sliding-window-view (dask#11479) Patrick Hoefler
Add
load_storedkwarg todask.array.store(dask#11465) Deepak CherianFix
quantileerror in two dimensions (dask#11489) Patrick HoeflerBump
conda-incubator/setup-minicondafrom 3.0.4 to 3.1.0 (dask#11490)Update
map_blocksdocstring (dask#11491) Patrick HoeflerFix
einsumwith empty arrays (dask#11488) Patrick HoeflerImplement non gil-blocking
quantilemethod (dask#11473) Patrick HoeflerUse internal keyword for trimming in
map_overlapto reduce graph size (dask#11486) Patrick HoeflerMinor dask
orderrefactor (dask#11467) Florian JetterRemove empty tasks from
map_overlap(dask#11483) Patrick HoeflerFixup auto chunks calculation if single chunk goes below 1 (dask#11485) Patrick Hoefler
Fix CI after pandas upstream changes (dask#11482) Patrick Hoefler
Make sure that
block_idandblock_infodon’t create extra tasks (dask#11484) Patrick HoeflerUse repeat to build nearest boundary (dask#9666) Jean-Baptiste Bayle
Remove dead code from
make_blockwise(dask#11478) Florian JetterPatch auto-chunks calculation for
rioxarray(dask#11480) Patrick HoeflerSkip legacy test because of flaky warning (dask#11475) Patrick Hoefler
Unskip a few
dask-exprtests (dask#11474) Patrick HoeflerKeep chunk sizes consistent in
einsum(dask#11464) Patrick HoeflerImprove how
normalize_chunkssquashes together chunks when “auto” is set (dask#11468) Patrick HoeflerFix
resolve_aliaseswhen multiple aliases are in graph (dask#11469) Patrick HoeflerAvoid cyclic import in
dask.array(dask#11472) Hendrik MakaitUnskip dataframe test (dask#11471) Patrick Hoefler
Improve
dask.orderperformance for large graphs (dask#11466) Florian JetterEnsure that
slice(None)just maps the keys (dask#11450) Patrick HoeflerFix
Task.__repr__()of unpickled object (dask#11463) Peter Andreas EntschevUse
TaskSpecin local dask execution (dask#11378) Florian JetterAdjust accuracy in
test_solve_triangular_vector(dask#11461) Florian JetterUpdate Aggregation docstring (dask#11459) Guillaume Eynard-Bontemps
Implement fuse option for
delayedobjects (dask#11441) Patrick HoeflerDeprecate legacy dask dataframe implementation (dask#11437) Patrick Hoefler
Fix
nacasting behavior forgroupby.aggwith arrow dtypes (dask#11118) Patrick HoeflerFix behavior of
keys_in_tasksforTaskSpecnodes (dask#11445) Florian JetterConvert dtype to int instead of np.uint8 for visualizing large task graphs (dask#11440) Patrick Hoefler
Ensure dependencies are not mutated (dask#11438) Florian Jetter
Full support for task spec in
dask.order(dask#11347) Florian JetterRemove redundant methods in
P2PBarrierTask(distributed#8924) Florian JetterFix
skipifcondition fortest_tell_workers_when_peers_have_left(distributed#8929) Florian JetterEnsure
ConnectionPoolis closed even if network stack swallowsCancelledErrors(distributed#8928) Florian JetterFix flaky
test_server_comms_mark_active_handlers(distributed#8927) Florian JetterMake assumption in P2P’s barrier mechanism explicit (distributed#8926) Hendrik Makait
Adjust timeouts in Jupyter cli test (distributed#8925) Florian Jetter
Add
stimulus_idtoupdate_graphplugin hook (distributed#8923) Hendrik MakaitReduce P2P transfer task overhead (distributed#8912) Hendrik Makait
Disable profiler on Python 3.11 (distributed#8916) Florian Jetter
Fix
test_restarting_does_not_deadlock(distributed#8849) Florian JetterAdjust
popentimeouts for testing (distributed#8848) Florian JetterAdd retry to shuffle broadcast (distributed#8900) Florian Jetter
Fix
test_shuffle_with_array_conversion(distributed#8909) Florian JetterRefactor some tests (distributed#8908) Florian Jetter
Graduate
dask-exprfrom contrib to core project (distributed#8911) Hendrik MakaitSkip
test_tell_workers_when_peers_have_lefton py10 (distributed#8910) Florian JetterInternal cleanup of P2P code (distributed#8907) Hendrik Makait
Use
Taskclass instead of tuple (distributed#8797) Florian JetterIncrease connect timeout for
test_tell_workers_when_peers_have_left(distributed#8906) Florian JetterRemove dispatching in
TaskCollection(distributed#8903) Florian JetterDeduplicate requests to scheduler in P2P (distributed#8899) Hendrik Makait
Add configurations for rootish taskgroup threshold (distributed#8898) Patrick Hoefler
2024.10.0#
Notable Changes#
Zarr-Python 3 compatibility (dask#11388)
Avoid exponentially increasing taskgraph in overlap (dask#11423)
Ensure numba tokenization does not use slow pickle path (dask#11419)
Additional changes
Ensure broadcast_shapes() returns integers, not NumPy scalars. (dask#11434) Martin Yeo
(fix): sparse indexing (dask#11430) Ilan Gold
Ensure that recursively calling tokenize respects ensure_deterministic (dask#11431) Florian Jetter
Make P2P more configurable (distributed#8469) Hendrik Makait
Fit Dashboard worker table to page width (distributed#8897) Jacob Tomlinson
Raise helpful error when using the wrong plugin base classes (distributed#8893) Jacob Tomlinson
Fix url escaping on exceptions dashboard for non-string keys (distributed#8891) Patrick Hoefler
Add meaningful error for out of disk exception during write (distributed#8886) Hendrik Makait
Fix binary operations with scalar on the left (dask-expr#1150) Patrick Hoefler
Raise exception when calculating divisons (dask-expr#1149) Patrick Hoefler
Fix merge_asof for single partition (dask-expr#1145) Patrick Hoefler
Improve handling of optional dependencies in analyze and explain (dask-expr#1146) Hendrik Makait
Fix alignment issue with groupby index accessors (dask-expr#1142) Patrick Hoefler
Fix displaying timestamp scalar (dask-expr#1141) Patrick Hoefler
2024.9.1#
Highlights#
Improved adaptive scaling resilience#
Adaptive scaling clusters now recover from spurious errors during scaling.
See distributed#8871 by Hendrik Makait for more details.
Additional changes
Improve error message for incorrect columns order in meta information (dask#11393) Dmitry Balabka
Update gpuCI
RAPIDS_VERto24.12(dask#11407)Bump
jacobtomlinson/gha-anaconda-package-versionfrom 0.1.3 to 0.1.4 (dask#11405)Switch to using
zarr.open_arrayinstead of using thezarr.Arrayconstructor (dask#11387) Joe HammanUpdate gpuCI
RAPIDS_VERto24.12(distributed#8879)Don’t consider scheduler idle while executing
Scheduler.update_graph(distributed#8877) Hendrik MakaitBump
jacobtomlinson/gha-anaconda-package-versionfrom 0.1.3 to 0.1.4 (distributed#8878)Support P2P rechunking datetime arrays (distributed#8875) James Bourbeau
2024.9.0#
Highlights#
Bump Bokeh minimum version to 3.1.0#
bokeh>=3.1.0 is now required for diagnostics and the distributed cluster dashboard.
See dask#11375 and distributed#8861 by James Bourbeau for more details.
Introduce new Task class#
Add a Task class to replace tuples for task specification.
See dask#11248 by Florian Jetter for more details.
Additional changes
Bump
peter-evans/create-pull-requestfrom 6 to 7 (dask#11380)Reduce overhead in tokenize (dask#11373) Florian Jetter
Move
tokenizeto dedicated submodule (dask#11371) Florian JetterEnsure
process_runnablesis not too eager in the presence of multiple splits (dask#11367) Florian JetterUse
np.min_scalar_typein shuffle (dask#11369) James BourbeauWrite indexing arrays into dask graph to reduce size for multiple xarray variables (dask#11362) Patrick Hoefler
Cast indexer to minimal
dtypein shuffle (dask#11364) Patrick HoeflerReduce memory usage of
dask.order(dask#11361) Florian JetterBump
JamesIves/github-pages-deploy-actionfrom 4.6.3 to 4.6.4 (dask#11366)precommitautoupdate (dask#11360) Florian JetterHomogeneously schedule P2P’s unpack tasks (distributed#8873) Hendrik Makait
Work/fix firewall for localhost (distributed#8868) Mario Linker
Use new
tokenizemodule (distributed#8858) James BourbeauPoint to user code with idempotent plugin warning (distributed#8856) James Bourbeau
Fix test nanny timeout (distributed#8847) Florian Jetter
Bump JamesIves/github-pages-deploy-action from 4.5.0 to 4.6.4 (distributed#8853)
Speed up
Client.mapby computingtokenonly once forfuncandkwargs(distributed#8855) Florian JetterUpdate
pre-commit(distributed#8852) Florian Jetter
2024.8.2#
Highlights#
Automatic selection of rechunking method#
To enable users to rechunk data at larger scales than before, Dask now automatically chooses an appropriate rechunking method when rechunking on a cluster. This requires no additional configuration and is enabled by default.
Specifically, Dask chooses between task-based and P2P rechunking. While task-based rechunking has been the previous default, P2P rechunking is beneficial when rechunking requires almost all-to-all communication between the old and new chunks, e.g., when changing between spacial and temporal chunking. In these cases, P2P rechunking offers constant memory usage and creates smaller task graphs. As a result, it works for cases where tasks-based rechunking would have previously failed.
To disable automatic selection, users can select their preferred method via the configuration
import dask.config
# Choose either "tasks" or "p2p"
dask.config.set({"array.rechunk.method": "tasks"})
or when rechunking
import dask.array as da
arr = da.random.random(size=(1000, 1000, 365), chunks=(-1, -1, "auto"))
# Choose either "tasks" or "p2p"
arr = arr.rechunk(("auto", "auto", -1), method="tasks")
See dask#11337 by Hendrik Makait for more details.
New shuffle API for Dask Arrays#
Dask added a shuffle-API to Dask Arrays. This API allows for shuffling the data
along a single dimension. It will ensure that every group of elements along this
dimension are in exactly one chunk. This is a very useful operation for GroupBy-Map
patterns in Xarray. See shuffle() for more information
and API signature.
See dask#11267, dask#11311 and dask#11326 by Patrick Hoefler for more details.
New blockwise_reshape API for Dask Arrays#
The new blockwise_reshape() enables an embarassingly parallel
reshaping operation for cases where you don’t care about the order of the underlying
array. It is embarassingly parallel and doesn’t trigger a rechunking operation
under the hood anymore. This is useful when you don’t care about the order of
the resulting Array, i.e. if a reduction is applied to the array or if the reshaping
is only temporary.
arr = da.random.random(size=(100, 100, 48_000), chunks=(1000, 100, 83)
result = reshape_blockwise(arr, (10_000, 48_000))
result.sum()
# or: do something that preserves the shape of each chunk
result = reshape_blockwise(result, (100, 100, 48_000), chunks=arr.chunks)
Dask will automatically calculate the resulting chunks if the number of dimensions is reduced, but you have to specify the resulting chunks if the number of dimensions is increased.
Reshaping a Dask Array oftentimes creates a very complicated computations with rechunk
operations in between because Dask respect the C ordering of the Array by default. This
ensures that the resulting Dask Array is returned in the same order as the
corresponding NumPy Array. However, this can lead to very inefficient computations.
The blockwise_reshape is a lot more efficient than the default implemenation
if you don’t care about the order.
Warning
Blockwise reshape operations are more efficient as the default, but they will return an Array that is ordered differently. Use with care!
See dask#11328 by Patrick Hoefler for more details.
Mutlidimensional positional indexing keeping chunksizes consistent#
Indexing a Dask Array with vindex() previously created a single
output chunk along the dimensions that were indexed. vindex is commonly used in Xarray
when indexing multiple dimensions in a single step, i.e.:
arr = xr.DataArray(
da.random.random((100, 100, 100), chunks=(5, 5, 50)),
dims=['a', "b", "c"],
)
Previously, this put the indexed dimensions into a single chunk:

Dask now uses an improved algorithm that ensures that the chunksizes are kept consistent:

See dask#11330 by Patrick Hoefler for more details.
Additional changes
Add changelog entries for shuffle,
vindexandblockwise_reshape(dask#11350) Patrick HoeflerEnsure persisted collections are released without GC (dask#11348) Florian Jetter
Update zoom link for dask meeting (dask#11357) Sarah Charlotte Johnson
Add more docstring examples for
normalize_chunks(dask#11271) IllviljanChoose automatically between tasks-based and p2p rechunking (dask#11337) Hendrik Makait
Implement blockwise reshaping API for arrays (dask#11328) Patrick Hoefler
Make rechunking in shuffle more intelligent to distribute unevenly if necessary (dask#11326) Patrick Hoefler
Increase visibility of GPU CI updates (dask#11345) Charles Blackmon-Luca
Update
numpyandpyarrowversions in install docs (dask#11340) James BourbeauFixup dask and distributed dependencies (dask#11338) Patrick Hoefler
Bump
numpy>=1.24andpyarrow>=14.0.1minimum versions (dask#11331) James BourbeauAdd
crickback to Python 3.11+ CI builds (dask#11335) James BourbeauPreserve chunksizes in
vindex(dask#11330) Patrick HoeflerFix
dask.array.fftmismatch with Numpy’s interface (add support for norm argument) (dask#10665) joanruePass additional parameters to
rechunk_p2p(dask#11319) Hendrik MakaitFix docstring formatting for
map_overlap(dask#11332) Tao XinFix NumPy overflowing for
prodon 2.0 (dask#11327) Patrick HoeflerEnsure
axesare positive / add tests for negative axes (dask#10812) joanrueFix
map_overlapwithnew_axis(dask#11128) David StansbyAvoid capturing code of
xdist(distributed#8846) Florian JetterReduce memory footprint of culling P2P rechunking (distributed#8845) Hendrik Makait
Add tests for choosing default rechunking method (distributed#8843) Hendrik Makait
Increase visibility of GPU CI updates (distributed#8841) Charles Blackmon-Luca
Bump
test_pause_while_idletimeout (distributed#8844) Florian JetterConcatenate small input chunks before P2P rechunking (distributed#8832) Hendrik Makait
Remove dump cluster from
gen_cluster(distributed#8823) Florian JetterBump
numpy>=1.24andpyarrow>=14.0.1minimum versions (distributed#8837) James BourbeauFix
PipInstallplugin onWorker(distributed#8839) Hendrik MakaitRemove more Python 3.10 compatibility code (distributed#8824) James Bourbeau
Use task-based rechunking to prechunk along partial boundaries (distributed#8831) Hendrik Makait
Ensure
client_desires_keysdoes not corruptSchedulerstate (distributed#8827) Florian JetterBump minimum
cloudpickleto 3 (distributed#8836) James Bourbeau
2024.8.1#
Highlights#
Improve output chunksizes for reshaping Dask Arrays#
Reshaping a Dask Array oftentimes squashed the dimensions to reshape into a single chunk. This caused very large output chunks and subsequently a lot of out of memory errors and performance issues.
arr = da.ones(shape=(1000, 100, 48_000), chunks=(1000, 100, 83))
arr.reshape(1000, 100, 4, 12_000)
Previously, this put the last dimension into a single chunk of size 12_000.

The new algorithm will ensure that the chunk-size between in- and output is kept the same. This will avoid large increases in chunk-size and fragmentation of chunks.

Improve scheduling efficiency for Xarray Rechunk-GroupBy-Reduce patterns#
The scheduler previously created an inefficient execution graph for Xarray GroupBy-Reduction patterns that use the cohorts strategy:
import xarray as xr
arr = xr.open_zarr(...)
arr.chunk(time=TimeResampler("ME")).groupby("time.month").mean()
An issue in the algorithm that creates the execution order of the task graph lead to an inefficient execution strategy that accumulates a lot of unnecessary memory on the cluster. The improvement is very similar to the previous ordering improvement in 2024.08.0.
Drop support for Python 3.9#
This release drops support for Python 3.9 in accordance with NEP 29. Python 3.10 is now the required minimum version to run Dask.
See dask#11245 and distributed#8793 by Patrick Hoefler for more details.
Additional changes
Ensure
pickledoes not change tokens (dask#11320) Florian JetterAdd changelog entry for
reshapeand ordering improvements (dask#11324) Patrick HoeflerRename
chunksize-toleranceoption (dask#11317) Patrick HoeflerUpgrade gpuCI and fix Dask Array failures with “cupy” backend (dask#11309) Richard (Rick) Zamora
Implement automatic rechunking for
shuffle(dask#11311) Patrick HoeflerEnsure we test against
numpy2 in CI (dask#11182) James BourbeauRevert “Test ordering on distributed scheduler (dask#11310)” (dask#11321) Florian Jetter
Test ordering on distributed scheduler (dask#11310) Florian Jetter
Add tests to cover more cases of new
reshapeimplementation (dask#11313) Patrick HoeflerOrder: Choose better target for branches with multiple leaf nodes (dask#11303) Patrick Hoefler
Order: Ensure runnable tasks are certainly runnable (dask#11305) Florian Jetter
Fix upstream
numpybuild (dask#11304) Patrick HoeflerMake
shufflea no-op if possible (dask#11291) Patrick HoeflerKeep
chunksizeconsistent inreshape(dask#11273) Patrick HoeflerEnable slicing with only one unknown chunk (dask#11301) Patrick Hoefler
Link to
daskvssparkbenchmarks on Dask docs (dask#11289) Sarah Charlotte JohnsonFix slicing for masked arrays (dask#11300) Patrick Hoefler
Array: fix
asarrayfor array input withdtype(dask#11288) Lucas ColleyAdd
numpyconstants to array api (dask#11287) Lucas ColleyIgnore typing of return value (dask#11286) Patrick Hoefler
Remove automatic resizing in reshape (dask#11269) Patrick Hoefler
API: expose
npdtypes indask.arraynamespace (dask#11178) Lucas ColleyReduce frequency of unmanaged memory use warning (distributed#8834) Patrick Hoefler
Update gpuCI
RAPIDS_VERto24.10(distributed#8786)Avoid
RuntimeError: dictionary changed size during iterationinServer._shift_counters()(distributed#8828) Hendrik MakaitImprove concurrent close for scheduler (distributed#8829) Hendrik Makait
MINOR: Extract truncation logic out of partial concatenation in P2P rechunking (distributed#8826) Hendrik Makait
avoid excessive attribute access overhead for
remove_from_task_prefix_count(distributed#8821) Florian JetterAvoid key validation if validation is disabled (distributed#8822) Florian Jetter
Log
worker_clientevent (distributed#8819) James Bourbeau
2024.8.0#
Highlights#
Improve efficiency and performance of slicing with positional indexers#
Performance improvement for slicing a Dask Array with a positional indexer. Random access patterns are now more stable and produce easier-to-use results.
x[slice(None), [1, 1, 3, 6, 3, 4, 5]]
Using a positional indexer was previously prone to drastically increasing the number of output chunks and generating a very large task graph. This has been fixed with a more efficient algorithm.
The new algorithm will keep the chunk-sizes along the axis that is indexed the same to avoid fragmentation of chunks or a large increase in chunk-size.
See dask#11262 and dask#11267 by Patrick Hoefler for more details and performance benchmarks.
Improve scheduling efficiency for Xarray GroupBy-Reduce patterns#
The scheduler previously created an inefficient execution graph for Xarray GroupBy-Reduction patterns like:
import xarray as xr
arr = xr.open_zarr(...)
arr.groupby("time.month").mean()
An issue in the algorithm that creates the execution order of the task graph lead to an inefficient execution strategy that accumulates a lot of unneceessary memory on the cluster.
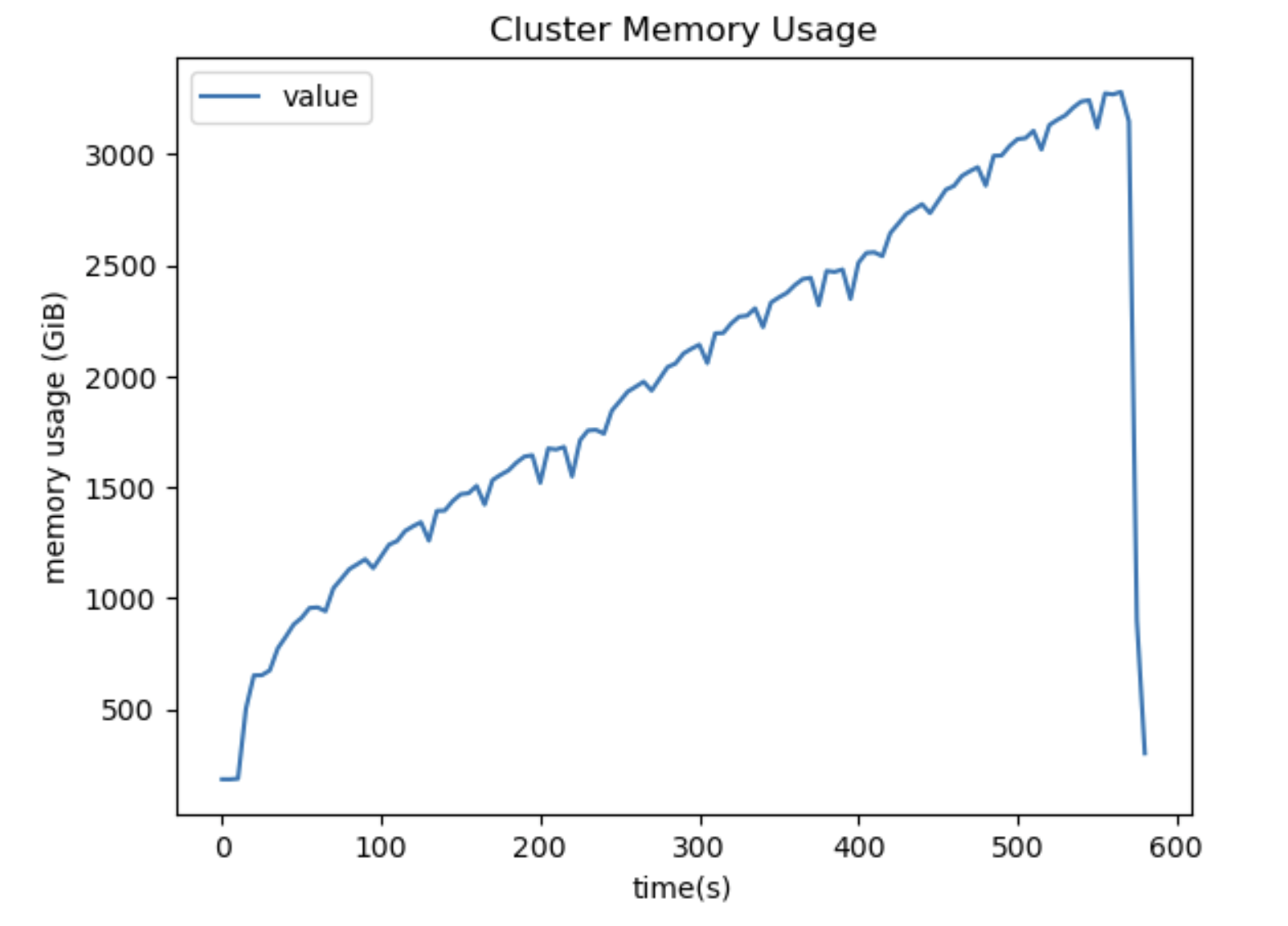
The operation itself is embarassingly parallel. Using the proper execution strategy the scheduler can now execute the operation with constant memory, avoiding spilling and allowing us to scale to larger datasets.
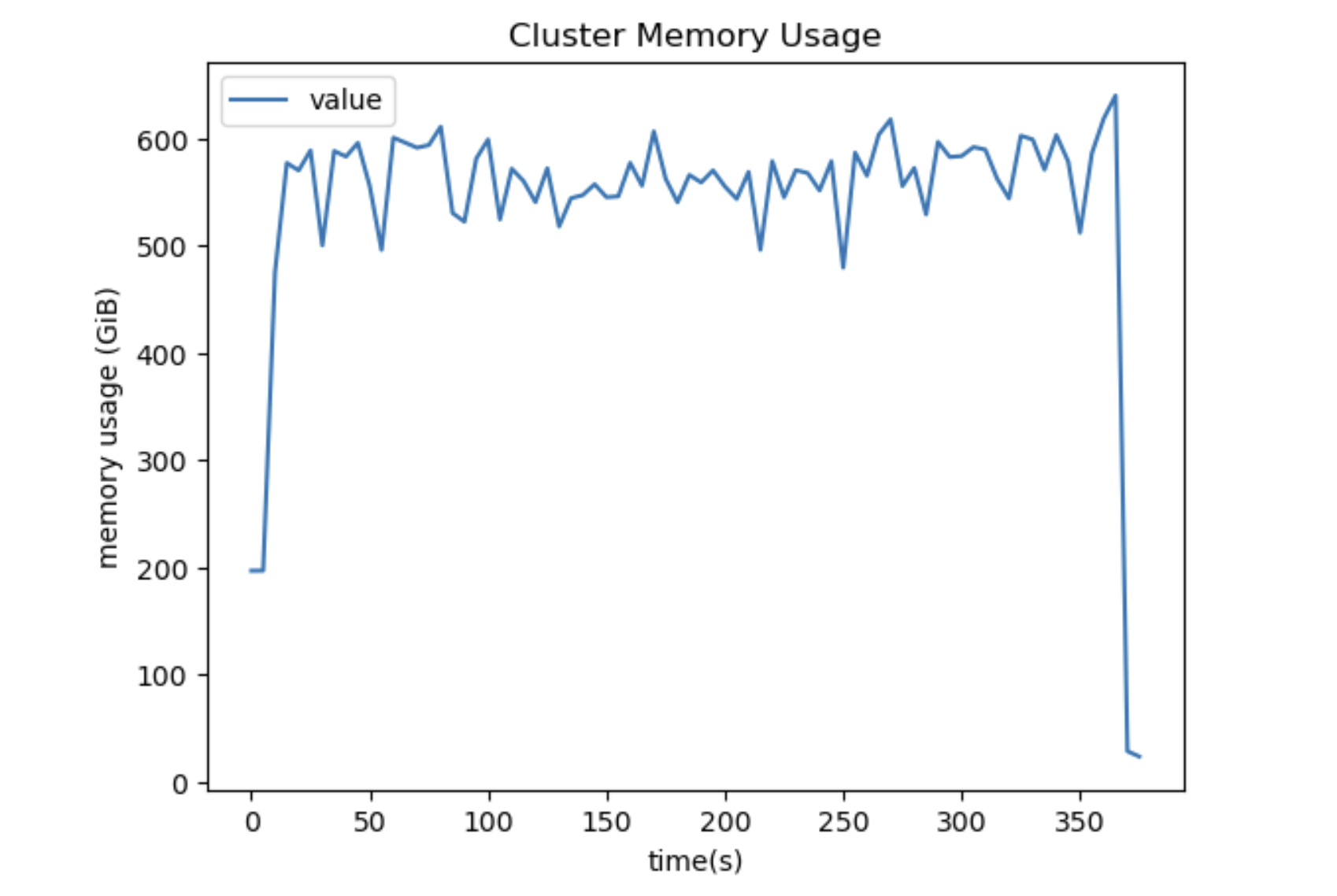
See distributed#8818 by Patrick Hoefler for more details and examples.
Additional changes
Add changelog for dask order patch (dask#11278) Patrick Hoefler
Add regression test for
xarraymap reduce (dask#11277) Florian JetterAdd changelog entry for
take(dask#11274) Patrick HoeflerRevert “order: remove data task graph normalization” (dask#11276) Patrick Hoefler
Use the shuffle algorithm for
take(dask#11267) Patrick HoeflerImplement task-based array shuffle (dask#11262) Patrick Hoefler
Remove data task graph normalization (dask#11263) Florian Jetter
Update zoom link for monthly meeting (dask#11265) Sarah Charlotte Johnson
Update data loading section of best practices (dask#11247) Patrick Hoefler
Match default
chunksizein docstring to actual default set in code (dask#11254) Bernhard RamlFixup casting error in
pandas3 (dask#11250) Patrick HoeflerSkip new warning from
pandas(dask#11249) Patrick HoeflerFix
pandasnightly bugs (dask#11244) Patrick HoeflerRun graph normalisation after dask order (distributed#8818) Patrick Hoefler
Update large graph size warning to remove scatter recommendation (distributed#8815) Patrick Hoefler
Fail tasks exceeding
no-workers-timeout(distributed#8806) Hendrik MakaitFix exception handling for
NannyPlugin.setupandNannyPlugin.teardown(distributed#8811) Hendrik MakaitFix exception handling for
WorkerPlugin.setupandWorkerPlugin.teardown(distributed#8810) Hendrik Makaittypo fix (distributed#8812) alex-rakowski
Fix
if/elseforsend_recv_from_rpc(distributed#8809) Patrick HoeflerEnsure that adaptive only stops once (distributed#8807) Hendrik Makait
Reduce noise from GC-related logging (distributed#8804) Hendrik Makait
Remove unused
delete_intervalandsynchronize_worker_intervalfromScheduler(distributed#8801) Hendrik MakaitChange log level for Compute Failed log message (distributed#8802) Patrick Hoefler
Add Prometheus metric for time spent on GC (distributed#8803) Hendrik Makait
Add Prometheus metrics for
dask_worker_{added|removed}_total(distributed#8798) Hendrik MakaitAdd log event for
worker-ttl-timed-out(distributed#8800) Hendrik MakaitAdd Prometheus metrics for
dask_client_connections_{added|removed}_total(distributed#8799) Hendrik MakaitFix
PackageInstallplugin (distributed#8794) Hendrik MakaitMake stealing more robust (distributed#8788) Hendrik Makait
Leave a warning about future instantiation (distributed#8782) Florian Jetter
2024.7.1#
Highlights#
More resilient distributed lock#
distributed.Lock is now resilient to worker failures.
Previously deadlocks were possible in cases where a lock-holding worker
was lost and/or failed to release the lock due to an error.
See distributed#8770 by Florian Jetter for more details.
Additional changes
Remove and warn of persist usage (dask#11237) Patrick Hoefler
Preserve
timestampunit duringmetacreation (dask#11233) Patrick HoeflerEnsure that
dask-exprDataFramesare optimized when put intodelayed(dask#11231) Patrick HoeflerFixes for
dfreq deprecation inpandas=3(dask#11228) James Bourbeaubump approx threshold for
test_quantile(dask#10720) Florian JetterBump
xarray-contrib/issue-from-pytest-logfrom 1.2.8 to 1.3.0 (dask#11221)Bump
JamesIves/github-pages-deploy-actionfrom 4.6.1 to 4.6.3 (dask#11222)Ensure
Lockalways register with scheduler (distributed#8781) Florian JetterTemporarily pin
setuptools < 71(distributed#8785) James BourbeauRestore
len()onTaskPrefix(distributed#8783) Hendrik MakaitAvoid false positives for
p2p-failedlog event (distributed#8777) Hendrik MakaitExpose paused and retired workers separately in prometheus (distributed#8613) Patrick Hoefler
Creating transitions-failures log event (distributed#8776) alex-rakowski
Implement HLG layer for P2P rechunking (distributed#8751) Hendrik Makait
Add another test for a possible deadlock scenario caused by (distributed#8703) (distributed#8769) Hendrik Makait
Raise an error if compute on persisted collection with released futures (distributed#8764) Florian Jetter
Re-raise
P2PConsistencyErrorfrom failed P2P tasks (distributed#8748) Hendrik MakaitRobuster faster tests memory sampler (distributed#8758) Florian Jetter
Fix
scheduler_bokeh::test_shuffling(distributed#8766) Florian JetterIncrease timeouts for
pubsub::test_client_worker(distributed#8765) Florian JetterFactor out async taskgroup (distributed#8756) Florian Jetter
Don’t sort keys lexicographically in worker table (distributed#8753) Florian Jetter
Use
functools.cacheinstead offunctools.lru_cachefor extremely often called functions (distributed#8762) Jonas DeddenRobuster deeply nested structures (distributed#8730) Florian Jetter
Adding HLG to MAP (distributed#8740) alex-rakowski
Add close worker button to worker info page (distributed#8742) James Bourbeau
2024.7.0#
Highlights#
Drop support for pandas 1.x#
This release drops support for pandas<2. pandas 2.0
is now the required minimum version to run Dask DataFrame.
The mimimum version of partd was also raised to 1.4.0. Versions before 1.4
are not compatible with pandas 2.
See dask#11199 by Patrick Hoefler for more details.
Publish-subscribe APIs deprecated#
distributed.Pub and distributed.Sub have been deprecated and will be removed
in a future release. Please switch to distributed.Client.log_event() and distributed.Worker.log_event()
instead.
See distributed#8724 by Hendrik Makait for more details.
Additional changes
Only count data that is in memory for
xarraysizeof(dask#11206) Florian JetterFix
botocorere-raising error (dask#11209) Patrick HoeflerUpdate Coiled links in documentation (dask#11211) Sarah Charlotte Johnson
Add some array-expr methods (dask#11210) Patrick Hoefler
Fix
quantilefor arrow dtypes (dask#11202) Patrick HoeflerAdd utility to verify optional dependencies (dask#11205) Patrick Hoefler
Implement array expression switch (dask#11203) Patrick Hoefler
Remove no longer supported
ipythonreference (dask#11196) Patrick HoeflerRemove
from_delayedreferences (dask#11195) Patrick HoeflerAdd other IO connectors to docs (dask#11189) Patrick Hoefler
Fix
assert_eqimport fromcudf(distributed#8747) James BourbeauLog traceback upon task error (distributed#8746) Hendrik Makait
Update system monitor when polling Prometheus metrics (distributed#8745) Hendrik Makait
Bump
pandasto 2.0 inmindepsbuild (distributed#8743) James BourbeauRefactor event logging functionality into broker (distributed#8731) Hendrik Makait
Drop support for pandas 1.X (distributed#8741) Hendrik Makait
Remove
is_python_shutting_down(distributed#8492) Hendrik MakaitFix
test_task_state_instance_are_garbage_collected(distributed#8735) Hendrik MakaitFix floating-point inaccuracy (distributed#8736) Hendrik Makait
Fix
pynvmlhandles (distributed#8693) Benjamin Zaitlenget_ip: handle getting0.0.0.0(distributed#8712) Adam WilliamsonRemove
FutureWarningintest_task_state_instance_are_garbage_collected(distributed#8734) Hendrik MakaitFix
mindeps-testing on CI (distributed#8728) Hendrik MakaitExtract tests related to event-logging into separate file (distributed#8733) Hendrik Makait
Use safer context for
ProcessPoolExecutor(distributed#8715) Elliott Sales de AndradeCache URL encoding of worker addresses in dashboard (distributed#8725) Florian Jetter
More robust
bokehtest_shuffling(distributed#8727) Florian JetterFix type in actor docs (distributed#8711) Sultan Orazbayev
More useful warning if a plugin type is provided instead of instance (distributed#8689) Florian Jetter
Improve error on cancelled tasks due to disconnect (distributed#8705) Hendrik Makait
Fix wait condition on
test_forget_errors(distributed#8714) Elliott Sales de AndradeSkip
test_deadlock_dependency_of_queued_released(distributed#8723) Hendrik MakaitFix
test_quiet_client_close(distributed#8722) Hendrik MakaitFix cleanup iteration in
save_sys_modules(distributed#8713) Elliott Sales de AndradeAdd quotes to missing
bokehinstallation commands (distributed#8717) James Bourbeau
2024.6.2#
This is a patch release to update an issue with dask and distributed
version pinning in the 2024.6.1 release.
Additional changes
Get docs build passing (dask#11184) James Bourbeau
profile._f_lineno: handlenext_linebeingNonein Python 3.13 (dask#8710) Adam Williamson
2024.6.1#
Highlights#
This release includes a critical fix that fixes a deadlock that can arise when dependencies of root-ish tasks are rescheduled, e.g. due to a worker being lost.
See distributed#8703 by Hendrik Makait for more details.
Additional changes
Cache global query-planning config (dask#11183) Richard (Rick) Zamora
Python 3.13 fixes (dask#11185) Adam Williamson
Fix
test_map_freq_to_period_startforpandas=3(dask#11181) James BourbeauBump release-drafter/release-drafter from 5 to 6 (distributed#8699)
2024.6.0#
Highlights#
memmap array tokenization#
Tokenizing memmap arrays will now avoid materializing the array into memory.
See dask#11161 by Florian Jetter for more details.
Additional changes
Fix
test_dt_accessorwith query planning disabled (dask#11177) James BourbeauUse
packaging.version.Version(dask#11171) James BourbeauRemove deprecated
dask.compatibilitymodule (dask#11172) James BourbeauEnsure compatibility for
xarray.NamedArray(dask#11168) Hendrik MakaitEstimate sizes of
xarraycollections (dask#11166) Florian JetterAdd section about futures and variables (dask#11164) Florian Jetter
Update docs for combined Dask community meeting info (dask#11159) Sarah Charlotte Johnson
Avoid rounding error in
test_prometheus_collect_count_total_by_cost_multipliers(distributed#8687) Hendrik MakaitLog key collision count in
update_graphlog event (distributed#8692) Hendrik MakaitAutomate GitHub Releases when new tags are pushed (distributed#8626) Jacob Tomlinson
Fix log event with multiple topics (distributed#8691) Hendrik Makait
Rename
safetoexpectedinScheduler.remove_worker(distributed#8686) Hendrik MakaitLog event during failure (distributed#8663) Hendrik Makait
Eagerly update aggregate statistics for
TaskPrefixinstead of calculating them on-demand (distributed#8681) Hendrik MakaitImprove graph submission time for P2P rechunking by avoiding unpack recursion into indices (distributed#8672) Florian Jetter
Add safe keyword to
remove-workerevent (distributed#8647) alex-rakowskiImproved errors and reduced logging for P2P RPC calls (distributed#8666) Hendrik Makait
Adjust P2P tests for
dask-expr(distributed#8662) Hendrik MakaitIterate over copy of
Server.digests_total_since_heartbeatto avoidRuntimeError(distributed#8670) Hendrik MakaitLog task state in Compute Failed (distributed#8668) Hendrik Makait
Add Prometheus gauge for task groups (distributed#8661) Hendrik Makait
Fix too strict assertion in shuffle code for
pandassubclasses (distributed#8667) Joris Van den BosscheReduce noise from erring tasks that are not supposed to be running (distributed#8664) Hendrik Makait
2024.5.2#
This release primarily contains minor bug fixes.
Additional changes
Fix nightly Zarr installation in CI (dask#11151) James Bourbeau
Add python 3.11 build to GPU CI (dask#11135) Charles Blackmon-Luca
Update gpuCI
RAPIDS_VERto24.08(dask#11141)Update
test_groupby_grouper_dispatch(dask#11144) Richard (Rick) ZamoraBump
JamesIves/github-pages-deploy-actionfrom 4.6.0 to 4.6.1 (dask#11136)Unskip
test_array_function_sparsewith newsparserelease (dask#11139) James BourbeauFix
test_parse_dates_multi_columnonpandas=3(dask#11132) James BourbeauDon’t draft release notes for tagged commits (dask#11138) Jacob Tomlinson
Reduce task group count for partial P2P rechunks (distributed#8655) Hendrik Makait
Update gpuCI
RAPIDS_VERto24.08(distributed#8652)Submit collections metadata to scheduler (distributed#8612) Florian Jetter
Fix indent in code example in
task-launch.rst(distributed#8650) Ray BellAvoid multiple
WorkerStatesphinx error (distributed#8643) James Bourbeau
2024.5.1#
Highlights#
NumPy 2.0 support#
This release contains compatibility updates for the upcoming NumPy 2.0 release.
See dask#11096 by Benjamin Zaitlen and dask#11106 by James Bourbeau for more details.
Increased Zarr store support#
This release contains adds support for MutableMapping-backed Zarr stores like
zarr.storage.DirectoryStore, etc.
See dask#10422 by Greg M. Fleishman for more details.
Additional changes
Minor updates to ML page (dask#11129) James Bourbeau
Skip failing
sparsetest on 0.15.2 (dask#11131) James BourbeauMake sure nightly
pyarrowis installed in upstream CI build (dask#11121) James BourbeauAdd initial draft of ML overview document (dask#11114) Matthew Rocklin
Test query-planning in gpuCI (dask#11060) Richard (Rick) Zamora
Avoid
pytesterror when skipping NumPy 2.0 tests (dask#11110) James BourbeauUse nightly
h5pyin upstream CI build (dask#11108) James BourbeauUse nightly
scikit-imagein upstream CI build (dask#11107) James BourbeauBump
actions/checkoutfrom 4.1.4 to 4.1.5 (dask#11105)Enable parquet append tests after fix (dask#11104) Patrick Hoefler
Skip
fastparquettests fornumpy2 (dask#11103) Patrick HoeflerFix misspelling found by codespell (dask#11097) Dimitri Papadopoulos Orfanos
Fix doc build (dask#11099) Patrick Hoefler
Clean up
percentiles_summarylogic (dask#11094) Richard (Rick) ZamoraApply
ruff/flake8-implicit-str-concatrule ISC001 (dask#11098) Dimitri Papadopoulos OrfanosFix clocks on Windows with Python 3.13 (distributed#8642) Victor Stinner
Fix “Print host info” CI step on Mac OS (arm64) (distributed#8638) Hendrik Makait
2024.5.0#
Highlights#
This release primarily contains minor bugfixes.
Additional changes
Don’t link to
clickintersphinx dev version (dask#11091) M BussonnierFix API doc links for some
dask-exprexpressions (dask#11092) Patrick HoeflerAdd
dask-exprto upstream build (dask#11086) Patrick HoeflerAdd
meltsupport whenquery-planningis enabled (dask#11088) Richard (Rick) ZamoraSkip dataframe/product when in
numpy2 envs (dask#11089) Benjamin ZaitlenAdd plots to illustrate what the optimizer does (dask#11072) Patrick Hoefler
Fixup
pandasupstream tests (dask#11085) Patrick HoeflerBump
conda-incubator/setup-minicondafrom 3.0.3 to 3.0.4 (dask#11084)Bump
actions/checkoutfrom 4.1.3 to 4.1.4 (dask#11083)Fix CI after
pytestchanges (dask#11082) Patrick HoeflerFixup tests for more efficient
dask-exprimplementation (dask#11071) Patrick HoeflerGeneralize
clear_known_categoriesutility (dask#11059) Richard (Rick) ZamoraBump
JamesIves/github-pages-deploy-actionfrom 4.5.0 to 4.6.0 (dask#11062)Bump
release-drafter/release-drafterfrom 5 to 6 (dask#11063)Bump
actions/checkoutfrom 4.1.2 to 4.1.3 (dask#11061)Update GPU CI
RAPIDS_VERto 24.06, disable query planning (dask#11045) Charles Blackmon-LucaMove tests (distributed#8631) Hendrik Makait
Bump
actions/checkoutfrom 4.1.2 to 4.1.3 (distributed#8628)
2024.4.2#
Highlights#
Trivial Merge Implementation#
The Query Optimizer will inspect quires to determine if a merge(...) or
groupby(...).apply(...) requires a shuffle. A shuffle can be avoided, if the
DataFrame was shuffled on the same columns in a previous step without any operations
in between that change the partitioning layout or the relevant values in each
partition.
>>> result = df.merge(df2, on="a")
>>> result = result.merge(df3, on="a")
The Query optimizer will identify that result was previously shuffled on "a" as
well and thus only shuffle df3 in the second merge operation before doing a blockwise
merge.
Auto-partitioning in read_parquet#
The Query Optimizer will automatically repartition datasets read from Parquet files if individual partitions are too small. This will reduce the number of partitions in consequentially also the size of the task graph.
The Optimizer aims to produce partitions of at least 75MB and will combine multiple files together if necessary to reach this threshold. The value can be configured by using
>>> dask.config.set({"dataframe.parquet.minimum-partition-size": 100_000_000})
The value is given in bytes. The default threshold is relatively conservative to avoid memory issues on worker nodes with a relatively small amount of memory per thread.
Additional changes
Add GitHub Releases automation (dask#11057) Jacob Tomlinson
Add changelog entries for new release (dask#11058) Patrick Hoefler
Reinstate try/except block in
_bind_property(dask#11049) Lawrence MitchellFix link for query planning docs (dask#11054) Patrick Hoefler
Add config parameter for parquet file size (dask#11052) Patrick Hoefler
Update
percentiledocstring (dask#11053) Abel AounAdd docs for query optimizer (dask#11043) Patrick Hoefler
Assignment of np.ma.masked to obect-type Array (dask#9627) David Hassell
Don’t error if
dask_expris not installed (dask#11048) Simon Høxbro HansenAdjust
test_set_indexfor “cudf” backend (dask#11029) Richard (Rick) ZamoraUse
to/from_legacy_dataframeinstead ofto/from_dask_dataframe(dask#11025) Richard (Rick) ZamoraTokenize bag
groupbykeys (dask#10734) Charles SternAdd lazy “cudf” registration for p2p-related dispatch functions (dask#11040) Richard (Rick) Zamora
Collect
memrayprofiles on exception (distributed#8625) Florian JetterEnsure
inprocproperly emulates serialization protocol (distributed#8622) Florian JetterRelax test stats profiling2 (distributed#8621) Florian Jetter
Restart workers when
worker-ttlexpires (distributed#8538) crusaderkyUse
monotonicfor deadline test (distributed#8620) Florian JetterFix race condition for published futures with annotations (distributed#8577) Florian Jetter
Scatter by worker instead of
worker->nthreads(distributed#8590) MilesSend log-event if worker is restarted because of memory pressure (distributed#8617) Patrick Hoefler
Do not print xfailed tests in CI (distributed#8619) Florian Jetter
ensure workers are not downscaled when participating in p2p (distributed#8610) Florian Jetter
Run against stable
fsspec(distributed#8615) Florian Jetter
2024.4.1#
This is a minor bugfix release that that fixes an error when importing
dask.dataframe with Python 3.11.9.
See dask#11035 and dask#11039 from Richard (Rick) Zamora for details.
Additional changes
Remove skips for named aggregations (dask#11036) Patrick Hoefler
Don’t deep-copy read-only buffers on unpickle (distributed#8609) crusaderky
Add
dask-exprtodaskconda recipe (distributed#8601) Charles Blackmon-Luca
2024.4.0#
Highlights#
Query planning fixes#
This release contains a variety of bugfixes in Dask DataFrame’s new query planner.
GPU metric dashboard fixes#
GPU memory and utilization dashboard functionality has been restored. Previously these plots were unintentionally left blank.
See distributed#8572 from Benjamin Zaitlen for details.
Additional changes
Build nightlies on tag releases (dask#11014) Charles Blackmon-Luca
Remove
xfailtracebacks from test suite (dask#11028) Patrick HoeflerFix CI for upstream
pandaschanges (dask#11027) Patrick HoeflerFix
value_countsraising if branch exists of nans only (dask#11023) Patrick HoeflerEnable custom expressions in
dask_cudf(dask#11013) Richard (Rick) ZamoraRaise
ImportErrorinstead ofValueErrorwhendask-exprcannot be imported (dask#11007) James LambAdd HypersSpy to
ecosystem.rst(dask#11008) Jonas LähnemannAdd Hugging Face
hf://to the list offsspeccompatible remote services (dask#11012) Quentin LhoestBump
actions/checkoutfrom 4.1.1 to 4.1.2 (dask#11009)Refresh documentation for annotations and spans (distributed#8593) crusaderky
Fixup deprecation warning from
pandas(distributed#8564) Patrick HoeflerAdd Python 3.11 to GPU CI matrix (distributed#8598) Charles Blackmon-Luca
Deadline to use a monotonic timer (distributed#8597) crusaderky
Update gpuCI
RAPIDS_VERto24.06(distributed#8588)Refactor
restart()andrestart_workers()(distributed#8550) crusaderkyBump
actions/checkoutfrom 4.1.1 to 4.1.2 (distributed#8587)Fix
bokehdeprecations (distributed#8594) MilesFix flaky test:
test_shutsdown_cleanly(distributed#8582) MilesInclude type in failed
sizeofwarning (distributed#8580) James Bourbeau
2024.3.1#
This is a minor release that primarily demotes an exception to a warning if
dask-expr is not installed when upgrading.
Additional changes
Only warn if
dask-expris not installed (dask#11003) Florian JetterFix typos found by codespell (dask#10993) Dimitri Papadopoulos Orfanos
Extra CI job with
dask-exprdisabled (distributed#8583) crusaderkyFix worker dashboard proxy (distributed#8528) Miles
Fix flaky
test_restart_waits_for_new_workers(distributed#8573) crusaderkyFix flaky
test_raise_on_incompatible_partitions(distributed#8571) crusaderky
2024.3.0#
Released on March 11, 2024
Highlights#
Query planning#
This release is enabling query planning by default for all users of
dask.dataframe.
The query planning functionality represents a rewrite of the DataFrame using
dask-expr. This is a drop-in replacement and we expect that most users will
not have to adjust any of their code.
Any feedback can be reported on the Dask issue tracker or on the query planning feedback issue.
If you are encountering any issues you are still able to opt-out by setting
>>> import dask
>>> dask.config.set({'dataframe.query-planning': False})
Sunset of Pandas 1.X support#
The new query planning backend is requiring at least pandas 2.0. This pandas
version will automatically be installed if you are installing from conda or if
you are installing using dask[complete] or dask[dataframe] from pip.
The legacy DataFrame implementation is still supporting pandas 1.X if you
install dask without extras.
Additional changes
Update tests for pandas nightlies with dask-expr (dask#10989) Patrick Hoefler
Use dask-expr docs as main reference docs for DataFrames (dask#10990) Patrick Hoefler
Adjust from_array test for dask-expr (dask#10988) Patrick Hoefler
Unskip
to_delayedtest (dask#10985) Patrick HoeflerBump conda-incubator/setup-miniconda from 3.0.1 to 3.0.3 (dask#10978)
Fix bug when enabling dask-expr (dask#10977) Patrick Hoefler
Update docs and requirements for dask-expr and remove warning (dask#10976) Patrick Hoefler
Fix numpy 2 compatibility with ogrid usage (dask#10929) David Hoese
Turn on dask-expr switch (dask#10967) Patrick Hoefler
Force initializing the random seed with the same byte order interpret… (dask#10970) Elliott Sales de Andrade
Use correct encoding for line terminator when reading CSV (dask#10972) Elliott Sales de Andrade
perf: do not unnecessarily recalculate input/output indices in _optimize_blockwise (dask#10966) Lindsey Gray
Adjust tests for string option in dask-expr (dask#10968) Patrick Hoefler
Adjust tests for array conversion in dask-expr (dask#10973) Patrick Hoefler
TST: Fix sizeof tests on 32bit (dask#10971) Elliott Sales de Andrade
TST: Add missing skip for pyarrow (dask#10969) Elliott Sales de Andrade
Implement dask-expr conversion for
bag.to_dataframe(dask#10963) Patrick HoeflerFix dask-expr import errors (dask#10964) Miles
Clean up Sphinx documentation for
dask.config(dask#10959) crusaderkyUse stdlib
importlib.metadataon Python 3.12+ (dask#10955) wim glennCast partitioning_index to smaller size (dask#10953) Florian Jetter
Reuse dask/dask groupby Aggregation (dask#10952) Patrick Hoefler
ensure tokens on futures are unique (distributed#8569) Florian Jetter
Don’t obfuscate fine performance metrics failures (distributed#8568) crusaderky
Mark shuffle fast tasks in dask-expr (distributed#8563) crusaderky
Weigh gilknocker Prometheus metric by duration (distributed#8558) crusaderky
Fix scheduler transition error on memory->erred (distributed#8549) Hendrik Makait
Make CI happy again (distributed#8560) Miles
Fix flaky test_Future_release_sync (distributed#8562) crusaderky
Fix flaky test_flaky_connect_recover_with_retry (distributed#8556) Hendrik Makait
typing tweaks in scheduler.py (distributed#8551) crusaderky
Bump conda-incubator/setup-miniconda from 3.0.2 to 3.0.3 (distributed#8553)
Install dask-expr on CI (distributed#8552) Hendrik Makait
P2P shuffle can drop partition column before writing to disk (distributed#8531) Hendrik Makait
Better logging for worker removal (distributed#8517) crusaderky
Add indicator support to merge (distributed#8539) Patrick Hoefler
Bump conda-incubator/setup-miniconda from 3.0.1 to 3.0.2 (distributed#8535)
Avoid iteration error when getting module path (distributed#8533) James Bourbeau
Ignore stdlib threading module in code collection (distributed#8532) James Bourbeau
Fix excessive logging on P2P retry (distributed#8511) Hendrik Makait
Prevent typos in retire_workers parameters (distributed#8524) crusaderky
Cosmetic cleanup of test_steal (backport from #8185) (distributed#8509) crusaderky
Fix flaky test_compute_per_key (distributed#8521) crusaderky
Fix flaky test_no_workers_timeout_queued (distributed#8523) crusaderky
2024.2.1#
Released on February 23, 2024
Highlights#
Allow silencing dask.DataFrame deprecation warning#
The last release contained a DeprecationWarning that alerts users to an
upcoming switch of dask.dafaframe to use the new backend with support for
query planning (see also dask#10934).
This DeprecationWarning is triggered in import of the dask.dataframe
module and the community raised concerns about this being to verbose.
It is now possible to silence this warning
# via Python
>>> dask.config.set({'dataframe.query-planning-warning': False})
# via CLI
dask config set dataframe.query-planning-warning False
See dask#10936 and dask#10925 from Miles for details.
More robust distributed scheduler for rare key collisions#
Blockwise fusion optimization can cause a task key collision that is not being handled properly by the distributed scheduler (see dask#9888). Users will typically notice this by seeing one of various internal exceptions that cause a system deadlock or critical failure. While this issue could not be fixed, the scheduler now implements a mechanism that should mitigate most occurences and issues a warning if the issue is detected.
See distributed#8185 from crusaderky and Florian Jetter for details.
Over the course of this, various improvements to tokenization have been
implemented. See dask#10913, dask#10884, dask#10919, dask#10896 and
primarily dask#10883 from crusaderky for more details.
More robust adaptive scaling on large clusters#
Adaptive scaling could previously lose data during downscaling if many tasks had to be moved. This typically, but not exclusively, occured on large clusters and would manifest as a recomputation of tasks and could cause clusters to oscillate between up- and downscaling without ever finishing.
See distributed#8522 from crusaderky for more details.
Additional changes
Remove flaky fastparquet test (dask#10948) Patrick Hoefler
Enable Aggregation from dask-expr (dask#10947) Patrick Hoefler
Update tests for assign change in dask-expr (dask#10944) Patrick Hoefler
Adjust for pandas large string change (dask#10942) Patrick Hoefler
Fix flaky test_describe_empty (dask#10943) crusaderky
Use Python 3.12 as reference environment (dask#10939) crusaderky
[Cosmetic] Clean up temp paths in test_config.py (dask#10938) crusaderky
[CLI]
dask config setanddask config findupdates. (dask#10930) Milescombine_first when a chunk is full of NaNs (dask#10932) crusaderky
Correctly parse lowercase true/false config from CLI (dask#10926) crusaderky
dask config getfix when printing None values (dask#10927) crusaderkyquery-planning can’t be None (dask#10928) crusaderky
Add
dask config set(dask#10921) MilesMake nunique faster again (dask#10922) Patrick Hoefler
Clean up some Cython warnings handling (dask#10924) crusaderky
Bump pre-commit/action from 3.0.0 to 3.0.1 (dask#10920)
Raise and avoid data loss of meta provided to P2P shuffle is wrong (distributed#8520) Florian Jetter
Fix gpuci: np.product is deprecated (distributed#8518) crusaderky
Update gpuCI
RAPIDS_VERto24.04(distributed#8471)Unpin ipywidgets on Python 3.12 (distributed#8516) crusaderky
Keep old dependencies on run_spec collision (distributed#8512) crusaderky
Trivial mypy fix (distributed#8513) crusaderky
Ensure large payload can be serialized and sent over comms (distributed#8507) Florian Jetter
Allow large graph warning threshold to be configured (distributed#8508) Florian Jetter
Tokenization-related test tweaks (backport from #8185) (distributed#8499) crusaderky
Tweaks to
update_graph(backport from #8185) (distributed#8498) crusaderkyAMM: test incremental retirements (distributed#8501) crusaderky
Suppress dask-expr warning in CI (distributed#8505) crusaderky
Ignore dask-expr warning in CI (distributed#8504) James Bourbeau
Improve tests for P2P stable ordering (distributed#8458) Hendrik Makait
Bump pre-commit/action from 3.0.0 to 3.0.1 (distributed#8503)
2024.2.0#
Released on February 9, 2024
Highlights#
Deprecate Dask DataFrame implementation#
The current Dask DataFrame implementation is deprecated. In a future release, Dask DataFrame will use new implementation that contains several improvements including a logical query planning. The user-facing DataFrame API will remain unchanged.
The new implementation is already available and can be enabled by
installing the dask-expr library:
$ pip install dask-expr
and turning the query planning option on:
>>> import dask
>>> dask.config.set({'dataframe.query-planning': True})
>>> import dask.dataframe as dd
API documentation for the new implementation is available at https://docs.dask.org/en/stable/dataframe-api.html
Any feedback can be reported on the Dask issue tracker dask/dask#issues
See dask#10912 from Patrick Hoefler for details.
Improved tokenization#
This release contains several improvements to Dask’s object tokenization logic. More objects now produce deterministic tokens, which can lead to improved performance through caching of intermediate results.
See dask#10898, dask#10904, dask#10876, dask#10874, and dask#10865 from crusaderky for details.
Additional changes
Fix inplace modification on read-only arrays for string conversion (dask#10886) Patrick Hoefler
Add changelog entry for
dask-expr(dask#10915) Patrick HoeflerFix
leftsemimerge forcudf(dask#10914) Patrick HoeflerSlight update to
dask-exprwarning (dask#10916) James BourbeauImprove performance for
groupby.nunique(dask#10910) Patrick HoeflerAdd configuration for
leftsemimerges indask-expr(dask#10908) Patrick HoeflerAdjust assign test for
dask-expr(dask#10907) Patrick HoeflerAvoid
pytest.warnsintest_to_datetimefor GPU CI (dask#10902) Richard (Rick) ZamoraUpdate deployment options in docs homepage (dask#10901) James Bourbeau
Fix typo in dataframe docs (dask#10900) Matthew Rocklin
Bump
peter-evans/create-pull-requestfrom 5 to 6 (dask#10894)Fix mimesis API
>=13.1.0- userandom.randint(dask#10888) MilesAdjust invalid test (dask#10897) Patrick Hoefler
Pickle
da.argwhereandda.count_nonzero(dask#10885) crusaderkyFix
dask-exprtests after singleton pr (dask#10892) Patrick HoeflerSet lower bound version for
s3fs(dask#10889) MilesAdd a couple of
dask-exprfixes for new parquet cache (dask#10880) Florian JetterUpdate deployment documentation (dask#10882) Matthew Rocklin
Start with
dask-exprdoc build (dask#10879) Patrick HoeflerTest tokenization of static and class methods (dask#10872) crusaderky
Add
distributed.printanddistributed.warnto API docs (dask#10878) James BourbeauRun macos ci on M1 architecture (dask#10877) Patrick Hoefler
Update tests for
dask-expr(dask#10838) Patrick HoeflerUpdate parquet tests to align with
dask-exprfixes (dask#10851) Richard (Rick) ZamoraFix regression in
test_graph_manipulation(dask#10873) crusaderkyAdjust
pytesterrors for dask-expr ci (dask#10871) Patrick HoeflerSet upper bound version for
numbawhenpandas<2.1(dask#10890) MilesDeprecate
methodparameter inDataFrame.fillna(dask#10846) MilesRemove warning filter from
pyproject.toml(dask#10867) Patrick HoeflerSkip
test_append_with_partitionfor fastparquet (dask#10828) Patrick HoeflerFix
pytest8 issues (dask#10868) Patrick HoeflerAdjust test for support of median in
Groupby.aggregateindask-expr(2/2) (dask#10870) Hendrik MakaitAllow length of ascending to be larger than one in
sort_values(dask#10864) Florian JetterAllow other message raised in Python 3.9 (dask#10862) Hendrik Makait
Don’t crash when getting computation code in pathological cases (distributed#8502) James Bourbeau
Bump
peter-evans/create-pull-requestfrom 5 to 6 (distributed#8494)fix test of
cudfspilling metrics (distributed#8478) Mads R. B. KristensenUpgrade to
pytest8 (distributed#8482) crusaderkyFix
test_two_consecutive_clients_share_results(distributed#8484) crusaderkyClient word mix-up (distributed#8481) templiert
2024.1.1#
Released on January 26, 2024
Highlights#
Pandas 2.2 and Scipy 1.12 support#
This release contains compatibility updates for the latest pandas and scipy releases.
See dask#10834, dask#10849, dask#10845, and distributed#8474 from crusaderky for details.
Deprecations#
Deprecate
convert_dtypeinapply(dask#10827) MilesDeprecate
axisinDataFrame.rolling(dask#10803) MilesDeprecate
out=anddtype=parameter in most DataFrame methods (dask#10800) crusaderkyDeprecate
axisingroupbycumulative transformers (dask#10796) MilesRename
shuffletoshuffle_methodin remaining methods (dask#10797) Miles
Additional changes
Add recommended deployment options to deployment docs (dask#10866) James Bourbeau
Improve
_agg_finalizeto confirm to output expectation (dask#10835) Hendrik MakaitImplement deterministic tokenization for hlg (dask#10817) Patrick Hoefler
Refactor: move tests for
tokenize()to its own module (dask#10863) crusaderkyUpdate DataFrame examples section (dask#10856) James Bourbeau
Temporarily pin
mimesis<13.1.0(dask#10860) James BourbeauTrivial cosmetic tweaks to
_testing.py(dask#10857) crusaderkyUnskip and adjust tests for
groupby-aggregate withmedianusingdask-expr(dask#10832) Hendrik MakaitFix test for
sizeof(pd.MultiIndex)in upstream CI (dask#10850) crusaderkynumpy2.0: fix slicing byuint64array (dask#10854) crusaderkyRename
numpyversion constants to matchpandas(dask#10843) crusaderkyBump
actions/cachefrom 3 to 4 (dask#10852)Update gpuCI
RAPIDS_VERto24.04(dask#10841)Fix deprecations in doctest (dask#10844) crusaderky
Changed
dtypearithmetics innumpy2.x (dask#10831) crusaderkyAdjust tests for
mediansupport indask-expr(dask#10839) Patrick HoeflerAdjust tests for
mediansupport ingroupby-aggregateindask-expr(dask#10840) Hendrik Makaitnumpy2.x: fixstd()onMaskedArray(dask#10837) crusaderkyFail
dask-exprci if tests fail (dask#10829) Patrick HoeflerActivate
query_planningwhen exporting tests (dask#10833) Patrick HoeflerExpose dataframe tests (dask#10830) Patrick Hoefler
numpy2: deprecations in n-dimensionalfftfunctions (dask#10821) crusaderkyGeneralize
CreationDispatchfordask-expr(dask#10794) Richard (Rick) ZamoraRemove circular import when
dask-exprenabled (dask#10824) MilesMinor[CI]:
publish-test-resultsnot marked as failed (dask#10825) MilesFix more tests to use
pytest.warns()(dask#10818) Michał Górnynp.unique(): inverse is shaped innumpy2 (dask#10819) crusaderkyPin
test_split_adaptive_filestopyarrowengine (dask#10820) Patrick HoeflerAdjust remaining tests in
dask/dask(dask#10813) Patrick HoeflerRestrict test to Arrow only (dask#10814) Patrick Hoefler
Filter warnings from
stdtest (dask#10815) Patrick HoeflerAdjust mostly indexing tests (dask#10790) Patrick Hoefler
Updates to deployment docs (dask#10778) Sarah Charlotte Johnson
Unblock documentation build (dask#10807) Miles
Adjust
test_to_datetimefordask-exprcompatibility Hendrik MakaitUpstream CI tweaks (dask#10806) crusaderky
Improve tests for
to_numeric(dask#10804) Hendrik MakaitFix test-report cache key indent (dask#10798) Miles
Add test-report workflow (dask#10783) Miles
Handle matrix subclass serialization (distributed#8480) Florian Jetter
Use smallest data type for partition column in P2P (distributed#8479) Florian Jetter
pandas2.2: fixtest_dataframe_groupby_tasks(distributed#8475) crusaderkyBump
actions/cachefrom 3 to 4 (distributed#8477)pandas2.2 vs.pyarrow14: deprecatedDatetimeTZBlock(distributed#8476) crusaderkypandas2.2.0: Deprecated frequency aliasMin favor ofME(distributed#8473) Hendrik MakaitFix docs build (distributed#8472) Hendrik Makait
Fix P2P-based joins with explicit
npartitions(distributed#8470) Hendrik MakaitIgnore
dask-exprintest_report.pyscript (distributed#8464) MilesNit: hardcode Python version in test report environment (distributed#8462) crusaderky
Change
test_report.py- skip bad artifacts indask/dask(distributed#8461) MilesReplace all occurrences of
sys.is_finalizing(distributed#8449) Florian Jetter
2024.1.0#
Released on January 12, 2024
Highlights#
Partial rechunks within P2P#
P2P rechunking now utilizes the relationships between input and output chunks. For situations that do not require all-to-all data transfer, this may significantly reduce the runtime and memory/disk footprint. It also enables task culling.
See distributed#8330 from Hendrik Makait for details.
Fastparquet engine deprecated#
The fastparquet Parquet engine has been deprecated. Users should migrate to the pyarrow
engine by installing PyArrow and removing
engine="fastparquet" in read_parquet or to_parquet calls.
See dask#10743 from crusaderky for details.
Improved serialization for arbitrary data#
This release improves serialization robustness for arbitrary data. Previously there were
some cases where serialization could fail for non-msgpack serializable data.
In those cases we now fallback to using pickle.
See dask#8447 from Hendrik Makait for details.
Additional deprecations#
Deprecate
shufflekeyword in favour ofshuffle_methodfor DataFrame methods (dask#10738) Hendrik MakaitDeprecate automatic argument inference in
repartition(dask#10691) Patrick HoeflerDeprecate
computeparameter inset_index(dask#10784) MilesDeprecate
inplaceineval(dask#10785) MilesDeprecate
Series.view(dask#10754) MilesDeprecate
npartitions="auto"forset_index&sort_values(dask#10750) Miles
Additional changes
Avoid shortcut in tasks shuffle that let to data loss (dask#10763) Patrick Hoefler
Ignore data tasks when ordering (dask#10706) Florian Jetter
Add
get_dummiesfromdask-expr(dask#10791) Patrick HoeflerAdjust IO tests for
dask-exprmigration (dask#10776) Patrick HoeflerRemove deprecation warning about
sortandsplit_outingroupby(dask#10788) Patrick HoeflerAddress
pandasdeprecations (dask#10789) Patrick HoeflerImport
distributedonly once inget_scheduler(dask#10771) Florian JetterSimplify GitHub actions (dask#10781) crusaderky
Add unit test overview (dask#10769) Miles
Clean up redundant bits in CI (dask#10768) crusaderky
Update tests for
ufunc(dask#10773) Patrick HoeflerUse
pytest.mark.skipif(DASK_EXPR_ENABLED)(dask#10774) crusaderkyAdjust shuffle tests for
dask-expr(dask#10759) Patrick HoeflerFix some deprecation warnings from
pandas(dask#10749) Patrick HoeflerAdjust shuffle tests for
dask-expr(dask#10762) Patrick HoeflerUpdate
pre-commit(dask#10767) Hendrik MakaitClean up config switches in CI (dask#10766) crusaderky
Improve exception for
validate_key(dask#10765) Hendrik MakaitHandle
datetimeindexesinset_indexwith unknown divisions (dask#10757) Patrick HoeflerAdd hashing for decimals (dask#10758) Patrick Hoefler
Review tests for
is_monotonic(dask#10756) crusaderkyChange argument order in
value_counts_aggregate(dask#10751) Patrick HoeflerAdjust some groupby tests for
dask-expr(dask#10752) Patrick HoeflerRestrict mimesis to
< 12for 3.9 build (dask#10755) Patrick HoeflerDon’t evaluate config in skip condition (dask#10753) Patrick Hoefler
Adjust some tests to be compatible with
dask-expr(dask#10714) Patrick HoeflerMake
dask.array.utilsfunctions more generic to other Dask Arrays (dask#10676) Matthew RocklinRemove duplciate “single machine” section (dask#10747) Matthew Rocklin
Tweak ORC
engine=parameter (dask#10746) crusaderkyAdd pandas 3.0 deprecations and migration prep for
dask-expr(dask#10723) MilesAdd task graph animation to docs homepage (dask#10730) Sarah Charlotte Johnson
Use new Xarray logo (dask#10729) James Bourbeau
Update tab styling on “10 Minutes to Dask” page (dask#10728) James Bourbeau
Update environment file upload step in CI (dask#10726) James Bourbeau
Don’t duplicate unobserved categories in GroupBy.nunqiue if
split_out>1(dask#10716) Patrick HoeflerChangelog entry for
dask.orderupdate (dask#10715) Florian JetterRelax redundant-key check in
_check_dsk(dask#10701) Richard (Rick) ZamoraFix
test_report.py(distributed#8459) MilesRevert
picklechange (distributed#8456) Florian JetterAdapt
test_report.pyto supportdask/daskrepository (distributed#8450) MilesMaintain stable ordering for P2P shuffling (distributed#8453) Hendrik Makait
Add no worker timeout for scheduler (distributed#8371) FTang21
Allow tests workflow to be dispatched manually by maintainers (distributed#8445) Erik Sundell
Make scheduler-related transition functionality private (distributed#8448) Hendrik Makait
Update
pre-commithooks (distributed#8444) Hendrik MakaitDo not always check if
__main__ in resultwhen pickling (distributed#8443) Florian JetterDelegate
wait_for_workersto cluster instances only when implemented (distributed#8441) Erik SundellExtend sleep in
test_pandas(distributed#8440) Julian GilbeyAvoid deprecated
shufflekeyword (distributed#8439) Hendrik MakaitShuffle metrics 4/4: Remove bespoke diagnostics (distributed#8367) crusaderky
Do not run
gilknockerin testsuite (distributed#8423) Florian JetterTweak
abstractmethods(distributed#8427) crusaderkyShuffle metrics 3/4: Capture background metrics (distributed#8366) crusaderky
Shuffle metrics 2/4: Add background metrics (distributed#8365) crusaderky
Shuffle metrics 1/4: Add foreground metrics (distributed#8364) crusaderky
Bump
actions/upload-artifactfrom 3 to 4 (distributed#8420)Fix
test_merge_p2p_shuffle_reused_dataframe_with_different_parameters(distributed#8422) Hendrik MakaitExpand
Client.upload_filedocs example (distributed#8313) MilesImprove logging in P2P’s scheduler plugin (distributed#8410) Hendrik Makait
Re-enable
test_decide_worker_coschedule_order_neighbors(distributed#8402) Florian JetterAdd cuDF spilling statistics to RMM/GPU memory plot (distributed#8148) Charles Blackmon-Luca
Fix inconsistent hashing for Nanny-spawned workers (distributed#8400) Charles Stern
Do not allow workers to downscale if they are running long-running tasks (e.g.
worker_client) (distributed#7481) Florian JetterFix flaky
test_subprocess_cluster_does_not_depend_on_logging(distributed#8417) crusaderky
2023.12.1#
Released on December 15, 2023
Highlights#
Logical Query Planning now available for Dask DataFrames#
Dask DataFrames are now much more performant by using a logical query planner. This feature is currently off by default, but can be turned on with:
dask.config.set({"dataframe.query-planning": True})
You also need to have dask-expr installed:
pip install dask-expr
We’ve seen promising performance improvements so far, see this blog post and these regularly updated benchmarks for more information. A more detailed explanation of how the query optimizer works can be found in this blog post.
This feature is still under active development and the API isn’t stable yet, so breaking changes can occur. We expect to make the query optimizer the default early next year.
See dask#10634 from Patrick Hoefler for details.
Dtype inference in read_parquet#
read_parquet will now infer the Arrow types pa.date32(), pa.date64() and
pa.decimal() as a ArrowDtype in pandas. These dtypes are backed by the
original Arrow array, and thus avoid the conversion to NumPy object. Additionally,
read_parquet will no longer infer nested and binary types as strings, they will
be stored in NumPy object arrays.
See dask#10698 and dask#10705 from Patrick Hoefler for details.
Scheduling improvements to reduce memory usage#
This release includes a major rewrite to a core part of our scheduling logic. It
includes a new approach to the topological sorting algorithm in dask.order
which determines the order in which tasks are run. Improper ordering is known to
be a major contributor to too large cluster memory pressure.
Updates in this release fix a couple of performance regressions that were introduced
in the release 2023.10.0 (see dask#10535). Generally, computations should now
be much more eager to release data if it is no longer required in memory.
See dask#10660, dask#10697 from Florian Jetter for details.
Improved P2P-based merging robustness and performance#
This release contains several updates that fix a possible deadlock introduced in 2023.9.2 and improve the robustness of P2P-based merging when the cluster is dynamically scaling up.
See distributed#8415, distributed#8416, and distributed#8414 from Hendrik Makait for details.
Removed disabling pickle option#
The distributed.scheduler.pickle configuration option is no longer supported.
As of the 2023.4.0 release, pickle is used to transmit task graphs, so can no
longer be disabled. We now raise an informative error when distributed.scheduler.pickle
is set to False.
See distributed#8401 from Florian Jetter for details.
Additional changes
Add changelog entry for recent P2P merge fixes (dask#10712) Hendrik Makait
Update DataFrame page (dask#10710) Matthew Rocklin
Add changelog entry for
dask-exprswitch (dask#10704) Patrick HoeflerImprove changelog entry for
PipInstallchanges (dask#10711) Hendrik MakaitRemove PR labeler (dask#10709) James Bourbeau
Add
.__wrapped__toDelayedobject (dask#10695) Andrew S. RosenBump
actions/labelerfrom 4.3.0 to 5.0.0 (dask#10689)Bump
actions/stalefrom 8 to 9 (dask#10690)[Dask.order] Remove non-runnable leaf nodes from ordering (dask#10697) Florian Jetter
Update installation docs (dask#10699) Matthew Rocklin
Fix software environment link in docs (dask#10700) James Bourbeau
Avoid converting non-strings to arrow strings for read_parquet (dask#10692) Patrick Hoefler
Bump
xarray-contrib/issue-from-pytest-logfrom 1.2.7 to 1.2.8 (dask#10687)Fix
tokenizeforpd.DateOffset(dask#10664) jochenottBugfix for writing empty array to zarr (dask#10506) Ben
Docs update, fixup styling, mention free (dask#10679) Matthew Rocklin
Update deployment docs (dask#10680) Matthew Rocklin
Dask.order rewrite using a critical path approach (dask#10660) Florian Jetter
Avoid substituting keys that occur multiple times (dask#10646) Florian Jetter
Add missing image to docs (dask#10694) Matthew Rocklin
Bump
actions/setup-pythonfrom 4 to 5 (dask#10688)Update landing page (dask#10674) Matthew Rocklin
Make meta check simpler in dispatch (dask#10638) Patrick Hoefler
Pin PR Labeler (dask#10675) Matthew Rocklin
Reorganize docs index a bit (dask#10669) Matthew Rocklin
Bump
actions/setup-javafrom 3 to 4 (dask#10667)Bump
conda-incubator/setup-minicondafrom 2.2.0 to 3.0.1 (dask#10668)Bump
xarray-contrib/issue-from-pytest-logfrom 1.2.6 to 1.2.7 (dask#10666)Fix
test_categorize_infowith nightlypyarrow(dask#10662) James BourbeauRewrite
test_subprocess_cluster_does_not_depend_on_logging(distributed#8409) Hendrik MakaitAvoid
RecursionErrorwhen failing to pickle key inSpillBufferand usingtblib=3(distributed#8404) Hendrik MakaitAllow tasks to override
is_rootishheuristic (distributed#8412) Hendrik MakaitRemove GPU executor (distributed#8399) Hendrik Makait
Do not rely on logging for subprocess cluster (distributed#8398) Hendrik Makait
Update gpuCI
RAPIDS_VERto24.02(distributed#8384)Bump
actions/setup-pythonfrom 4 to 5 (distributed#8396)Ensure output chunks in P2P rechunking are distributed homogeneously (distributed#8207) Florian Jetter
Trivial: fix typo (distributed#8395) crusaderky
Bump
JamesIves/github-pages-deploy-actionfrom 4.4.3 to 4.5.0 (distributed#8387)Bump
conda-incubator/setup-miniconda from3.0.0 to 3.0.1 (distributed#8388)
2023.12.0#
Released on December 1, 2023
Highlights#
PipInstall restart and environment variables#
The distributed.PipInstall plugin now has more robust restart logic and also supports
environment variables.
Below shows how users can use the distributed.PipInstall plugin and a TOKEN environment
variable to securely install a package from a private repository:
from dask.distributed import PipInstall
plugin = PipInstall(packages=["private_package@git+https://${TOKEN}@github.com/dask/private_package.git])
client.register_plugin(plugin)
See distributed#8374, distributed#8357, and distributed#8343 from Hendrik Makait for details.
Bokeh 3.3.0 compatibility#
This release contains compatibility updates for using bokeh>=3.3.0 with proxied Dask dashboards.
Previously the contents of dashboard plots wouldn’t be displayed.
See distributed#8347 and distributed#8381 from Jacob Tomlinson for details.
Additional changes
Add
networkmarker totest_pyarrow_filesystem_option_real_data(dask#10653) Richard (Rick) ZamoraBump GPU CI to CUDA 11.8 (dask#10656) Charles Blackmon-Luca
Tokenize
pandasoffsets deterministically (dask#10643) Patrick HoeflerAdd tokenize
pd.NAfunctionality (dask#10640) Patrick HoeflerUpdate gpuCI
RAPIDS_VERto24.02(dask#10636)Fix precision handling in
array.linalg.norm(dask#10556) joanrueAdd
axisargument toDataFrame.clipandSeries.clip(dask#10616) Richard (Rick) ZamoraUpdate changelog entry for in-memory rechunking (dask#10630) Florian Jetter
Fix flaky
test_resources_reset_after_cancelled_task(distributed#8373) crusaderkyBump GPU CI to CUDA 11.8 (distributed#8376) Charles Blackmon-Luca
Bump
conda-incubator/setup-minicondafrom 2.2.0 to 3.0.0 (distributed#8372)Add debug logs to P2P scheduler plugin (distributed#8358) Hendrik Makait
O(1)access for/info/task/endpoint (distributed#8363) crusaderkyRemove stringification from shuffle annotations (distributed#8362) crusaderky
Don’t cast
intmetrics tofloat(distributed#8361) crusaderkyDrop asyncio TCP backend (distributed#8355) Florian Jetter
Add offload support to
context_meter.add_callback(distributed#8360) crusaderkyTest that
sync()propagates contextvars (distributed#8354) crusaderkycaptured_context_meter(distributed#8352) crusaderkycontext_meter.clear_callbacks(distributed#8353) crusaderkyUse
@log_errorsdecorator (distributed#8351) crusaderkyFix
test_statistical_profiling_cycle(distributed#8356) Florian JetterShuffle: don’t parse dask.config at every RPC (distributed#8350) crusaderky
Replace
Client.register_pluginsidempotentargument with.idempotentattribute on plugins (distributed#8342) Hendrik MakaitFix test report generation (distributed#8346) Hendrik Makait
Install
pyarrow-hotfixonmindeps-pandasCI (distributed#8344) Hendrik MakaitReduce memory usage of scheduler process - optimize
scheduler.py::TaskStateclass (distributed#8331) MilesBump
pre-commitlinters (distributed#8340) crusaderkyUpdate cuDF test with explicit
dtype=object(distributed#8339) Peter Andreas EntschevFix
Cluster/SpecClustercalls to async close methods (distributed#8327) Peter Andreas Entschev
2023.11.0#
Released on November 10, 2023
Highlights#
Zero-copy P2P Array Rechunking#
Users should see significant performance improvements when using in-memory P2P array rechunking. This is due to no longer copying underlying data buffers.
Below shows a simple example where we compare performance of different rechunking methods.
shape = (30_000, 6_000, 150) # 201.17 GiB
input_chunks = (60, -1, -1) # 411.99 MiB
output_chunks = (-1, 6, -1) # 205.99 MiB
arr = da.random.random(size, chunks=input_chunks)
with dask.config.set({
"array.rechunk.method": "p2p",
"distributed.p2p.disk": True,
}):
(
da.random.random(size, chunks=input_chunks)
.rechunk(output_chunks)
.sum()
.compute()
)
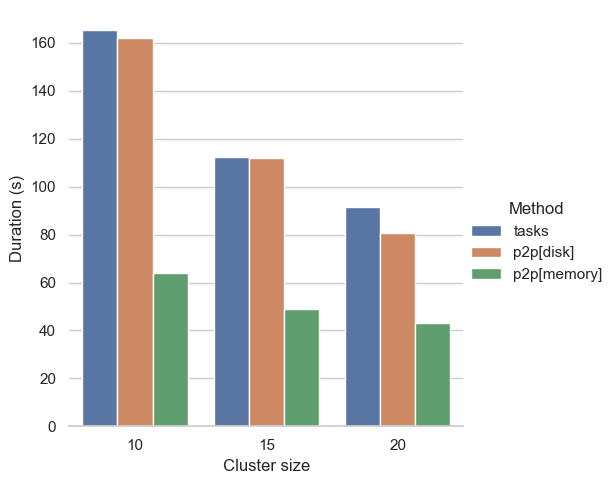
See distributed#8282, distributed#8318, distributed#8321 from crusaderky and (distributed#8322) from Hendrik Makait for details.
Deprecating PyArrow <14.0.1#
pyarrow<14.0.1 usage is deprecated starting in this release. It’s recommended for all users to upgrade their
version of pyarrow or install pyarrow-hotfix. See this CVE
for full details.
See dask#10622 from Florian Jetter for details.
Improved PyArrow filesystem for Parquet#
Using filesystem="arrow" when reading Parquet datasets now properly inferrs the correct cloud region
when accessing remote, cloud-hosted data.
See dask#10590 from Richard (Rick) Zamora for details.
Improve Type Reconciliation in P2P Shuffling#
See distributed#8332 from Hendrik Makait for details.
Additional changes
Fix sporadic failure of
test_dataframe::test_quantile(dask#10625) MilesBump minimum
clickto>=8.1(dask#10623) Jacob TomlinsonRefactor
test_quantile(dask#10620) MilesAvoid
PerformanceWarningfor fragmented DataFrame (dask#10621) Patrick HoeflerGeneralize computation of
NEW_*_VERin GPU CI updating workflow (dask#10610) Charles Blackmon-LucaSwitch to newer GPU CI images (dask#10608) Charles Blackmon-Luca
Remove double slash in
fsspectests (dask#10605) Mario ŠaškoReenable
test_ucx_config_w_env_var(distributed#8272) Peter Andreas EntschevDon’t share
host_arraywhen receiving from network (distributed#8308) crusaderkyGeneralize computation of
NEW_*_VERin GPU CI updating workflow (distributed#8319) Charles Blackmon-LucaSwitch to newer GPU CI images (distributed#8316) Charles Blackmon-Luca
Minor updates to shuffle dashboard (distributed#8315) Matthew Rocklin
Don’t use
bytearray().join(distributed#8312) crusaderkyReuse identical shuffles in P2P hash join (distributed#8306) Hendrik Makait
2023.10.1#
Released on October 27, 2023
Highlights#
Python 3.12#
This release adds official support for Python 3.12.
See dask#10544 and distributed#8223 from Thomas Grainger for details.
Additional changes
Avoid splitting parquet files to row groups as aggressively (dask#10600) Matthew Rocklin
Speed up
normalize_chunksfor common case (dask#10579) Martin DurantUse Python 3.11 for upstream and doctests CI build (dask#10596) Thomas Grainger
Bump
actions/checkoutfrom 4.1.0 to 4.1.1 (dask#10592)Switch to PyTables
HEAD(dask#10580) Thomas GraingerRemove
numpy.corewarning filter, link to issue onpyarrowcausedBlockManagerwarning (dask#10571) Thomas GraingerUnignore and fix deprecated freq aliases (dask#10577) Thomas Grainger
Move
register_assert_rewriteearlier inconftestto fix warnings (dask#10578) Thomas GraingerUpgrade
versioneerto 0.29 (dask#10575) Thomas Graingerchange
test_concat_categoricalto be non-strict (dask#10574) Thomas GraingerEnable SciPy tests with NumPy 2.0 Thomas Grainger
Enable tests for scikit-image with NumPy 2.0 (dask#10569) Thomas Grainger
Fix upstream build (dask#10549) Thomas Grainger
Add optimized code paths for
drop_duplicates(dask#10542) Richard (Rick) ZamoraSupport
cudfbackend indd.DataFrame.sort_values(dask#10551) Richard (Rick) ZamoraRename “GIL Contention” to just GIL in chart labels (distributed#8305) Matthew Rocklin
Bump
actions/checkoutfrom 4.1.0 to 4.1.1 (distributed#8299)Fix dashboard (distributed#8293) Hendrik Makait
@log_errorsfor async tasks (distributed#8294) crusaderkyAnnotations and better tests for serialize_bytes (distributed#8300) crusaderky
Temporarily xfail
test_decide_worker_coschedule_order_neighborsto unblock CI (distributed#8298) James BourbeauSkip
xdistandmatplotlibin code samples (distributed#8290) Matthew RocklinUse
numpy._coreonnumpy>=2.dev0(distributed#8291) Thomas GraingerFix calculation of
MemoryShardsBuffer.bytes_read(distributed#8289) crusaderkyAllow P2P to store data in-memory (distributed#8279) Hendrik Makait
Upgrade
versioneerto 0.29 (distributed#8288) Thomas GraingerAllow
ResourceLimiterto be unlimited (distributed#8276) Hendrik MakaitRun
pre-commitautoupdate (distributed#8281) Thomas GraingerAnnotate instance variables for P2P layers (distributed#8280) Hendrik Makait
Remove worker gracefully should not mark tasks as suspicious (distributed#8234) Thomas Grainger
Add signal handling to
dask spec(distributed#8261) Thomas GraingerAdd typing for
sync(distributed#8275) Hendrik MakaitBetter annotations for shuffle offload (distributed#8277) crusaderky
Test minimum versions for p2p shuffle (distributed#8270) crusaderky
Run coverage on test failures (distributed#8269) crusaderky
Use
aiohttpwith extensions (distributed#8274) Thomas Grainger
2023.10.0#
Released on October 13, 2023
Highlights#
Reduced memory pressure for multi array reductions#
This release contains major updates to Dask’s task graph scheduling logic. The updates here significantly reduce memory pressure on array reductions. We anticipate this will have a strong impact on the array computing community.
See dask#10535 from Florian Jetter for details.
Improved P2P shuffling robustness#
There are several updates (listed below) that make P2P shuffling much more robust and less likely to fail.
See distributed#8262, distributed#8264, distributed#8242, distributed#8244, and distributed#8235 from Hendrik Makait and distributed#8124 from Charles Blackmon-Luca for details.
Reduced scheduler CPU load for large graphs#
Users should see reduced CPU load on their scheduler when computing large task graphs.
See distributed#8238 and dask#10547 from Florian Jetter and distributed#8240 from crusaderky for details.
Additional changes
Dispatch the
partd.Encodeclass used for disk-based shuffling (dask#10552) Richard (Rick) ZamoraAdd documentation for hive partitioning (dask#10454) Richard (Rick) Zamora
Add typing to
dask.order(dask#10553) Florian JetterAllow passing
index_col=Falseindd.read_csv(dask#9961) Michael LeslieTighten
HighLevelGraphannotations (dask#10524) crusaderkySupport for latest
ipykernel/ipywidgets(distributed#8253) crusaderkyCheck minimal
pyarrowversion for P2P merge (distributed#8266) Hendrik MakaitSupport for Python 3.12 (distributed#8223) Thomas Grainger
Use
memoryview.nbyteswhen warning on large graph send (distributed#8268) crusaderkyRun tests without
gilknocker(distributed#8263) crusaderkyDisable ipv6 on MacOS CI (distributed#8254) crusaderky
Clean up redundant minimum versions (distributed#8251) crusaderky
Clean up use of
BARRIER_PREFIXin scheduler plugin (distributed#8252) crusaderkyImprove shuffle run handling in P2P’s worker plugin (distributed#8245) Hendrik Makait
Explicitly set
charset=utf-8(distributed#8250) crusaderkyTyping tweaks to distributed#8239 (distributed#8247) crusaderky
Simplify scheduler assertion (distributed#8246) crusaderky
Improve typing (distributed#8239) Hendrik Makait
Respect cgroups v2 “low” memory limit (distributed#8243) Samantha Hughes
Fix
PackageInstallby making it a scheduler plugin (distributed#8142) Hendrik MakaitXfail
test_ucx_config_w_env_var(distributed#8241) crusaderkySpecClusterresilience to broken workers (distributed#8233) crusaderkySuppress
SpillBufferstack traces for cancelled tasks (distributed#8232) crusaderkyUpdate annotations after stringification changes (distributed#8195) crusaderky
Reduce max recursion depth of profile (distributed#8224) crusaderky
Offload deeply nested objects (distributed#8214) crusaderky
Fix flaky
test_close_connections(distributed#8231) crusaderkyFix flaky
test_popen_timeout(distributed#8229) crusaderkyFix flaky
test_adapt_then_manual(distributed#8228) crusaderkyPrevent collisions in
SpillBuffer(distributed#8226) crusaderkyAllow
retire_workersto run concurrently (distributed#8056) Florian JetterFix HTML repr for
TaskStateobjects (distributed#8188) Florian JetterFix
AttributeErrorforbuiltin_function_or_methodinprofile.py(distributed#8181) Florian JetterFix flaky
test_spans(v2) (distributed#8222) crusaderky
2023.9.3#
Released on September 29, 2023
Highlights#
Restore previous configuration override behavior#
The 2023.9.2 release introduced an unintentional breaking change in
how configuration options are overriden in dask.config.get with
the override_with= keyword (see dask#10519).
This release restores the previous behavior.
See dask#10521 from crusaderky for details.
Complex dtypes in Dask Array reductions#
This release includes improved support for using common reductions
in Dask Array (e.g. var, std, moment) with complex dtypes.
See dask#10009 from wkrasnicki for details.
Additional changes
Bump
actions/checkoutfrom 4.0.0 to 4.1.0 (dask#10532)Match
pandasrevertingapplydeprecation (dask#10531) James BourbeauUpdate gpuCI
RAPIDS_VERto23.12(dask#10526)Temporarily skip failing tests with
fsspec==2023.9.1(dask#10520) James Bourbeau
2023.9.2#
Released on September 15, 2023
Highlights#
P2P shuffling now raises when outdated PyArrow is installed#
Previously the default shuffling method would silently fallback from P2P
to task-based shuffling if an older version of pyarrow was installed.
Now we raise an informative error with the minimum required pyarrow
version for P2P instead of silently falling back.
See dask#10496 from Hendrik Makait for details.
Deprecation cycle for admin.traceback.shorten#
The 2023.9.0 release modified the admin.traceback.shorten configuration option
without introducing a deprecation cycle. This resulted in failures to create Dask
clusters in some cases. This release introduces a deprecation cycle for this configuration
change.
See dask#10509 from crusaderky for details.
Additional changes
Avoid materializing all iterators in
delayedtasks (dask#10498) James BourbeauOverhaul deprecations system in
dask.config(dask#10499) crusaderkyRemove unnecessary check in
timeseries(dask#10447) Patrick HoeflerUse
register_pluginin tests (dask#10503) James BourbeauMake
preserve_indexexplicit inpyarrow_schema_dispatch(dask#10501) Hendrik MakaitAdd
**kwargssupport forpyarrow_schema_dispatch(dask#10500) Hendrik MakaitCentralize and type
no_default(dask#10495) crusaderky
2023.9.1#
Released on September 6, 2023
Note
This is a hotfix release that fixes a P2P shuffling bug introduced in the 2023.9.0 release (see dask#10493).
Enhancements#
Stricter data type for dask keys (dask#10485) crusaderky
Special handling for
NoneinDASK_environment variables (dask#10487) crusaderky
Bug Fixes#
Fix
_partitionsdtypeinmetaforDataFrame.set_indexandDataFrame.sort_values(dask#10493) Hendrik MakaitHandle
cached_propertydecorators inderived_from(dask#10490) Lawrence Mitchell
Maintenance#
Bump
actions/checkoutfrom 3.6.0 to 4.0.0 (dask#10492)Simplify some tests that
import distributed(dask#10484) crusaderky
2023.9.0#
Released on September 1, 2023
Bug Fixes#
Remove support for
np.int64in keys (dask#10483) crusaderkyFix
_partitionsdtypeinmetafor shuffling (dask#10462) Hendrik MakaitDon’t use exception hooks to shorten tracebacks (dask#10456) crusaderky
Documentation#
Add
p2pshuffle option to DataFrame docs (dask#10477) Patrick Hoefler
Maintenance#
Skip failing tests for
pandas=2.1.0(dask#10488) Patrick HoeflerUpdate tests for
pandas=2.1.0(dask#10439) Patrick HoeflerEnable
pytest-timeout(dask#10482) crusaderkyBump
actions/checkoutfrom 3.5.3 to 3.6.0 (dask#10470)
2023.8.1#
Released on August 18, 2023
Enhancements#
Adding support for cgroup v2 to
cpu_count(dask#10419) Johan OlssonSupport multi-column
groupbywithsort=Trueandsplit_out>1(dask#10425) Richard (Rick) ZamoraAdd
DataFrame.enforce_runtime_divisionsmethod (dask#10404) Richard (Rick) ZamoraEnable file
mode="x"with asingle_file=Truefor Dask DataFrameto_csv(dask#10443) Genevieve Buckley
Bug Fixes#
Fix
ValueErrorwhen runningto_csvin append mode withsingle_fileasTrue(dask#10441) Ben
Maintenance#
Add default
types_mappertofrom_pyarrow_table_dispatchforpandas(dask#10446) Richard (Rick) Zamora
2023.8.0#
Released on August 4, 2023
Enhancements#
Fix for
make_timeseriesperformance regression (dask#10428) Irina Truong
Documentation#
Add
distributed.printto debugging docs (dask#10435) James BourbeauDocumenting compatibility of NumPy functions with Dask functions (dask#9941) Chiara Marmo
Maintenance#
Use SPDX in
licensemetadata (dask#10437) John A KirkhamRequire
dask[array]indask[dataframe](dask#10357) John A KirkhamUpdate gpuCI
RAPIDS_VERto23.10(dask#10427)Simplify compatibility code (dask#10426) Hendrik Makait
Fix compatibility variable naming (dask#10424) Hendrik Makait
Fix a few errors with upstream
pandasandpyarrow(dask#10412) Irina Truong
2023.7.1#
Released on July 20, 2023
Note
This release updates Dask DataFrame to automatically convert
text data using object data types to string[pyarrow]
if pandas>=2 and pyarrow>=12 are installed.
This should result in significantly reduced memory consumption and increased computation performance in many workflows that deal with text data.
You can disable this change by setting the dataframe.convert-string
configuration value to False with
dask.config.set({"dataframe.convert-string": False})
Enhancements#
Convert to
pyarrowstrings if proper dependencies are installed (dask#10400) James BourbeauAvoid
repartitionbeforeshuffleforp2p(dask#10421) Patrick HoeflerAPI to generate random Dask DataFrames (dask#10392) Irina Truong
Speed up
dask.bag.Bag.random_sample(dask#10356) crusaderkyRaise helpful
ValueErrorfor invalid time units (dask#10408) Nat TabrisMake
repartitiona no-op when divisions match (divisions provided as a list) (dask#10395) Nicolas Grandemange
Bug Fixes#
Use
dataframe.convert-stringinread_parquettoken (dask#10411) James BourbeauCategory
dtypeis lost when concatenatingMultiIndex(dask#10407) Irina TruongFix
FutureWarning: The provided callable...(dask#10405) Irina TruongEnable non-categorical hive-partition columns in
read_parquet(dask#10353) Richard (Rick) ZamoraconcatignoringDataFramewithouth columns (dask#10359) Patrick Hoefler
2023.7.0#
Released on July 7, 2023
Enhancements#
Catch exceptions when attempting to load CLI entry points (dask#10380) Jacob Tomlinson
Bug Fixes#
Fix typo in
_clean_ipython_traceback(dask#10385) Alexander ClausenEnsure that
dfis immutable afterfrom_pandas(dask#10383) Patrick HoeflerWarn consistently for
inplaceinSeries.rename(dask#10313) Patrick Hoefler
Documentation#
Add clarification about output shape and reshaping in rechunk documentation (dask#10377) Swayam Patil
Maintenance#
Simplify
astypeimplementation (dask#10393) Patrick HoeflerFix
test_first_and_lastto accommodate deprecatedlast(dask#10373) James BourbeauAdd
leveltocreate_merge_tree(dask#10391) Patrick HoeflerDo not derive from
scipy.stats.chisquaredocstring (dask#10382) Doug Davis
2023.6.1#
Released on June 26, 2023
Enhancements#
Remove no longer supported
clip_lowerandclip_upper(dask#10371) Patrick HoeflerSupport
DataFrame.set_index(..., sort=False)(dask#10342) MilesCleanup remote tracebacks (dask#10354) Irina Truong
Add dispatching mechanisms for
pyarrow.Tableconversion (dask#10312) Richard (Rick) ZamoraChoose P2P even if fusion is enabled (dask#10344) Hendrik Makait
Validate that rechunking is possible earlier in graph generation (dask#10336) Hendrik Makait
Bug Fixes#
Fix issue with
headerpassed toread_csv(dask#10355) GALI PREM SAGARRespect
dropnaandobservedinGroupBy.varandGroupBy.std(dask#10350) Patrick HoeflerFix
H5FD_lockerror when writing to hdf with distributed client (dask#10309) Irina TruongFix for
total_mem_usageofbag.map()(dask#10341) Irina Truong
Deprecations#
Deprecate
DataFrame.fillna/Series.fillnawithmethod(dask#10349) Irina TruongDeprecate
DataFrame.firstandSeries.first(dask#10352) Irina Truong
Maintenance#
Deprecate
numpy.compat(dask#10370) Irina TruongFix annotations and spans leaking between threads (dask#10367) Irina Truong
Use general kwargs in
pyarrow_table_dispatchfunctions (dask#10364) Richard (Rick) ZamoraRemove unnecessary
try/exceptinisna(dask#10363) Patrick Hoeflermypysupport for numpy 1.25 (dask#10362) crusaderkyBump
actions/checkoutfrom 3.5.2 to 3.5.3 (dask#10348)Restore
numbainupstreambuild (dask#10330) James BourbeauUpdate nightly wheel index for
pandas/numpy/scipy(dask#10346) Matthew RoeschkeAdd rechunk config values to yaml (dask#10343) Hendrik Makait
2023.6.0#
Released on June 9, 2023
Enhancements#
Add missing
not inpredicate support toread_parquet(dask#10320) Richard (Rick) Zamora
Bug Fixes#
Fix for incorrect
value_counts(dask#10323) Irina TruongUpdate empty
describetop and freq values (dask#10319) James Bourbeau
Documentation#
Fix hetzner typo (dask#10332) Sarah Charlotte Johnson
Maintenance#
Test with
numbaandsparseon Python 3.11 (dask#10329) Thomas GraingerRemove
numpy.find_common_typewarning ignore (dask#10311) James BourbeauUpdate gpuCI
RAPIDS_VERto23.08(dask#10310)
2023.5.1#
Released on May 26, 2023
Note
This release drops support for Python 3.8. As of this release Dask supports Python 3.9, 3.10, and 3.11. See this community issue for more details.
Enhancements#
Drop Python 3.8 support (dask#10295) Thomas Grainger
Change Dask Bag partitioning scheme to improve cluster saturation (dask#10294) Jacob Tomlinson
Generalize
dd.to_datetimefor GPU-backed collections, introduceget_meta_libraryutility (dask#9881) Charles Blackmon-LucaAdd
na_actiontoDataFrame.map(dask#10305) Patrick HoeflerRaise
TypeErrorinDataFrame.nsmallestandDataFrame.nlargestwhencolumnsis not given (dask#10301) Patrick HoeflerImprove
sizeofforpd.MultiIndex(dask#10230) Patrick HoeflerSupport duplicated columns in a bunch of
DataFramemethods (dask#10261) Patrick HoeflerAdd
numeric_onlysupport toDataFrame.idxminandDataFrame.idxmax(dask#10253) Patrick HoeflerImplement
numeric_onlysupport forDataFrame.quantile(dask#10259) Patrick HoeflerAdd support for
numeric_only=FalseinDataFrame.std(dask#10251) Patrick HoeflerImplement
numeric_only=FalseforGroupBy.cumprodandGroupBy.cumsum(dask#10262) Patrick HoeflerImplement
numeric_onlyforskewandkurtosis(dask#10258) Patrick Hoeflermaskandwhereshould accept acallable(dask#10289) Irina TruongFix conversion from
Categoricaltopa.dictionaryinread_parquet(dask#10285) Patrick Hoefler
Bug Fixes#
Spurious config on nested annotations (dask#10318) crusaderky
Fix rechunking behavior for dimensions with known and unknown chunk sizes (dask#10157) Hendrik Makait
Enable
dropto support mismatched partitions (dask#10300) James BourbeauFix
divisionsconstruction forto_timestamp(dask#10304) Patrick Hoeflerpandas
ExtensionDtyperaising inSeriesreduction operations (dask#10149) Patrick HoeflerFix regression in
da.randominterface (dask#10247) Eray Aslanda.coarsendoesn’t trim an empty chunk in meta (dask#10281) Irina TruongFix dtype inference for
engine="pyarrow"inread_csv(dask#10280) Patrick Hoefler
Documentation#
Add
meta_from_arrayto API docs (dask#10306) Ruth ComerUpdate Coiled links (dask#10296) Sarah Charlotte Johnson
Add docs for demo day (dask#10288) Matthew Rocklin
Maintenance#
Explicitly install
anaconda-clientfrom conda-forge when uploading conda nightlies (dask#10316) Charles Blackmon-LucaConfigure
isortto addfrom __future__ import annotations(dask#10314) Thomas GraingerAvoid
pandasSeries.__getitem__deprecation in tests (dask#10308) James BourbeauIgnore
numpy.find_common_typewarning frompandas(dask#10307) James BourbeauAdd test to check that
DataFrame.__setitem__does not modifydfinplace (dask#10223) Patrick HoeflerClean up default value of
dropnainvalue_counts(dask#10299) Patrick HoeflerAdd
pytest-covtotestextra (dask#10271) James Bourbeau
2023.5.0#
Released on May 12, 2023
Enhancements#
Implement
numeric_only=FalseforGroupBy.corrandGroupBy.cov(dask#10264) Patrick HoeflerAdd support for
numeric_only=FalseinDataFrame.var(dask#10250) Patrick HoeflerAdd
numeric_onlysupport toDataFrame.mode(dask#10257) Patrick HoeflerAdd
DataFrame.maptodask.DataFrameAPI (dask#10246) Patrick HoeflerAdjust for
DataFrame.applymapdeprecation and allNAconcatbehaviour change (dask#10245) Patrick HoeflerEnable
numeric_only=FalseforDataFrame.count(dask#10234) Patrick HoeflerDisallow array input in mask/where (dask#10163) Irina Truong
Support
numeric_only=TrueinGroupBy.corrandGroupBy.cov(dask#10227) Patrick HoeflerAdd
numeric_onlysupport toGroupBy.median(dask#10236) Patrick HoeflerSupport
mimesis=9indask.datasets(dask#10241) James BourbeauAdd
numeric_onlysupport tomin,maxandprod(dask#10219) Patrick HoeflerAdd
numeric_only=Truesupport forGroupBy.cumsumandGroupBy.cumprod(dask#10224) Patrick HoeflerAdd helper to unpack
numeric_onlykeyword (dask#10228) Patrick Hoefler
Bug Fixes#
Fix
clone+from_arrayfailure (dask#10211) crusaderkyFix dataframe reductions for ea dtypes (dask#10150) Patrick Hoefler
Avoid scalar conversion deprecation warning in
numpy=1.25(dask#10248) James BourbeauMake sure transform output has the same index as input (dask#10184) Irina Truong
Fix
corrandcovon a single-row partition (dask#9756) Irina TruongFix
test_groupby_numeric_only_supportedandtest_groupby_aggregate_categorical_observedupstream errors (dask#10243) Irina Truong
Documentation#
Clean up futures docs (dask#10266) Matthew Rocklin
Add
IndexAPI reference (dask#10263) hotpotato
Maintenance#
Warn when meta is passed to
apply(dask#10256) Patrick HoeflerRemove
imageioversion restriction in CI (dask#10260) Patrick HoeflerRemove unused
DataFramevariance methods (dask#10252) Patrick HoeflerUn-
xfailtest_categorieswithpyarrowstrings andpyarrow>=12(dask#10244) Irina TruongBump gpuCI
PYTHON_VER3.8->3.9 (dask#10233) Charles Blackmon-Luca
2023.4.1#
Released on April 28, 2023
Enhancements#
Implement
numeric_onlysupport forDataFrame.sum(dask#10194) Patrick HoeflerAdd support for
numeric_only=TrueinGroupByoperations (dask#10222) Patrick HoeflerAvoid deep copy in
DataFrame.__setitem__forpandas1.4 and up (dask#10221) Patrick HoeflerAvoid calling
Series.applywith_meta_nonempty(dask#10212) Patrick HoeflerUnpin
sqlalchemyand fix compatibility issues (dask#10140) Patrick Hoefler
Bug Fixes#
Partially revert default client discovery (dask#10225) Florian Jetter
Support arrow dtypes in
Indexmeta creation (dask#10170) Patrick HoeflerRepartitioning raises with extension dtype when truncating floats (dask#10169) Patrick Hoefler
Adjust empty
Indexfromfastparquettoobjectdtype (dask#10179) Patrick Hoefler
Documentation#
Update Kubernetes docs (dask#10232) Jacob Tomlinson
Add
DataFrame.reductionto API docs (dask#10229) James BourbeauAdd
DataFrame.persistto docs and fix links (dask#10231) Patrick HoeflerAdd documentation for
GroupBy.transform(dask#10185) Irina TruongFix formatting in random number generation docs (dask#10189) Eray Aslan
Maintenance#
Pin imageio to
<2.28(dask#10216) Patrick HoeflerAdd note about
importlib_metadatabackport (dask#10207) James BourbeauAdd
xarrayback to Python 3.11 CI builds (dask#10200) James BourbeauAdd
mindepsbuild with all optional dependencies (dask#10161) Charles Blackmon-LucaProvide proper
likevalue forarray_safeinpercentiles_summary(dask#10156) Charles Blackmon-LucaAvoid re-opening hdf file multiple times in
read_hdf(dask#10205) Thomas GraingerAdd merge tests on nullable columns (dask#10071) Charles Blackmon-Luca
Fix coverage configuration (dask#10203) Thomas Grainger
Remove
is_period_dtypeandis_sparse_dtype(dask#10197) Patrick HoeflerBump
actions/checkoutfrom 3.5.0 to 3.5.2 (dask#10201)Avoid deprecated
is_categorical_dtypefrom pandas (dask#10180) Patrick HoeflerAdjust for deprecated
is_interval_dtypeandis_datetime64tz_dtype(dask#10188) Patrick Hoefler
2023.4.0#
Released on April 14, 2023
Enhancements#
Override old default values in
update_defaults(dask#10159) Gabe JosephAdd a CLI command to
listandgeta value from dask config (dask#9936) Irina TruongHandle string-based engine argument to
read_json(dask#9947) Richard (Rick) ZamoraAvoid deprecated
GroupBy.dtypes(dask#10111) Irina Truong
Bug Fixes#
Revert
grouper-related changes (dask#10182) Irina TruongGroupBy.covraising for non-numeric grouping column (dask#10171) Patrick HoeflerUpdates for
Indexsupportingnumpynumeric dtypes (dask#10154) Irina TruongPreserve
dtypefor partitioning columns when read withpyarrow(dask#10115) Patrick HoeflerFix annotations for
to_hdf(dask#10123) Hendrik MakaitHandle
Nonecolumn name when checking if columns are all numeric (dask#10128) Lawrence MitchellFix
valid_divisionswhen passed atuple(dask#10126) Brian PhillipsMaintain annotations in
DataFrame.categorize(dask#10120) Hendrik MakaitFix handling of missing min/max parquet statistics during filtering (dask#10042) Richard (Rick) Zamora
Deprecations#
Deprecate
use_nullable_dtypes=and adddtype_backend=(dask#10076) Irina TruongDeprecate
convert_dtypeinSeries.apply(dask#10133) Irina Truong
Documentation#
Document
Generatorbased random number generation (dask#10134) Eray Aslan
Maintenance#
Update
dataframe.convert_stringtodataframe.convert-string(dask#10191) Irina TruongAdd
python-cityhashto CI environments (dask#10190) Charles Blackmon-LucaTemporarily pin
scikit-imageto fix Windows CI (dask#10186) Patrick HoeflerHandle pandas deprecation warnings for
to_pydatetimeandapply(dask#10168) Patrick HoeflerDrop
bokeh<3restriction (dask#10177) James BourbeauFix failing tests under copy-on-write (dask#10173) Patrick Hoefler
Allow
pyarrowCI to fail (dask#10176) James BourbeauSwitch to
Generatorfor random number generation indask.array(dask#10003) Eray AslanBump
peter-evans/create-pull-requestfrom 4 to 5 (dask#10166)Fix flaky
modfoperation intest_arithmetic(dask#10162) Irina TruongTemporarily remove
xarrayfrom CI withpandas2.0 (dask#10153) James BourbeauFix
update_graphcounting logic intest_default_scheduler_on_worker(dask#10145) James BourbeauFix documentation build with
pandas2.0 (dask#10138) James BourbeauRemove
dask/gpufrom gpuCI update reviewers (dask#10135) Charles Blackmon-LucaUpdate gpuCI
RAPIDS_VERto23.06(dask#10129)Bump
actions/stalefrom 6 to 8 (dask#10121)Use declarative
setuptools(dask#10102) Thomas GraingerRelax
assert_eqchecks onScalar-like objects (dask#10125) Matthew RocklinUpgrade readthedocs config to ubuntu 22.04 and Python 3.11 (dask#10124) Thomas Grainger
Bump
actions/checkoutfrom 3.4.0 to 3.5.0 (dask#10122)Fix
test_null_partition_pyarrowinpyarrowCI build (dask#10116) Irina TruongDrop distributed pack (dask#9988) Florian Jetter
Make
dask.compatibilityprivate (dask#10114) Jacob Tomlinson
2023.3.2#
Released on March 24, 2023
Enhancements#
Deprecate
observed=Falseforgroupbywith categoricals (dask#10095) Irina TruongDeprecate
axis=for some groupby operations (dask#10094) James BourbeauThe
axiskeyword inDataFrame.rolling/Series.rollingis deprecated (dask#10110) Irina TruongDataFrame._datadeprecation inpandas(dask#10081) Irina TruongUse
importlib_metadatabackport to avoid CLIUserWarning(dask#10070) Thomas GraingerPort option parsing logic from
dask.dataframe.read_parquettoto_parquet(dask#9981) Anton Loukianov
Bug Fixes#
Avoid using
dd.shufflein groupby-apply (dask#10043) Richard (Rick) ZamoraEnable null hive partitions with
pyarrowparquet engine (dask#10007) Richard (Rick) ZamoraSupport unknown shapes in
*_likefunctions (dask#10064) Doug Davis
Documentation#
Add
to_backendmethods to API docs (dask#10093) Lawrence MitchellRemove broken gpuCI link in developer docs (dask#10065) Charles Blackmon-Luca
Maintenance#
Configure readthedocs sphinx warnings as errors (dask#10104) Thomas Grainger
Un-
xfailtest_division_or_partitionwithpyarrowstrings active (dask#10108) Irina TruongUn-
xfailtest_different_columns_are_allowedwithpyarrowstrings active (dask#10109) Irina TruongRestore Entrypoints compatibility (dask#10113) Jacob Tomlinson
Un-
xfailtest_to_dataframe_optimize_graphwithpyarrowstrings active (dask#10087) Irina TruongOnly run
test_development_guidelines_matches_cion editable install (dask#10106) Charles Blackmon-LucaUn-
xfailtest_dataframe_cull_key_dependencies_materializedwithpyarrowstrings active (dask#10088) Irina TruongInstall
mimesisin CI environments (dask#10105) Charles Blackmon-LucaFix for no module named
ipykernel(dask#10101) Irina TruongFix docs builds by installing
ipykernel(dask#10103) Thomas GraingerAllow
pyarrowbuild to continue on failures (dask#10097) James BourbeauBump
actions/checkoutfrom 3.3.0 to 3.4.0 (dask#10096)Fix
test_set_index_on_emptywithpyarrowstrings active (dask#10054) Irina TruongUn-
xfailpyarrowpickling tests (dask#10082) James BourbeauCI environment file cleanup (dask#10078) James Bourbeau
Un-
xfailmorepyarrowtests (dask#10066) Irina TruongTemporarily skip
pyarrow_compattests with p`andas 2.0 (dask#10063) James BourbeauFix
test_meltwithpyarrowstrings active (dask#10052) Irina TruongFix
test_str_accessorwithpyarrowstrings active (dask#10048) James BourbeauFix
test_better_errors_object_reductionswithpyarrowstrings active (dask#10051) James BourbeauFix
test_loc_with_non_boolean_serieswithpyarrowstrings active (dask#10046) James BourbeauFix
test_valueswithpyarrowstrings active (dask#10050) James BourbeauTemporarily
xfailtest_upstream_packages_installed(dask#10047) James Bourbeau
2023.3.1#
Released on March 10, 2023
Enhancements#
Support pyarrow strings in
MultiIndex(dask#10040) Irina TruongImproved support for
pyarrowstrings (dask#10000) Irina TruongFix flaky
RuntimeWarningduring array reductions (dask#10030) James BourbeauExtend
completeextras (dask#10023) James BourbeauRaise an error with
dataframe.convert-string=Trueandpandas<2.0(dask#10033) Irina TruongRename shuffle/rechunk config option/kwarg to
method(dask#10013) James BourbeauAdd initial support for converting
pandasextension dtypes to arrays (dask#10018) James BourbeauRemove
randomgensupport (dask#9987) Eray Aslan
Bug Fixes#
Skip rechunk when rechunking to the same chunks with unknown sizes (dask#10027) Hendrik Makait
Custom utility to convert parquet filters to
pyarrowexpression (dask#9885) Richard (Rick) ZamoraConsider
numpyscalars and 0d arrays as scalars when padding (dask#9653) Justus MaginFix parquet overwrite behavior after an adaptive
read_parquetoperation (dask#10002) Richard (Rick) Zamora
Documentation#
Add and update docs for Data Transfer section (dask#10022) Miles
Maintenance#
Remove stale hive-partitioning code from
pyarrowparquet engine (dask#10039) Richard (Rick) ZamoraIncrease minimum supported
pyarrowto 7.0 (dask#10024) James BourbeauRevert “Prepare drop packunpack (dask#9994) (dask#10037) Florian Jetter
Have codecov wait for more builds before reporting (dask#10031) James Bourbeau
Prepare drop packunpack (dask#9994) Florian Jetter
Add CI job with
pyarrowstrings turned on (dask#10017) James BourbeauFix
test_groupby_dropna_with_aggforpandas2.0 (dask#10001) Irina TruongFix
test_pickle_roundtripforpandas2.0 (dask#10011) James Bourbeau
2023.3.0#
Released on March 1, 2023
Bug Fixes#
Bag must not pick p2p as shuffle default (dask#10005) Florian Jetter
Documentation#
Minor follow-up to P2P by default (dask#10008) James Bourbeau
Maintenance#
Add minimum version to optional
jinja2dependency (dask#9999) Charles Blackmon-Luca
2023.2.1#
Released on February 24, 2023
Note
This release changes the default DataFrame shuffle algorithm to p2p
to improve stability and performance. Learn more here
and please provide any feedback on this discussion.
If you encounter issues with this new algorithm, please see the documentation for more information, and how to switch back to the old mode.
Enhancements#
Enable P2P shuffling by default (dask#9991) Florian Jetter
P2P rechunking (dask#9939) Hendrik Makait
Efficient dataframe.convert-string support for read_parquet (dask#9979) Irina Truong
Allow p2p shuffle kwarg for DataFrame merges (dask#9900) Florian Jetter
Change
split_row_groupsdefault to “infer” (dask#9637) Richard (Rick) ZamoraAdd option for converting string data to use
pyarrowstrings (dask#9926) James BourbeauAdd support for multi-column
sort_values(dask#8263) Charles Blackmon-LucaGeneratorbased random-number generation in``dask.array`` (dask#9038) Eray AslanSupport
numeric_onlyfor simple groupby aggregations forpandas2.0 compatibility (dask#9889) Irina Truong
Bug Fixes#
Fix profilers plot not being aligned to context manager enter time (dask#9739) David Hoese
Relax dask.dataframe assert_eq type checks (dask#9989) Matthew Rocklin
Restore
describecompatibility forpandas2.0 (dask#9982) James Bourbeau
Documentation#
Improving deploying Dask docs (dask#9912) Sarah Charlotte Johnson
More docs for
DataFrame.partitions(dask#9976) Tom AugspurgerUpdate docs with more information on default Delayed scheduler (dask#9903) Guillaume Eynard-Bontemps
Deployment Considerations documentation (dask#9933) Gabe Joseph
Maintenance#
Temporarily rerun flaky tests (dask#9983) James Bourbeau
Update parsing of FULL_RAPIDS_VER/FULL_UCX_PY_VER (dask#9990) Charles Blackmon-Luca
Increase minimum supported versions to
pandas=1.3andnumpy=1.21(dask#9950) James BourbeauFix
stdto work withnumeric_onlyforpandas2.0 (dask#9960) Irina TruongTemporarily
xfailtest_roundtrip_partitioned_pyarrow_dataset(dask#9977) James BourbeauFix copy on write failure in test_idxmaxmin (dask#9944) Patrick Hoefler
Bump
pre-commitversions (dask#9955) crusaderkyFix
test_groupby_unaligned_indexforpandas2.0 (dask#9963) Irina TruongUn-
xfailtest_set_index_overlap_2forpandas2.0 (dask#9959) James BourbeauFix
test_merge_by_index_patternsforpandas2.0 (dask#9930) Irina TruongBump jacobtomlinson/gha-find-replace from 2 to 3 (dask#9953) James Bourbeau
Fix
test_rolling_agg_aggregateforpandas2.0 compatibility (dask#9948) Irina TruongBump
blackto23.1.0(dask#9956) crusaderkyRun GPU tests on python 3.8 & 3.10 (dask#9940) Charles Blackmon-Luca
Fix
test_to_timestampforpandas2.0 (dask#9932) Irina TruongFix an error with
groupbyvalue_countsforpandas2.0 compatibility (dask#9928) Irina TruongConfig converter: replace all dashes with underscores (dask#9945) Jacob Tomlinson
CI: use nightly wheel to install pyarrow in upstream test build (dask#9873) Joris Van den Bossche
2023.2.0#
Released on February 10, 2023
Enhancements#
Update
numeric_onlydefault inquantileforpandas2.0 (dask#9854) Irina TruongMake
repartitiona no-op when divisions match (dask#9924) James BourbeauUpdate
datetime_is_numericbehavior indescribeforpandas2.0 (dask#9868) Irina TruongUpdate
value_countsto return correct name inpandas2.0 (dask#9919) Irina TruongSupport new
axis=Nonebehavior inpandas2.0 for certain reductions (dask#9867) James BourbeauFilter out all-nan
RuntimeWarningat the chunk level fornanminandnanmax(dask#9916) Julia SignellFix numeric
meta_nonemptyindexcreationforpandas2.0 (dask#9908) James BourbeauFix
DataFrame.info()tests forpandas2.0 (dask#9909) James Bourbeau
Bug Fixes#
Fix
GroupBy.value_countshandling for multiplegroupbycolumns (dask#9905) Charles Blackmon-Luca
Documentation#
Fix some outdated information/typos in development guide (dask#9893) Patrick Hoefler
Add note about
keep=Falseindrop_duplicatesdocstring (dask#9887) Jayesh MananiAdd
metadetails to dask Array (dask#9886) Jayesh MananiClarify task stream showing more rows than threads (dask#9906) Gabe Joseph
Maintenance#
Fix
test_numeric_column_namesforpandas2.0 (dask#9937) Irina TruongFix
dask/dataframe/tests/test_utils_dataframe.pytests forpandas2.0 (dask#9788) James BourbeauReplace
index.is_numericwithis_any_real_numeric_dtypeforpandas2.0 compatibility (dask#9918) Irina TruongAvoid
pd.coreimport in dask utils (dask#9907) Matthew RoeschkeUse label for
upstreambuild on pull requests (dask#9910) James BourbeauBroaden exception catching for
sqlalchemy.exc.RemovedIn20Warning(dask#9904) James BourbeauTemporarily restrict
sqlalchemy < 2in CI (dask#9897) James BourbeauUpdate
isortversion to 5.12.0 (dask#9895) Lawrence MitchellRemove unused
skiprowsvariable inread_csv(dask#9892) Patrick Hoefler
2023.1.1#
Released on January 27, 2023
Enhancements#
Add
to_backendmethod toArrayand_Frame(dask#9758) Richard (Rick) ZamoraSmall fix for timestamp index divisions in
pandas2.0 (dask#9872) Irina TruongAdd
numeric_onlytoDataFrame.covandDataFrame.corr(dask#9787) James BourbeauFixes related to
group_keysdefault change inpandas2.0 (dask#9855) Irina Truonginfer_datetime_formatcompatibility forpandas2.0 (dask#9783) James Bourbeau
Bug Fixes#
Fix serialization bug in
BroadcastJoinLayer(dask#9871) Richard (Rick) ZamoraSatisfy
broadcastargument inDataFrame.merge(dask#9852) Richard (Rick) ZamoraFix
pyarrowparquet columns statistics computation (dask#9772) aywandji
Documentation#
Fix “duplicate explicit target name” docs warning (dask#9863) Chiara Marmo
Fix code formatting issue in “Defining a new collection backend” docs (dask#9864) Chiara Marmo
Update dashboard documentation for memory plot (dask#9768) Jayesh Manani
Add docs section about
no-workertasks (dask#9839) Florian Jetter
Maintenance#
Additional updates for detecting a
distributedscheduler (dask#9890) James BourbeauUpdate gpuCI
RAPIDS_VERto23.04(dask#9876)Reverse precedence between collection and
distributeddefault (dask#9869) Florian JetterUpdate
xarray-contrib/issue-from-pytest-logto version 1.2.6 (dask#9865) James BourbeauDont require dask config shuffle default (dask#9826) Florian Jetter
Un-
xfaildatetime64Parquet roundtripping tests for newfastparquet(dask#9811) James BourbeauAdd option to manually run
upstreamCI build (dask#9853) James BourbeauUse custom timeout in CI builds (dask#9844) James Bourbeau
Remove
kwargsfrommake_blockwise_graph(dask#9838) Florian JetterIgnore warnings on
persistcall intest_setitem_extended_API_2d_mask(dask#9843) Charles Blackmon-LucaFix running S3 tests locally (dask#9833) James Bourbeau
2023.1.0#
Released on January 13, 2023
Enhancements#
Use
distributeddefault clients even if no config is set (dask#9808) Florian JetterImplement
ma.whereandma.nonzero(dask#9760) Erik HolmgrenUpdate
zarrstore creation functions (dask#9790) Ryan Abernatheyiteritemscompatibility forpandas2.0 (dask#9785) James BourbeauAccurate
sizeofforpandasstring[python]dtype (dask#9781) crusaderkyDeflate
sizeof()of duplicate references to pandas object types (dask#9776) crusaderkyGroupBy.__getitem__compatibility forpandas2.0 (dask#9779) James Bourbeauappendcompatibility forpandas2.0 (dask#9750) James Bourbeauget_dummiescompatibility forpandas2.0 (dask#9752) James Bourbeauis_monotoniccompatibility forpandas2.0 (dask#9751) James Bourbeaunumpy=1.24compatability (dask#9777) James Bourbeau
Documentation#
Remove duplicated
encodingkwarg in docstring forto_json(dask#9796) Sultan OrazbayevMention
SubprocessClusterinLocalClusterdocumentation (dask#9784) Hendrik MakaitMove Prometheus docs to
dask/distributed(dask#9761) crusaderky
Maintenance#
Temporarily ignore
RuntimeWarningintest_setitem_extended_API_2d_mask(dask#9828) James BourbeauFix flaky
test_threaded.py::test_interrupt(dask#9827) Hendrik MakaitUpdate
xarray-contrib/issue-from-pytest-loginupstreamreport (dask#9822) James Bourbeaupipinstall dask on gpuCI builds (dask#9816) Charles Blackmon-LucaBump
actions/checkoutfrom 3.2.0 to 3.3.0 (dask#9815)Resolve
sqlalchemyimport failures inmindepstesting (dask#9809) Charles Blackmon-LucaIgnore
sqlalchemy.exc.RemovedIn20Warning(dask#9801) Thomas Graingerxfaildatetime64Parquet roundtripping tests forpandas2.0 (dask#9786) James BourbeauReduce size of expected DoK sparse matrix (dask#9775) Elliott Sales de Andrade
Remove executable flag from
dask/dataframe/io/orc/utils.py(dask#9774) Elliott Sales de Andrade
2022.12.1#
Released on December 16, 2022
Enhancements#
Support
dtype_backend="pandas|pyarrow"configuration (dask#9719) James BourbeauSupport
cupy.ndarraytocudf.DataFramedispatching indask.dataframe(dask#9579) Richard (Rick) ZamoraMake filesystem-backend configurable in
read_parquet(dask#9699) Richard (Rick) ZamoraSerialize all
pyarrowextension arrays efficiently (dask#9740) James Bourbeau
Bug Fixes#
Fix bug when repartitioning with
tz-aware datetime index (dask#9741) James BourbeauPartial functions in aggs may have arguments (dask#9724) Irina Truong
Add support for simple operation with
pyarrow-backed extension dtypes (dask#9717) James BourbeauRename columns correctly in case of
SeriesGroupby(dask#9716) Lawrence Mitchell
Documentation#
Fix url link typo in collection backend doc (dask#9748) Shawn
Update Prometheus docs (dask#9696) Hendrik Makait
Maintenance#
Add
zarrto Python 3.11 CI environment (dask#9771) James BourbeauAdd support for Python 3.11 (dask#9708) Thomas Grainger
Bump
actions/checkoutfrom 3.1.0 to 3.2.0 (dask#9753)Avoid
np.bool8deprecation warning (dask#9737) James BourbeauMake sure dev packages aren’t overwritten in
upstreamCI build (dask#9731) James BourbeauAvoid adding
data.h5andmydask.htmlfiles during tests (dask#9726) Thomas Grainger
2022.12.0#
Released on December 2, 2022
Enhancements#
Remove statistics-based
set_indexlogic fromread_parquet(dask#9661) Richard (Rick) ZamoraAdd support for
use_nullable_dtypestodd.read_parquet(dask#9617) Ian RoseFix
map_overlapin order to accept pandas arguments (dask#9571) Fabien AulaireFix pandas 1.5+
FutureWarningin.str.split(..., expand=True)(dask#9704) Jacob HayesEnable column projection for
groupbyslicing (dask#9667) Richard (Rick) ZamoraImprove error message for failed backend dispatch call (dask#9677) Richard (Rick) Zamora
Bug Fixes#
Revise meta creation in arrow parquet engine (dask#9672) Richard (Rick) Zamora
Fix
da.fft.fftfor array-like inputs (dask#9688) James BourbeauFix
groupby-aggregation when grouping on an index by name (dask#9646) Richard (Rick) Zamora
Maintenance#
Avoid
PytestReturnNotNoneWarningintest_inheriting_class(dask#9707) Thomas GraingerFix flaky
test_dataframe_aggregations_multilevel(dask#9701) Richard (Rick) ZamoraBump
mypyversion (dask#9697) crusaderkyDisable dashboard in
test_map_partitions_df_input(dask#9687) James BourbeauUse latest
xarray-contrib/issue-from-pytest-loginupstreambuild (dask#9682) James Bourbeauxfailttest_1sampfor upstreamscipy(dask#9670) James BourbeauUpdate gpuCI
RAPIDS_VERto23.02(dask#9678)
2022.11.1#
Released on November 18, 2022
Enhancements#
Restrict
bokeh=3support (dask#9673) Gabe JosephUpdates for
fastparquetevolution (dask#9650) Martin Durant
Maintenance#
Update
ga-yaml-parserstep in gpuCI updating workflow (dask#9675) Charles Blackmon-LucaRevert
importlib.metadataworkaround (dask#9658) James BourbeauFix
mindeps-distributedCI build to handlenumpy/pandasnot being installed (dask#9668) James Bourbeau
2022.11.0#
Released on November 15, 2022
Enhancements#
Generalize
from_dictimplementation to allow usage from other backends (dask#9628) GALI PREM SAGAR
Bug Fixes#
Avoid
pandasconstructors indask.dataframe.core(dask#9570) Richard (Rick) ZamoraFix
sort_valueswithTimestampdata (dask#9642) James BourbeauGeneralize array checking and remove
pd.Indexcall in_get_partitions(dask#9634) Benjamin ZaitlenFix
read_csvbehavior forheader=0andnames(dask#9614) Richard (Rick) Zamora
Documentation#
Update dashboard docs for queuing (dask#9660) Gabe Joseph
Remove
import dask as dfrom docstrings (dask#9644) Matthew RocklinFix link to partitions docs in
read_parquetdocstring (dask#9636) qheuristicsAdd API doc links to
array/bag/dataframesections (dask#9630) Matthew Rocklin
Maintenance#
Use
conda-incubator/setup-miniconda@v2.2.0(dask#9662) John A KirkhamAllow
bokeh=3(dask#9659) James BourbeauRun
upstreambuild with Python 3.10 (dask#9655) James BourbeauPin
pyyamlversion in mindeps testing (dask#9640) Charles Blackmon-LucaAdd
pre-committo catchbreakpoint()(dask#9638) James BourbeauBump
xarray-contrib/issue-from-pytest-logfrom 1.1 to 1.2 (dask#9635)Remove
bloscreferences (dask#9625) Naty ClementiUpgrade
mypyand drop unused comments (dask#9616) Hendrik MakaitHarden
test_repartition_npartitions(dask#9585) Richard (Rick) Zamora
2022.10.2#
Released on October 31, 2022
This was a hotfix and has no changes in this repository. The necessary fix was in dask/distributed, but we decided to bump this version number for consistency.
2022.10.1#
Released on October 28, 2022
Enhancements#
Add extension dtype support to
set_index(dask#9566) James BourbeauRedesigning the array HTML repr for clarity (dask#9519) Shingo OKAWA
Bug Fixes#
Documentation#
Add note about limiting thread oversubscription by default (dask#9592) James Bourbeau
Use
sphinx-clickfordaskCLI (dask#9589) James BourbeauFix Semaphore API docs (dask#9584) James Bourbeau
Render meta description in
map_overlapdocstring (dask#9568) James Bourbeau
Maintenance#
Require Click 7.0+ in Dask (dask#9595) John A Kirkham
Temporarily restrict
bokeh<3(dask#9607) James BourbeauResolve
importlib-related failures inupstreamCI (dask#9604) Charles Blackmon-LucaImprove
upstreamCI report (dask#9603) James BourbeauFix
upstreamCI report (dask#9602) James BourbeauRemove
setuptoolshost dep, add CLI entrypoint (dask#9600) Charles Blackmon-LucaMore
Backenddispatch class type annotations (dask#9573) Ian Rose
2022.10.0#
Released on October 14, 2022
New Features#
Backend library dispatching for IO in Dask-Array and Dask-DataFrame (dask#9475) Richard (Rick) Zamora
Add new CLI that is extensible (dask#9283) Doug Davis
Enhancements#
Fix array copy not being a no-op (dask#9555) David Hoese
Add support for string timedelta in
map_overlap(dask#9559) Nicolas GrandemangeShuffle-based groupby for single functions (dask#9504) Ian Rose
Make
datetime.datetimetokenize idempotantly (dask#9532) Martin Durant
Bug Fixes#
Avoid race condition in lazy dispatch registration (dask#9545) James Bourbeau
Do not allow setitem to
np.nanforintdtype (dask#9531) Doug DavisFix project CSV columns when selecting (dask#9534) Martin Durant
Documentation#
Update Parquet best practice (dask#9537) Matthew Rocklin
Maintenance#
Restrict
tiledb-pyversion to avoid CI failures (dask#9569) James BourbeauBump
actions/github-scriptfrom 3 to 6 (dask#9564)Bump
actions/stalefrom 4 to 6 (dask#9551)Bump
peter-evans/create-pull-requestfrom 3 to 4 (dask#9550)Bump
actions/checkoutfrom 2 to 3.1.0 (dask#9552)Bump
codecov/codecov-actionfrom 1 to 3 (dask#9549)Bump
the-coding-turtle/ga-yaml-parserfrom 0.1.1 to 0.1.2 (dask#9553)Move dependabot configuration file (dask#9547) James Bourbeau
Add dependabot for GitHub actions (dask#9542) James Bourbeau
Run mypy on Windows and Linux (dask#9530) crusaderky
Update gpuCI
RAPIDS_VERto22.12(dask#9524)
2022.9.2#
Released on September 30, 2022
Enhancements#
Remove factorization logic from array auto chunking (dask#9507) James Bourbeau
Documentation#
Add docs on running Dask in a standalone Python script (dask#9513) James Bourbeau
Clarify custom-graph multiprocessing example (dask#9511) nouman
Maintenance#
2022.9.1#
Released on September 16, 2022
New Features#
Add
DataFrameandSeriesmedianmethods (dask#9483) James Bourbeau
Enhancements#
Filter by list (dask#9419) Greg Hayes
Added
distributed.utils.key_splitfunctionality todask.utils.key_split(dask#9464) Luke Conibear
Bug Fixes#
Fix overlap so that
set_indexdoesn’t drop rows (dask#9423) Julia SignellFix assigning pandas
Seriesto column whenddf.columns.min()raises (dask#9485) Erik WelchFix metadata comparison
stack_partitions(dask#9481) James BourbeauProvide default for
split_out(dask#9493) Lawrence Mitchell
Deprecations#
Documentation#
Fixing
enforce_metadatadocumentation, not checking for dtypes (dask#9474) Nicolas GrandemangeFix
it's–>itstypo (dask#9484) Nat Tabris
Maintenance#
Workaround for parquet writing failure using some datetime series but not others (dask#9500) Ian Rose
Filter out
numeric_onlywarnings frompandas(dask#9496) James BourbeauAvoid
set_index(..., inplace=True)where not necessary (dask#9472) James BourbeauAvoid passing groupby key list of length one (dask#9495) James Bourbeau
Update
test_groupby_dropna_cudfbased oncudfsupport forgroup_keys(dask#9482) James BourbeauRemove
dd.from_bcolz(dask#9479) James BourbeauAdded
flake8-bugbeartopre-commithooks (dask#9457) Luke ConibearBind loop variables in function definitions (
B023) (dask#9461) Luke ConibearAdded assert for comparisons (
B015) (dask#9459) Luke ConibearSet top-level default shell in CI workflows (dask#9469) James Bourbeau
Removed unused loop control variables (
B007) (dask#9458) Luke ConibearReplaced
getattrcalls for constant attributes (B009) (dask#9460) Luke ConibearPin
libprotobufto allow nightlypyarrowin the upstream CI build (dask#9465) Joris Van den BosscheReplaced mutable data structures for default arguments (
B006) (dask#9462) Luke ConibearChanged
flake8mirror and updated version (dask#9456) Luke Conibear
2022.9.0#
Released on September 2, 2022
Enhancements#
Enable automatic column projection for
groupbyaggregations (dask#9442) Richard (Rick) ZamoraAccept superclasses in NEP-13/17 dispatching (dask#6710) Gabe Joseph
Bug Fixes#
Rename
bycolumns internally for cumulative operations on the samebycolumns (dask#9430) Pavithra EswaramoorthyFix
get_groupwith categoricals (dask#9436) Pavithra EswaramoorthyFix caching-related
MaterializedLayer.cullperformance regression (dask#9413) Richard (Rick) Zamora
Documentation#
Add maintainer documentation page (dask#9309) James Bourbeau
Maintenance#
Revert skipped fastparquet test (dask#9439) Pavithra Eswaramoorthy
tmpfiledoes not end files with period on empty extension (dask#9429) Hendrik MakaitSkip failing fastparquet test with latest release (dask#9432) James Bourbeau
2022.8.1#
Released on August 19, 2022
New Features#
Implement
ma.*_like functions(dask#9378) Ruth Comer
Enhancements#
Shuffle-based groupby aggregation for high-cardinality groups (dask#9302) Richard (Rick) Zamora
Unpack
namedtuple(dask#9361) Hendrik Makait
Bug Fixes#
Fix
SeriesGroupBycumulative functions withaxis=1(dask#9377) Pavithra EswaramoorthyFix
make_metawhile using categorical column with index (dask#9348) Pavithra EswaramoorthyDon’t allow incompatible keywords in
DataFrame.dropna(dask#9366) Naty ClementiMake
set_indexhandle entirely empty dataframes (dask#8896) Julia SignellImprove
dataclasshandling inunpack_collections(dask#9345) Hendrik MakaitFix bag sampling when there are some smaller partitions (dask#9349) Ian Rose
Add support for empty partitions to
da.min/da.maxfunctions (dask#9268) geraninam
Documentation#
Clarify that
bind()etc. regenerate the keys (dask#9385) crusaderkyConsolidate dashboard diagnostics documentation (dask#9357) Sarah Charlotte Johnson
Remove outdated
metainformation Pavithra Eswaramoorthy
Maintenance#
Use
entry_pointsutility insizeof(dask#9390) James BourbeauAdd
entry_pointscompatibility utility (dask#9388) Jacob TomlinsonUpload environment file artifact for each CI build (dask#9372) James Bourbeau
Remove
werkzeugpin in CI (dask#9371) James BourbeauFix type annotations for
dd.from_pandasanddd.from_delayed(dask#9362) Jordan Yap
2022.8.0#
Released on August 5, 2022
Enhancements#
Ensure
make_metadoesn’t hold ref to data (dask#9354) Jim Crist-HarifRevise
divisionslogic infrom_pandas(dask#9221) Richard (Rick) ZamoraWarn if user sets index with existing index (dask#9341) Julia Signell
Add
keepdimskeyword forda.average(dask#9332) Ruth ComerChange
reprmethods to avoidLayermaterialization (dask#9289) Richard (Rick) Zamora
Bug Fixes#
Make sure
orderkwarg will not crash theastypemethod (dask#9317) Genevieve BuckleyFix bug for
cumsumon cupy chunked dask arrays (dask#9320) Genevieve BuckleyMatch input and output structure in
_sample_reduce(dask#9272) Pavithra EswaramoorthyInclude
metain array serialization (dask#9240) Frédéric BRIOLFix
Index.memory_usage(dask#9290) James BourbeauFix division calculation in
dask.dataframe.io.from_dask_array(dask#9282) Jordan Yap
Documentation#
Fow to use kwargs with custom task graphs (dask#9322) Genevieve Buckley
Add note to
da.from_arrayabout how the order is not preserved (dask#9346) Julia SignellAdd I/O info for async functions (dask#9326) Logan Norman
Tidy up docs snippet for futures IO functions (dask#9340) Julia Signell
Use consistent variable names for pandas
dfand Daskddfindataframe-groupby.rst(dask#9304) ivojuroroSwitch
js-yamlforyaml.jsin config converter (dask#9306) Jacob Tomlinson
Maintenance#
Update
da.linalg.solvefor SciPy 1.9.0 compatibility (dask#9350) Pavithra EswaramoorthyUpdate
test_getitem_avoids_large_chunks_missing(dask#9347) Pavithra EswaramoorthyFix docs title formatting for “Extend
sizeof” Doug DavisImport
loop_in_threadfixture in tests (dask#9337) James BourbeauTemporarily
xfailtest_solve_sym_pos(dask#9336) Pavithra EswaramoorthyFix small typo in 10 minutes to Dask page (dask#9329) Shaghayegh
Temporarily pin
werkzeugin CI to avoid test suite hanging (dask#9325) James BourbeauAdd tests for
cupy.angle()(dask#9312) Peter Andreas EntschevUpdate gpuCI
RAPIDS_VERto22.10(dask#9314)Add
pandas[test]totestextra (dask#9110) Ben BeasleyAdd
bokehandscipytoupstreamCI build (dask#9265) James Bourbeau
2022.7.1#
Released on July 22, 2022
Enhancements#
Return Dask array if all axes are squeezed (dask#9250) Pavithra Eswaramoorthy
Make cycle reported by toposort shorter (dask#9068) Erik Welch
Unknown chunk slicing - raise informative error (dask#9285) Naty Clementi
Bug Fixes#
Fix bug in
HighLevelGraph.cull(dask#9267) Richard (Rick) ZamoraSort categories (dask#9264) Pavithra Eswaramoorthy
Use
max(instead ofsum) for calculatingwarnsize(dask#9235) Pavithra EswaramoorthyFix bug when filtering on partitioned column with pyarrow (dask#9252) Richard (Rick) Zamora
Documentation#
Updated repartition documentation to add note about
partition_size(dask#9288) Dylan StewartDon’t include docs in
Arraymethods, just refer to module docs (dask#9244) Julia SignellRemove outdated reference to scheduler and worker dashboards (dask#9278) Pavithra Eswaramoorthy
Adds an custom aggregate example using numpy methods (dask#9260) geraninam
Maintenance#
Add type annotations to
dd.from_pandasanddd.from_delayed(dask#9237) Michael MiltonUpdate
calculate_divisionsdocstring (dask#9275) Tom AugspurgerUpdate
test_plot_multiplefor upcomingbokehrelease (dask#9261) James Bourbeau
2022.7.0#
Released on July 8, 2022
Enhancements#
Support
pathlib.PurePathinnormalize_token(dask#9229) Angus HollandsAdd
AttributeNotImplementedErrorfor properties so IPython glob search works (dask#9231) Erik Welchmap_overlap: multiple dataframe handling (dask#9145) Fabien AulaireRead entrypoints in
dask.sizeof(dask#7688) Angus Hollands
Bug Fixes#
Fix
TypeError: 'Serialize' object is not subscriptablewhen writing parquet dataset withClient(processes=False)(dask#9015) Lucas Miguel PonceCorrect dtypes when
concatwith an empty dataframe (dask#9193) Pavithra Eswaramoorthy
Documentation#
Highlight note about persist (dask#9234) Pavithra Eswaramoorthy
Update release-procedure to include more detail and helpful commands (dask#9215) Julia Signell
Better SEO for Futures and Dask vs. Spark pages (dask#9217) Sarah Charlotte Johnson
Maintenance#
Use
math.prodinstead ofnp.prodon lists, tuples, and iters (dask#9232) crusaderkyOnly import IPython if type checking (dask#9230) Florian Jetter
Tougher mypy checks (dask#9206) crusaderky
2022.6.1#
Released on June 24, 2022
Enhancements#
Create
dask.utils.show_versions(dask#9144) Sultan OrazbayevBetter error message for unsupported numpy operations on dask.dataframe objects. (dask#9201) Julia Signell
Add
allow_rechunkkwarg todask.array.overlapfunction (dask#7776) Genevieve BuckleyAdd minutes and hours to
dask.utils.format_time(dask#9116) Matthew RocklinMore retries when writing parquet to remote filesystem (dask#9175) Ian Rose
Bug Fixes#
Timedelta deterministic hashing (dask#9213) Fabien Aulaire
Enum deterministic hashing (dask#9212) Fabien Aulaire
shuffle_group(): avoid converting to arrays (dask#9157) Mads R. B. Kristensen
Deprecations#
Deprecate extra
format_timeutility (dask#9184) James Bourbeau
Documentation#
Better SEO for 10 Minutes to Dask (dask#9182) Sarah Charlotte Johnson
Better SEO for Delayed and Best Practices (dask#9194) Sarah Charlotte Johnson
Include known inconsistency in DataFrame
str.splitaccessor docstring (dask#9177) Richard PelgrimAdd
inconsistencieskeyword toderived_from(dask#9192) Richard PelgrimAdd missing
appendindelayedbest practices example (dask#9202) BenFix indentation in Best Practices (dask#9196) Sarah Charlotte Johnson
Add link to Genevieve Buckley’s blog on chunk sizes (dask#9199) Pavithra Eswaramoorthy
Update
to_csvdocstring (dask#9094) Sarah Charlotte Johnson
Maintenance#
Update versioneer: change from using
SafeConfigParsertoConfigParser(dask#9205) Thomas A CaswellRemove ipython hack in CI(dask#9200) crusaderky
2022.6.0#
Released on June 10, 2022
Enhancements#
Add feature to show names of layer dependencies in HLG JupyterLab repr (dask#9081) Angelos Omirolis
Add arrow schema extraction dispatch (dask#9169) GALI PREM SAGAR
Add
sort_resultsargument toassert_eq(dask#9130) Pavithra EswaramoorthyAdd weeks to
parse_timedelta(dask#9168) Matthew RocklinWarn that cloudpickle is not always deterministic (dask#9148) Pavithra Eswaramoorthy
Switch parquet default engine (dask#9140) Jim Crist-Harif
Use deterministic hashing with
_iLocIndexer/_LocIndexer(dask#9108) Fabien AulaireEnfore consistent schema in
to_parquetpyarrow (dask#9131) Jim Crist-Harif
Bug Fixes#
Fix
pyarrow.StringArraypickle (dask#9170) Jim Crist-HarifFix parallel metadata collection in pyarrow engine (dask#9165) Richard (Rick) Zamora
Improve
pyarrowpartitioning logic (dask#9147) James Bourbeaupyarrow8.0 partitioning fix (dask#9143) James Bourbeau
Documentation#
Better SEO for Installing Dask and Dask DataFrame Best Practices (dask#9178) Sarah Charlotte Johnson
Update logos page in docs (dask#9167) Sarah Charlotte Johnson
Add example using pandas Series to
map_partitiondoctring (dask#9161) Alex-JG3Update docs theme for rebranding (dask#9160) Sarah Charlotte Johnson
Better SEO for docs on Dask DataFrames (dask#9128) Sarah Charlotte Johnson
Maintenance#
Remove ensure_file from recommended practice for downstream libraries (dask#9171) Matthew Rocklin
Test round-tripping DataFrame parquet I/O including pyspark (dask#9156) Ian Rose
Link best practices to DataFrame-parquet (dask#9150) Tom Augspurger
Fix typo in
map_partitionsfuncparameter description (dask#9149) Christopher AkikiUn-
xfailtest_groupby_grouper_dispatch(dask#9139) GALI PREM SAGARTemporarily import cleanup fixture from distributed (dask#9138) James Bourbeau
Simplify partitioning logic in pyarrow parquet engine (dask#9041) Richard (Rick) Zamora
2022.05.2#
Released on May 26, 2022
Enhancements#
Add a dispatch for non-pandas
Grouperobjects and use it inGroupBy(dask#9074) brandon-b-millerError if
read_parquet&to_parquetfiles intersect (dask#9124) Jim Crist-HarifVisualize task graphs using
ipycytoscape(dask#9091) Ian Rose
Documentation#
Fix various typos (dask#9126) Ryan Russell
Maintenance#
Fix flaky
test_filter_nonpartition_columns(dask#9127) Pavithra EswaramoorthyUpdate gpuCI
RAPIDS_VERto22.08(dask#9120)Include
conftest.py`in sdists (dask#9115) Ben Beasley
2022.05.1#
Released on May 24, 2022
New Features#
Add
DataFrame.from_dictclassmethod (dask#9017) Matthew PowersAdd
from_mapfunction to Dask DataFrame (dask#8911) Richard (Rick) Zamora
Enhancements#
Improve
to_parqueterror for appended divisions overlap (dask#9102) Jim Crist-HarifEnabled user-defined process-initializer functions (dask#9087) ParticularMiner
Mention
align_dataframes=Falseoption inmap_partitionserror (dask#9075) Gabe JosephAdd kwarg
enforce_ndimtodask.array.map_blocks()(dask#8865) ParticularMinerImplement
Series.GroupBy.fillna/DataFrame.GroupBy.fillnamethods (dask#8869) Pavithra EswaramoorthyAllow
fillnawith Dask DataFrame (dask#8950) Pavithra EswaramoorthyUpdate error message for assignment with 1-d dask array (dask#9036) Pavithra Eswaramoorthy
Collection Protocol (dask#8674) Doug Davis
Patch around
pandasArrowStringArraypickling (dask#9024) Jim Crist-HarifAdd
p2pshuffle option (dask#8836) Matthew Rocklin
Bug Fixes#
Fixup column projection with no columns (dask#9106) Jim Crist-Harif
Fix column-projection bug in
from_map(dask#9078) Richard (Rick) ZamoraPrevent nulls in index for non-numeric dtypes (dask#8963) Jorge López
Fix
is_monotonicmethods for more than 8 partitions (dask#9019) Julia SignellHandle enumerate and generator inputs to
from_map(dask#9066) Richard (Rick) ZamoraRevert
is_dask_collection; back to previous implementation (dask#9062) Doug DavisFix
Blockwise.clonedoes not handle iterable literal arguments correctly (dask#8979) JSKenyonArray
setitemhardmask (dask#9027) David HassellFix overlapping divisions error on append (dask#8997) Ian Rose
Deprecations#
Add pre-deprecation warnings for
read_parquetkwargschunksizeandaggregate_files(dask#9052) Richard (Rick) Zamora
Documentation#
Document
map_partitionshandling ofargsvskwargs, usage ofpartition_info(dask#9084) Charles Blackmon-LucaUpdate custom collection documentation (leverage new collection protocol) (dask#9097) Doug Davis
Better SEO for docs on creating and storing Dask DataFrames (dask#9098) Sarah Charlotte Johnson
Clarify chunking in
imreaddocstring (dask#9082) Genevieve BuckleyRearrange docs TOC (dask#9001) Matthew Rocklin
Corrected
map_blocks()docstring for kwargenforce_ndim(dask#9071) ParticularMinerUpdate DataFrame SQL docs references to other libraries (dask#9077) Charles Blackmon-Luca
Update page on creating and storing Dask DataFrames (dask#9025) Sarah Charlotte Johnson
Maintenance#
Include
NUMPY_LICENSE.txtin license files (dask#9113) Ben BeasleyIncrease retries when installing nightly
pandas(dask#9103) James BourbeauForce nightly
pyarrowin the upstream build (dask#9095) Joris Van den BosscheImprove object handling & testing of
ensure_unicode(dask#9059) John A KirkhamForce nightly
pyarrowin the upstream build (dask#8993) Joris Van den BosscheAdditional check on
is_dask_collection(dask#9054) Doug DavisUpdate
ensure_bytes(dask#9050) John A KirkhamAdd end of file pre-commit hook (dask#9045) James Bourbeau
Add
codespellpre-commit hook (dask#9040) James BourbeauRemove the HDFS tests (dask#9039) Jim Crist-Harif
Fix flaky
test_reductions_2D(dask#9037) Jim Crist-HarifPrevent codecov from notifying of failure too soon (dask#9031) Jim Crist-Harif
Only test on Python 3.9 on macos (dask#9029) Jim Crist-Harif
Update
to_timedeltadefault unit (dask#9010) Pavithra Eswaramoorthy
2022.05.0#
Released on May 2, 2022
Highlights#
This is a bugfix release for this issue.
Documentation#
Add highlights section to 2022.04.2 release notes (dask#9012) James Bourbeau
2022.04.2#
Released on April 29, 2022
Highlights#
This release includes several deprecations/breaking API changes to
dask.dataframe.read_parquet and dask.dataframe.to_parquet:
to_parquetno longer writes_metadatafiles by default. If you want to write a_metadatafile, you can pass inwrite_metadata_file=True.read_parquetnow defaults tosplit_row_groups=False, which results in one Dask dataframe partition per parquet file when reading in a parquet dataset. If you’re working with large parquet files you may need to setsplit_row_groups=Trueto reduce your partition size.read_parquetno longer calculates divisions by default. If you requireread_parquetto return dataframes with known divisions, please setcalculate_divisions=True.read_parquethas deprecated thegather_statisticskeyword argument. Please use thecalculate_divisionskeyword argument instead.read_parquethas deprecated therequire_extensionskeyword argument. Please use theparquet_file_extensionkeyword argument instead.
New Features#
Add
removeprefixandremovesuffixasStringMethods(dask#8912) Jorge López
Enhancements#
Call
fs.invalidate_cacheinto_parquet(dask#8994) Jim Crist-HarifChange
to_parquetdefault towrite_metadata_file=None(dask#8988) Jim Crist-HarifLet arg reductions pass
keepdims(dask#8926) Julia SignellChange
split_row_groupsdefault toFalseinread_parquet(dask#8981) Richard (Rick) ZamoraImprove
NotImplementedErrormessage forda.reshape(dask#8987) Jim Crist-HarifSimplify
to_parquetcompute path (dask#8982) Jim Crist-HarifRaise an error if you try to use
vindexwith a Dask object (dask#8945) Julia SignellAvoid
pre_buffer=Truewhen a precache method is specified (dask#8957) Richard (Rick) Zamorafrom_dask_arrayusesblockwiseinstead of merging graphs (dask#8889) Bryan WeberUse
pre_buffer=Truefor “pyarrow” Parquet engine (dask#8952) Richard (Rick) Zamora
Bug Fixes#
Handle
dtype=Nonecorrectly inda.full(dask#8954) Tom WhiteFix
dask-sqlbug caused byblockwisefusion (dask#8989) Richard (Rick) Zamorato_parqueterrors for non-string column names (dask#8990) Jim Crist-HarifMake sure
da.rollworks even if shape is 0 (dask#8925) Julia SignellFix recursion error issue with
set_index(dask#8967) Paul HobsonStringify
BlockwiseDepDictmapping values whenproduces_keys=True(dask#8972) Richard (Rick) ZamoraUse DataFram`eIOLayer in
DataFrame.from_delayed(dask#8852) Richard (Rick) ZamoraCheck that values for the
inpredicate inread_parquetare correct (dask#8846) Bryan WeberFix bug for reduction of zero dimensional arrays (dask#8930) Tom White
Specify
dtypewhen deciding division usingnp.linspaceinread_sql_query(dask#8940) Cheun Hong
Deprecations#
Deprecate
gather_statisticsfromread_parquet(dask#8992) Richard (Rick) ZamoraChange
require_extensionto top-levelparquet_file_extensionread_parquetkwarg (dask#8935) Richard (Rick) Zamora
Documentation#
Update
write_metadata_filediscussion in documentation (dask#8995) Richard (Rick) ZamoraUpdate
DataFrame.mergedocstring (dask#8966) Pavithra EswaramoorthyAdded description for parameter
align_arraysinarray.blockwise()(dask#8977) ParticularMinerecommend not to use
map_block(drop_axis=...)on chunked axes of an array (dask#8921) ParticularMinerAdd copy button to code snippets in docs (dask#8956) James Bourbeau
Maintenance#
Add
pytest-timeoutto distributed envs on CI (dask#8986) Julia SignellImprove
read_parquetdocstring formatting (dask#8971) Bryan WeberRemove
pytest.warns(None)(dask#8924) Pavithra EswaramoorthyDocument Python 3.10 as supported (dask#8976) Eray Aslan
parse_timedeltaoption to enforce explicit unit (dask#8969) crusaderkymypycompatibility (dask#8854) Paul HobsonAdd a docs page for Dask & Parquet (dask#8899) Jim Crist-Harif
Adds configuration to ignore revs in blame (dask#8933) Bryan Weber
2022.04.1#
Released on April 15, 2022
New Features#
Enhancements#
Avoid collecting parquet metadata in pyarrow when
write_metadata_file=False(dask#8906) Richard (Rick) ZamoraBetter error for failed wildcard path in
dd.read_csv()(fixes #8878) (dask#8908) Roger FilmyerReturn
da.Arrayrather thandd.Seriesfor non-ufunc elementwise functions ondd.Series(dask#8558) Julia SignellLet
get_dummiesusemetacomputation inmap_partitions(dask#8898) Julia SignellMasked scalars input to
da.from_array(dask#8895) David HassellRaise
ValueErrorinmerge_asoffor duplicatekwargs(dask#8861) Bryan Weber
Bug Fixes#
Make
is_monotonicwork when some partitions are empty (dask#8897) Julia SignellFix custom getter in
da.from_arraywheninline_array=False(dask#8903) Ian RoseCorrectly handle dict-specification for rechunk. (dask#8859) Richard
Fix
merge_asof: drop index column ifleft_on == right_on(dask#8874) Gil Forsyth
Deprecations#
Warn users that
engine='auto'will change in future (dask#8907) Jim Crist-HarifRemove
pyarrow-legacyengine from parquet API (dask#8835) Richard (Rick) Zamora
Documentation#
Add note on missing parameter
outfordask.array.dot(dask#8913) Francesco AndreuzziUpdate
DataFrame.querydocstring (dask#8890) Pavithra Eswaramoorthy
Maintenance#
Don’t test
da.prodon large integer data (dask#8893) Jim Crist-HarifAdd
networkmarks to tests that fail without an internet connection (dask#8881) Paul HobsonFix gpuCI GHA version (dask#8891) Charles Blackmon-Luca
xfail/skipsome flakydistributedtests (dask#8887) Jim Crist-HarifRemove unused (deprecated) code from
ArrowDatasetEngine(dask#8885) Richard (Rick) ZamoraAdd mild typing to common utils functions, part 2 (dask#8867) crusaderky
Documentation of Limitation of
sample()(dask#8858) Nadiem Sissouno
2022.04.0#
Released on April 1, 2022
Note
This is the first release with support for Python 3.10
New Features#
Add Python 3.10 support (dask#8566) James Bourbeau
Enhancements#
Add check on
dtype.itemsizein order to produce a useful error (dask#8860) Davide GavioAdd mild typing to common utils functions (dask#8848) Matthew Rocklin
Add sanity checks to
divisionssetter(dask#8806) Jim Crist-HarifUse
Blockwiseandmap_partitionsfor more tasks (dask#8831) Bryan Weber
Bug Fixes#
Fix
dataframe.merge_asofto preserveright_oncolumn (dask#8857) Sarah Charlotte JohnsonFix “Buffer dtype mismatch” for pandas >= 1.3 on 32bit (dask#8851) Ben Greiner
Fix slicing fusion by altering
SubgraphCallablegetter(dask#8827) Ian Rose
Deprecations#
Remove support for PyPy (dask#8863) James Bourbeau
Drop
setuptoolsat runtime (dask#8855) crusaderkyRemove
dataframe.tseries.resample.getnanos(dask#8834) Sarah Charlotte Johnson
Documentation#
Organize diagnostic and performance docs (dask#8871) Naty Clementi
Add image to explain
drop_axisoption ofmap_blocks(dask#8868) ParticularMiner
Maintenance#
Update gpuCI
RAPIDS_VERto22.06(dask#8828)Restore
test_parquetin http (dask#8850) Bryan WeberSimplify gpuCI updating workflow (dask#8849) Charles Blackmon-Luca
2022.03.0#
Released on March 18, 2022
New Features#
Bag: add implementation for reservoir sampling (dask#7636) Daniel Mesejo-León
Add
ma.countto Dask array (dask#8785) David HassellChange
to_parquetdefault tocompression="snappy"(dask#8814) Jim Crist-HarifAdd
weightsparameter todask.array.reduction(dask#8805) David HassellAdd
ddf.compute_current_divisionsto get divisions on a sorted index or column (dask#8517) Julia Signell
Enhancements#
Pass
__name__and__doc__through on DelayedLeaf (dask#8820) Leo GaoRaise exception for not implemented merge
howoption (dask#8818) Naty ClementiMove
Bag.map_partitionstoBlockwise(dask#8646) Richard (Rick) ZamoraImprove error messages for malformed config files (dask#8801) Jim Crist-Harif
Revise column-projection optimization to capture common dask-sql patterns (dask#8692) Richard (Rick) Zamora
Useful error for empty divisions (dask#8789) Pavithra Eswaramoorthy
Scipy 1.8.0 compat: copy private classes into dask/array/stats.py (dask#8694) Julia Signell
Raise warning when using multiple types of schedulers where one is
distributed(dask#8700) Pedro Silva
Bug Fixes#
Fix bug in applying != filter in
read_parquet(dask#8824) Richard (Rick) ZamoraFix
set_indexwhen directly passed a dask Index (dask#8680) Paul HobsonQuick fix for unbounded memory usage in tensordot (dask#7980) Genevieve Buckley
If hdf file is empty, don’t fail on meta creation (dask#8809) Julia Signell
Update
clone_key("x")to retain prefix (dask#8792) crusaderkyFix “physical” column bug in pyarrow-based
read_parquet(dask#8775) Richard (Rick) ZamoraFix
groupby.shiftbug caused by unsorted partitions after shuffle (dask#8782) kori73Fix serialization bug (dask#8786) Richard (Rick) Zamora
Deprecations#
Bump diagnostics bokeh dependency to 2.4.2 (dask#8791) Charles Blackmon-Luca
Deprecate
bcolzsupport (dask#8754) Pavithra EswaramoorthyFinish making
map_overlapdefault boundarykwarg'none'(dask#8743) Genevieve Buckley
Documentation#
Custom collection example docs fix (dask#8807) Doug Davis
Add
Series.str,Series.dt, andSeries.cataccessors to docs (dask#8757) Sarah Charlotte JohnsonFix docstring for
ddf.compute_current_divisions(dask#8793) Julia SignellDashboard docs on /status page (dask#8648) Naty Clementi
Clarify divisions
kwargin repartition docstring (dask#8781) Sarah Charlotte JohnsonUpdate Docker images to use ghcr.io (dask#8774) Jacob Tomlinson
Maintenance#
Reduce gpuci
pytestparallelism (dask#8826) GALI PREM SAGARabsolufy-imports- No relative imports - PEP8 (dask#8796) Julia SignellTidy up
assert_eqcalls in array tests (dask#8812) Julia SignellFix
test_describe_emptyto work without global-Werror(dask#8291) Michał GórnyTemporarily xfail graphviz tests on windows (dask#8794) Jim Crist-Harif
Use
packaging.parseformd5compatibility (dask#8763) James BourbeauMake
tokenizework in a FIPS 140-2 environment (dask#8762) Jim Crist-HarifLabel issues and PRs on open with ‘needs triage’ (dask#8761) Julia Signell
Specify action version and change from
pull_request_targettopull_request(dask#8767) Julia SignellMake scheduler
kwargpass though to sub functions inda.assert_eq(dask#8755) Julia Signell
2022.02.1#
Released on February 25, 2022
New Features#
Add aggregate functions
firstandlasttodask.dataframe.pivot_table(dask#8649) Knut NordangerAdd
std()support fordatetime64dtypefor pandas-like objects (dask#8523) Ben GlossnerAdd materialized task counts to
HighLevelGraphandLayerhtml reprs (dask#8589) kori73
Enhancements#
Do not allow iterating a
DataFrameGroupBy(dask#8696) Bryan WeberFix missing newline after
info()call on emptyDataFrame(dask#8727) Naty ClementiAdd
groupby.computeas a not implemented method (dask#8734) DranaxelImprove multi dataframe join performance (dask#8740) Holden Karau
Include
booltype forIndex(dask#8732) Naty ClementiAllow
ArrowDatasetEnginesubclass to override pandas->arrow conversion also for partitioned write (dask#8741) Joris Van den BosscheIncrease performance of k-diagonal extraction in
da.diag()andda.diagonal()(dask#8689) ParticularMinerChange
linspacecreation to match numpy when num equal to 0 (dask#8676) PeterTokenize
dataclasses(dask#8557) Gabe JosephUpdate
tokenizeto treatdictandkwargsdifferently (dask#8655) James Bourbeau
Bug Fixes#
Fix bug in
dask.array.roll()for roll-shifts that match the size of the input array (dask#8723) ParticularMinerFix for
normalize_functiondataclassmethods (dask#8527) Sarah Charlotte JohnsonFix rechunking with zero-size-chunks (dask#8703) ParticularMiner
Move creation of
sqlalchemyconnection for picklability (dask#8745) Julia Signell
Deprecations#
Drop Python 3.7 (dask#8572) James Bourbeau
Deprecate
iteritems(dask#8660) James BourbeauDeprecate
dataframe.tseries.resample.getnanos(dask#8752) Sarah Charlotte JohnsonAdd deprecation warning for pyarrow-legacy engine (dask#8758) Richard (Rick) Zamora
Documentation#
Update link typos in changelog (dask#8717) James Bourbeau
Update Docker example to use current best practices (dask#8731) Jacob Tomlinson
Update docs to include
distributed.Client.preload(dask#8679) Bryan WeberDocument monthly social meeting (dask#8595) Thomas Grainger
Add docs for Gen2 access with RBAC/ACL i.e. security principal (dask#8748) Martin Thøgersen
Use Dask configuration extension from
dask-sphinx-theme(dask#8751) Benjamin Zaitlen
Maintenance#
Unpin
coveragein CI (dask#8690) James BourbeauAdd manual trigger for running test suite (dask#8716) James Bourbeau
Xfail
scheduler_HLG_unpack_import; flaky test (dask#8724) Mike McCartyTemporarily remove
scipyupstream CI build (dask#8725) James BourbeauBump pre-release version to be greater than stable releases (dask#8728) Charles Blackmon-Luca
Move custom sort function logic to internal
sort_values(dask#8571) Charles Blackmon-LucaPin
cloudpickleandscipyin docs requirements (dask#8737) Julia SignellMake the labeler not delete labels, and look for the docs at the right spot (dask#8746) Julia Signell
Fix docs build warnings (dask#8432) Kristopher Overholt
Update test status badge (dask#8747) James Bourbeau
Fix parquet
test_pandas_timestamp_overflow_pyarrowtest (dask#8733) Joris Van den BosscheOnly run PR builds on changes to relevant files (dask#8756) Charles Blackmon-Luca
2022.02.0#
Released on February 11, 2022
Note
This is the last release with support for Python 3.7
New Features#
Add
regiontoto_zarrwhen using existing array (dask#8590) Chris RoatAdd
engine_kwargssupport todask.dataframe.to_sql(dask#8609) Amir KadivarAdd
include_path_columnarg toread_json(dask#8603) Bryan Weber
Enhancements#
Add scheduler option to
assert_equtilities (dask#8610) Xinrong MengFix eye inconsistency with NumPy for
dtype=None(dask#8685) Tom WhiteFix concatenate inconsistency with NumPy for
axis=None(dask#8686) Tom WhiteType annotations, part 1 (dask#8295) crusaderky
Really allow any iterable to be passed as a
meta(dask#8629) Julia SignellUse
map_partitions(Blockwise) into_parquet(dask#8487) Richard (Rick) Zamora
Bug Fixes#
Result of reducing an array should not depend on its chunk-structure (dask#8637) ParticularMiner
Pass place-holder metadata to
map_partitionsin ACA code path (dask#8643) Richard (Rick) Zamora
Deprecations#
Deprecate
is_monotonic(dask#8653) James BourbeauRemove some deprecations (dask#8605) James Bourbeau
Documentation#
Add Domino Data Lab to Hosted / managed Dask clusters (dask#8675) Ray Bell
Fix inter-linking and remove deprecated function (dask#8715) Julia Signell
Fix imbalanced backticks. (dask#8693) Matthias Bussonnier
Add documentation for high level graph visualization (dask#8483) Genevieve Buckley
Update documentation of
ProgressBaroutparameter (dask#8604) Pedro SilvaImprove documentation of
dask.config.set(dask#8705) crusaderkyRevert mention to
mypyamong type checkers (dask#8699) crusaderky
Maintenance#
Update warning handling in
get_dummiestests (dask#8651) James BourbeauAdd a github changelog template (dask#8714) Julia Signell
Update year in LICENSE.txt (dask#8665) David Hoese
Update
pre-commitversion (dask#8691) James BourbeauInclude
scipyin upstream CI build (dask#8681) James BourbeauTemporarily pin
scipy < 1.8.0in CI (dask#8683) James BourbeauPin
scipyto less than 1.8.0 in GPU CI (dask#8698) Julia SignellAvoid
pytest.warns(None)intest_multi.py(dask#8678) James BourbeauUpdate GHA concurrent job cancellation (dask#8652) James Bourbeau
Make
test__get_pathsrobust tosite.PREFIXESbeing set (dask#8644) James BourbeauBump gpuCI PYTHON_VER to 3.9 (dask#8642) Charles Blackmon-Luca
2022.01.1#
Released on January 28, 2022
New Features#
Add
dask.dataframe.series.view()(dask#8533) Pavithra Eswaramoorthy
Enhancements#
Update
tzforfastparquet+pandas1.4.0 (dask#8626) Martin DurantCleaning up misc tests for
pandascompat (dask#8623) Julia SignellPandas compat: Filter sparse warnings (dask#8621) Julia Signell
Fail if
metais not apandasobject (dask#8563) Julia SignellUse
fsspec.parquetmodule for better remote-storageread_parquetperformance (dask#8339) Richard (Rick) ZamoraMove DataFrame ACA aggregations to HLG (dask#8468) Richard (Rick) Zamora
Add optional information about originating function call in
DataFrameIOLayer(dask#8453) Richard (Rick) ZamoraRefactor config default search path retrieval (dask#8573) James Bourbeau
Add
optimize_graphflag toBag.to_dataframefunction (dask#8486) Maxim LippeveldMake sure that delayed output operations still return lists of paths (dask#8498) Julia Signell
Pandas compat: Fix
to_framenameto not passNone(dask#8554) Julia SignellPandas compat: Fix
axis=Nonewarning (dask#8555) Julia SignellExpand Dask YAML config search directories (dask#8531) abergou
Bug Fixes#
Fix
groupby.cumsumwith series grouped by index (dask#8588) Julia SignellFix
derived_fromforpandasmethods (dask#8612) Thomas J. FanEnforce boolean
ascendingforsort_values(dask#8440) Charles Blackmon-LucaFix parsing of
__setitem__indices (dask#8601) David HassellAvoid divide by zero in slicing (dask#8597) Doug Davis
Deprecations#
Downgrade
metaerror in (dask#8563) to warning (dask#8628) Julia SignellPandas compat: Deprecate
appendwhenpandas >= 1.4.0(dask#8617) Julia Signell
Documentation#
Replace outdated
columnsargument withmetain DataFrame constructor (dask#8614) kori73Refactor deploying docs (dask#8602) Jacob Tomlinson
Maintenance#
Pin
coveragein CI (dask#8631) James BourbeauMove
cached_cumsumimports to be fromdask.utils(dask#8606) James BourbeauUpdate gpuCI
RAPIDS_VERto22.04(dask#8600)Update cocstring for
from_delayedfunction (dask#8576) Kirito1397Handle
plot_width/plot_heightdeprecations (dask#8544) Bryan Van de VenRemove unnecessary
pyyamlimportorskip(dask#8562) James BourbeauSpecify scheduler in DataFrame
assert_eq(dask#8559) Gabe Joseph
2022.01.0#
Released on January 14, 2022
New Features#
Add
DataFrame.nunique(dask#8479) Sarah Charlotte JohnsonAdd
da.ndimto matchnp.ndim(dask#8502) Julia Signell
Enhancements#
Only show
percentileinterpolation=keyword warning if NumPy version >= 1.22 (dask#8564) Julia SignellRaise
PerformanceWarningwhenlimitand"array.slicing.split-large-chunks"areNone(dask#8511) Julia SignellDefine
normalize_seqfunction at import time (dask#8521) IllviljanEnsure that divisions are alway tuples (dask#8393) Charles Blackmon-Luca
Allow a callable scheduler for
bag.groupby(dask#8492) Julia SignellSave Zarr arrays with dask-on-ray scheduler (dask#8472) TnTo
Make byte blocks more even in
read_bytes(dask#8459) Martin DurantImproved the efficiency of
matmul()by completely removing concatenation (dask#8423) ParticularMinerLimit max chunk size when reshaping dask arrays (dask#8124) Genevieve Buckley
Changes for fastparquet superthrift (dask#8470) Martin Durant
Bug Fixes#
Fix boolean indices in array assignment (dask#8538) David Hassell
Detect default
dtypeon array-likes (dask#8501) aeisenbarthFix
optimize_blockwisebug for duplicate dependency names (dask#8542) Richard (Rick) ZamoraUpdate warnings for
DataFrame.GroupBy.applyand transform (dask#8507) Sarah Charlotte JohnsonTrack HLG layer name in
Delayed(dask#8452) Gabe JosephFix single item
nanminandnanmaxreductions (dask#8484) Julia SignellMake
read_csvwithcommentkwargwork even if there is a comment in the header (dask#8433) Julia Signell
Deprecations#
Replace
interpolationwithmethodandmethodwithinternal_method(dask#8525) Julia SignellRemove daily stock demo utility (dask#8477) James Bourbeau
Documentation#
Add a join example in docs that be run with copy/paste (dask#8520) kori73
Fix changelog section hyperlinks (dask#8534) Aneesh Nema
Hyphenate “single-machine scheduler” for consistency (dask#8519) Deepyaman Datta
Normalize whitespace in doctests in
slicing.py(dask#8512) Maren WestermannBest practices storage line typo (dask#8529) Michael Delgado
Update figures (dask#8401) Sarah Charlotte Johnson
Remove
pyarrow-only reference fromsplit_row_groupsinread_parquetdocstring (dask#8490) Naty Clementi
Maintenance#
Remove obsolete
LocalFileSystemtests that fail forfsspec>=2022.1.0(dask#8565) Richard (Rick) ZamoraTweak: “RuntimeWarning: invalid value encountered in reciprocal” (dask#8561) crusaderky
Fix
skipna=NoneforDataFrame.sem(dask#8556) Julia SignellFix
PANDAS_GT_140(dask#8552) Julia SignellCollections with HLG must always implement
__dask_layers__(dask#8548) crusaderkyWork around race condition in
import llvmlite(dask#8550) crusaderkySet a minimum version for
pyyaml(dask#8545) Gaurav SheniAdding
nodefaultsto environments to fixtiledb+ mac issue (dask#8505) Julia SignellSet ceiling for
setuptools(dask#8509) Julia SignellAdd workflow / recipe to generate Dask nightlies (dask#8469) Charles Blackmon-Luca
Bump gpuCI
CUDA_VERto 11.5 (dask#8489) Charles Blackmon-Luca
2021.12.0#
Released on December 10, 2021
New Features#
Add
SeriesandIndexis_monotonic*methods (dask#8304) Daniel Mesejo-León
Enhancements#
Blockwise
map_partitionswithpartition_info(dask#8310) Gabe JosephBetter error message for length of array with unknown chunk sizes (dask#8436) Doug Davis
Use
byinstead ofindexinternally on the Groupby class (dask#8441) Julia SignellAllow custom sort functions for
sort_values(dask#8345) Charles Blackmon-LucaAdd warning to
read_parquetwhen statistics and partitions are misaligned (dask#8416) Richard (Rick) ZamoraMake visualize more consistent with compute (dask#8328) JSKenyon
Bug Fixes#
Fix
map_blocksnot using own arguments innamegeneration (dask#8462) David HoeseFix for index error with reading empty parquet file (dask#8410) Sarah Charlotte Johnson
Fix nullable-dtype error when writing partitioned parquet data (dask#8400) Richard (Rick) Zamora
Fix CSV header bug (dask#8413) Richard (Rick) Zamora
Fix empty chunk causes exception in
nanmin/nanmax(dask#8375) Boaz Mohar
Deprecations#
Deprecate
tokenkeyword argument tomap_blocks(dask#8464) James BourbeauDeprecation warning for default value of boundary kwarg in
map_overlap(dask#8397) Genevieve Buckley
Documentation#
Clarify
block_infodocumentation (dask#8425) Genevieve BuckleyOutput from alt text sprint (dask#8456) Sarah Charlotte Johnson
Update talks and presentations (dask#8370) Naty Clementi
Update Anaconda link in “Paid support” section of docs (dask#8427) Martin Durant
Fixed broken
dask-gatewaylink inecosystem.rst(dask#8424) ofirrFix CuPy doctest error (dask#8412) Genevieve Buckley
Maintenance#
Bump Bokeh min version to 2.1.1 (dask#8431) Bryan Van de Ven
Fix following
fsspec=2021.11.1release (dask#8428) Martin DurantAdd
dask/ml.pyto pytest exclude list (dask#8414) Genevieve BuckleyUpdate gpuCI
RAPIDS_VERto22.02(dask#8394)Unpin
graphvizand improve package management in environment-3.7 (dask#8411) Julia Signell
2021.11.2#
Released on November 19, 2021
Only run gpuCI bump script daily (dask#8404) Charles Blackmon-Luca
Actually ignore index when asked in
assert_eq(dask#8396) Gabe JosephEnsure single-partition join
divisionsistuple(dask#8389) Charles Blackmon-LucaTry to make divisions behavior clearer (dask#8379) Julia Signell
Fix typo in
set_indexpartition_sizeparameter description (dask#8384) FredericOdermattUse
blockwiseinsingle_partition_join(dask#8341) Gabe JosephUse more explicit keyword arguments (dask#8354) Boaz Mohar
Fix
.locof DataFrame with nullable booleandtype(dask#8368) Marco RossiParameterize shuffle implementation in tests (dask#8250) Ian Rose
Remove some doc build warnings (dask#8369) Boaz Mohar
Include properties in array API docs (dask#8356) Julia Signell
Fix Zarr for upstream (dask#8367) Julia Signell
Pin
graphvizto avoid issue with windows and Python 3.7 (dask#8365) Julia SignellImport
graphviz.Diagraphfrom top of module, not fromdot(dask#8363) Julia Signell
2021.11.1#
Released on November 8, 2021
Patch release to update distributed dependency to version 2021.11.1.
2021.11.0#
Released on November 5, 2021
Fx
required_extensionbehavior inread_parquet(dask#8351) Richard (Rick) ZamoraAdd
align_dataframestomap_partitionsto broadcast a dataframe passed as an arg (dask#6628) Julia SignellBetter handling for arrays/series of keys in
dask.dataframe.loc(dask#8254) Julia SignellAdd
name_functionoption toto_parquet(dask#7682) Matthew PowersGet rid of
environment-latest.ymland update to Python 3.9 (dask#8275) Julia SignellRequire newer
s3fsin CI (dask#8336) James BourbeauGroupby Rolling (dask#8176) Julia Signell
Add more ordering diagnostics to
dask.visualize(dask#7992) Erik WelchUse
HighLevelGraphoptimizations fordelayed(dask#8316) Ian Rosedemo_tuplesproduces malformedHighLevelGraph(dask#8325) crusaderkyDask calendar should show events in local time (dask#8312) Genevieve Buckley
Fix flaky
test_interrupt(dask#8314) crusaderkyDeprecate
AxisError(dask#8305) crusaderkyFix name of cuDF in extension documentation. (dask#8311) Vyas Ramasubramani
Add single eq operator (=) to parquet filters (dask#8300) Ayush Dattagupta
Improve support for Spark output in
read_parquet(dask#8274) Richard (Rick) ZamoraAdd
dask.mlmodule (dask#6384) Matthew RocklinCI fixups (dask#8298) James Bourbeau
Make slice errors match NumPy (dask#8248) Julia Signell
Fix API docs misrendering with new sphinx theme (dask#8296) Julia Signell
Replace
blockproperty withblockviewfor array-like operations on blocks (dask#8242) Davis BennettDeprecate
file_pathand make it possible to save from within a notebook (dask#8283) Julia Signell
2021.10.0#
Released on October 22, 2021
da.storeto create well-formedHighLevelGraph(dask#8261) crusaderkyCI: force nightly
pyarrowin the upstream build (dask#8281) Joris Van den BosscheRemove
chest(dask#8279) James BourbeauSkip doctests if optional dependencies are not installed (dask#8258) Genevieve Buckley
Update
tmpdirandtmpfilecontext manager docstrings (dask#8270) Daniel Mesejo-LeónUnregister callbacks in doctests (dask#8276) James Bourbeau
Stale label GitHub action (dask#8244) Genevieve Buckley
Client-shutdown method appears twice (dask#8273) German Shiklov
Add pre-commit to test requirements (dask#8257) Genevieve Buckley
Refactor
read_metadatainfastparquetengine (dask#8092) Richard (Rick) ZamoraSupport
Pathobjects infrom_zarr(dask#8266) Samuel GaistMake nested redirects work (dask#8272) Julia Signell
Set
memory_usagetoTrueifverboseisTruein info (dask#8222) Kinshuk DuaRemove individual API doc pages from sphinx toctree (dask#8238) James Bourbeau
Ignore whitespace in gufunc
signature(dask#8267) James BourbeauAdd workflow to update gpuCI (dask#8215) Charles Blackmon-Luca
DataFrame.headshouldn’t warn when there’s one partition (dask#8091) Pankaj PatilIgnore arrow doctests if
pyarrownot installed (dask#8256) Genevieve BuckleyFix
debugging.htmlredirect (dask#8251) James BourbeauFix null sorting for single partition dataframes (dask#8225) Charles Blackmon-Luca
Fix
setup.htmlredirect (dask#8249) Florian JetterRun
pyupgradein CI (dask#8246) crusaderkyFix label typo in upstream CI build (dask#8237) James Bourbeau
Add support for “dependent” columns in DataFrame.assign (dask#8086) Suriya Senthilkumar
add NumPy array of Dask keys to
Array(dask#7922) Davis BennettRemove unnecessary
dask.multiprocessingimport in docs (dask#8240) Ray BellAdjust retrieving
_max_workersfromExecutor(dask#8228) John A KirkhamUpdate function signatures in
delayedbest practices docs (dask#8231) Vũ Trung ĐứcDocs reoganization (dask#7984) Julia Signell
Fix
df.quantileon all missing data (dask#8129) Julia SignellAdd
tokenize.ensure-deterministicconfig option (dask#7413) Hristo GeorgievUse
inclusiverather thanclosedwithpandas>=1.4.0andpd.date_range(dask#8213) Julia SignellAdd
dask-gateway, Coiled, and Saturn-Cloud to list of Dask setup tools (dask#7814) Kristopher OverholtEnsure existing futures get passed as deps when serializing
HighLevelGraphlayers (dask#8199) Jim Crist-HarifMake sure that the divisions of the single partition merge is left (dask#8162) Julia Signell
Refactor
read_metadatainpyarrowparquet engines (dask#8072) Richard (Rick) ZamoraSupport negative
drop_axisinmap_blocksandmap_overlap(dask#8192) Gregory R. LeeFix upstream tests (dask#8205) Julia Signell
Add support for scalar item assignment by Series (dask#8195) Charles Blackmon-Luca
Add some basic examples to doc strings on
dask.bagall,any,countmethods (dask#7630) Nathan DanielsenDon’t have upstream report depend on commit message (dask#8202) James Bourbeau
Ensure upstream CI cron job runs (dask#8200) James Bourbeau
Use
pytest.paramto properly label param-specific GPU tests (dask#8197) Charles Blackmon-LucaAdd
test_set_indexto tests ran on gpuCI (dask#8198) Charles Blackmon-LucaSuppress
tmpfileOSError (dask#8191) James BourbeauUse
s.isnainstead ofpd.isna(s)inset_partitions_pre(fix cudf CI) (dask#8193) Charles Blackmon-LucaOpen an issue for
test-upstreamfailures (dask#8067) Wallace ReisFix
to_parquetbug in call topyarrow.parquet.read_metadata(dask#8186) Richard (Rick) ZamoraAdd handling for null values in
sort_values(dask#8167) Charles Blackmon-LucaBump
RAPIDS_VERfor gpuCI (dask#8184) Charles Blackmon-LucaDispatch walks MRO for lazily registered handlers (dask#8185) Jim Crist-Harif
Preserve
HighLevelGraphsinDataFrame.from_delayed(dask#8174) Gabe JosephDeprecate
inplaceargument for Dask series renaming (dask#8136) Marcel CoetzeeFix rolling for compatibility with
pandas > 1.3.0(dask#8150) Julia SignellRaise error when
setitemon unknown chunks (dask#8166) Julia SignellInclude divisions when doing
Index.to_series(dask#8165) Julia Signell
2021.09.1#
Released on September 21, 2021
Fix
groupbyfor future pandas (dask#8151) Julia SignellRemove warning filters in tests that are no longer needed (dask#8155) Julia Signell
Add link to diagnostic visualize function in local diagnostic docs (dask#8157) David Hoese
Add
datetime_is_numerictodataframe.describe(dask#7719) Julia SignellRemove references to
pd.Int64Indexin anticipation of deprecation (dask#8144) Julia SignellUse
locif needed for series__get_item__(dask#7953) Julia SignellSpecifically ignore warnings on mean for empty slices (dask#8125) Julia Signell
Skip
groupbynuniquetest for pandas >= 1.3.3 (dask#8142) Julia SignellImplement
ascendingarg forsort_values(dask#8130) Charles Blackmon-LucaReplace
operator.getitem(dask#8015) Naty ClementiDeprecate
zero_broadcast_dimensionsandhomogeneous_deepmap(dask#8134) SnkSynthesisAllow
schedulerto be anExecutor(dask#8112) John A KirkhamHandle
asarray/asanyarraycases wherelikeis adask.Array(dask#8128) Peter Andreas EntschevFix
index_colduplication ifindex_colis typestr(dask#7661) McToelAdd
dtypeandordertoasarrayandasanyarraydefinitions (dask#8106) Julia SignellDeprecate
dask.dataframe.Series.__contains__(dask#7914) Julia SignellFix edge case with
like-arrays in_wrapped_qr(dask#8122) Peter Andreas EntschevDeprecate
boundary_slicekwarg:kindfor pandas compat (dask#8037) Julia Signell
2021.09.0#
Released on September 3, 2021
Fewer open files (dask#7303) Julia Signell
Add
FileNotFoundto expected http errors (dask#8109) Martin DurantAdd
DataFrame.sort_valuesto API docs (dask#8107) Benjamin ZaitlenChange to
dask.order: be more eager at times (dask#7929) Erik WelchAdd pytest color to CI (dask#8090) James Bourbeau
FIX:
make_peopleworks withprocessesscheduler (dask#8103) DahnAdds
deepparam to Dataframe copy method and restrict it toFalse(dask#8068) João Paulo LacerdaFix typo in configuration docs (dask#8104) Robert Hales
Update formatting in
DataFrame.querydocstring (dask#8100) James BourbeauUn-xfail
sparsetests for 0.13.0 release (dask#8102) James BourbeauAdd axes property to DataFrame and Series (dask#8069) Jordan Jensen
Add CuPy support in
da.unique(values only) (dask#8021) Peter Andreas EntschevUnit tests for
sparse.zeros_like(xfailed) (dask#8093) crusaderkyAdd explicit
likekwarg support to array creation functions (dask#8054) Peter Andreas EntschevSeparate Array and DataFrame mindeps builds (dask#8079) James Bourbeau
Fork out
percentile_dispatchtodask.array(dask#8083) GALI PREM SAGAREnsure
filepathexists into_parquet(dask#8057) James BourbeauUpdate scheduler plugin usage in
test_scheduler_highlevel_graph_unpack_import(dask#8080) James BourbeauAdd
DataFrame.shuffleto API docs (dask#8076) Martin FleischmannOrder requirements alphabetically (dask#8073) John A Kirkham
2021.08.1#
Released on August 20, 2021
Add
ignore_metadata_fileoption toread_parquet(pyarrow-datasetandfastparquetsupport only) (dask#8034) Richard (Rick) ZamoraAdd reference to
pytest-xdistin dev docs (dask#8066) Julia SignellInclude
tzin meta fromto_datetime(dask#8000) Julia SignellCI Infra Docs (dask#7985) Benjamin Zaitlen
Include invalid DataFrame key in
assert_eqcheck (dask#8061) James BourbeauUse
__class__when creating DataFrames (dask#8053) Mads R. B. KristensenUse development version of
distributedin gpuCI build (dask#7976) James BourbeauIgnore whitespace when gufunc
signature(dask#8049) James BourbeauMove pandas import and percentile dispatch refactor (dask#8055) GALI PREM SAGAR
Add colors to represent high level layer types (dask#7974) Freyam Mehta
Upstream instance fix (dask#8060) Jacob Tomlinson
Add
dask.widgetsand migrate HTML reprs tojinja2(dask#8019) Jacob TomlinsonRemove
wrap_func_like_safe, not required with NumPy >= 1.17 (dask#8052) Peter Andreas EntschevFix threaded scheduler memory backpressure regression (dask#8040) David Hoese
Add percentile dispatch (dask#8029) GALI PREM SAGAR
Use a publicly documented attribute
objingroupbyrather than private_selected_obj(dask#8038) GALI PREM SAGARUse
dictto store data for {nan,}arg{min,max} in certain cases (dask#8014) Peter Andreas EntschevFix
blocksizedescription formatting inread_pandas(dask#8047) Louis MaddoxFix “point” -> “pointers” typo in docs (dask#8043) David Chudzicki
2021.08.0#
Released on August 13, 2021
Fix
to_orcdelayed compute behavior (dask#8035) Richard (Rick) ZamoraDon’t convert to low-level task graph in
compute_as_if_collection(dask#7969) James BourbeauFix multifile read for hdf (dask#8033) Julia Signell
Resolve warning in
distributedtests (dask#8025) James BourbeauUpdate
to_orccollection name (dask#8024) James BourbeauRaise
NotImplementedErrorfor non-indexable arg passed toto_datetime(dask#7989) Doug DavisEnsure we error on warnings from
distributed(dask#8002) James BourbeauAdded
dictformat into_bagaccessories of DataFrame (dask#7932) gurunathAdd tooltips to graphviz high-level graphs (dask#7973) Freyam Mehta
Close 2021 User Survey (dask#8007) Julia Signell
Reorganize CuPy tests into multiple files (dask#8013) Peter Andreas Entschev
Refactor and Expand Dask-Dataframe ORC API (dask#7756) Richard (Rick) Zamora
Don’t enforce columns if
enforce=False(dask#7916) Julia SignellFix
map_overlaptrimming behavior whendrop_axisis notNone(dask#7894) Gregory R. LeeMark gpuCI CuPy test as flaky (dask#7994) Peter Andreas Entschev
Avoid using
Delayedinto_csvandto_parquet(dask#7968) Matthew RocklinUse
pytest.warnsinstead of raises for checking parquet engine deprecation (dask#7993) Joris Van den BosscheBump
RAPIDS_VERin gpuCI to 21.10 (dask#7991) Charles Blackmon-LucaAdd back
pyarrow-legacytest coverage forpyarrow>=5(dask#7988) Richard (Rick) ZamoraAllow
pyarrow>=5into_parquetandread_parquet(dask#7967) Richard (Rick) ZamoraSkip CuPy tests requiring NEP-35 when NumPy < 1.20 is available (dask#7982) Peter Andreas Entschev
Add
tailandheadtoSeriesGroupby(dask#7935) Daniel Mesejo-LeónUpdate Zoom link for monthly meeting (dask#7979) James Bourbeau
Add gpuCI build script (dask#7966) Charles Blackmon-Luca
Deprecate
daily_stockutility (dask#7949) James BourbeauAdd
distributed.nannyto configuration reference docs (dask#7955) James BourbeauRequire NumPy 1.18+ & Pandas 1.0+ (dask#7939) John A Kirkham
2021.07.2#
Released on July 30, 2021
Note
This is the last release with support for NumPy 1.17 and pandas 0.25. Beginning with the next release, NumPy 1.18 and pandas 1.0 will be the minimum supported versions.
Add
dask.arraySVG to the HTML Repr (dask#7886) Freyam MehtaAvoid use of
Delayedinto_parquet(dask#7958) Matthew RocklinTemporarily pin
pyarrow<5in CI (dask#7960) James BourbeauAdd deprecation warning for top-level
ucxandrmmconfig values (dask#7956) James BourbeauRemove skips from doctests (4 of 6) (dask#7865) Zhengnan Zhao
Remove skips from doctests (5 of 6) (dask#7864) Zhengnan Zhao
Adds missing prepend/append functionality to
da.diff(dask#7946) Peter Andreas EntschevChange graphviz font family to sans (dask#7931) Freyam Mehta
Fix read-csv name - when path is different, use different name for task (dask#7942) Julia Signell
Update configuration reference for
ucxandrmmchanges (dask#7943) James BourbeauAdd meta support to
__setitem__(dask#7940) Peter Andreas EntschevNEP-35 support for
slice_with_int_dask_array(dask#7927) Peter Andreas EntschevUnpin fastparquet in CI (dask#7928) James Bourbeau
Remove skips from doctests (3 of 6) (dask#7872) Zhengnan Zhao
2021.07.1#
Released on July 23, 2021
Make array
assert_eqcheck dtype (dask#7903) Julia SignellRemove skips from doctests (6 of 6) (dask#7863) Zhengnan Zhao
Remove experimental feature warning from actors docs (dask#7925) Matthew Rocklin
Remove skips from doctests (2 of 6) (dask#7873) Zhengnan Zhao
Separate out Array and Bag API (dask#7917) Julia Signell
Implement lazy
Array.__iter__(dask#7905) Julia SignellClean up places where we inadvertently iterate over arrays (dask#7913) Julia Signell
Add
numeric_onlykwarg to DataFrame reductions (dask#7831) Julia SignellAdd pytest marker for GPU tests (dask#7876) Charles Blackmon-Luca
Add support for
histogram2dindask.array(dask#7827) Doug DavisRemove skips from doctests (1 of 6) (dask#7874) Zhengnan Zhao
Add node size scaling to the Graphviz output for the high level graphs (dask#7869) Freyam Mehta
Update old Bokeh links (dask#7915) Bryan Van de Ven
Temporarily pin
fastparquetin CI (dask#7907) James BourbeauAdd
dask.arrayimport to progress bar docs (dask#7910) Fabian GebhartUse separate files for each DataFrame API function and method (dask#7890) Julia Signell
Fix
pyarrow-datasetordering bug (dask#7902) Richard (Rick) ZamoraGeneralize unique aggregate (dask#7892) GALI PREM SAGAR
Raise
NotImplementedErrorwhen usingpd.Grouper(dask#7857) Ruben van de GeerAdd
aggregate_filesargument to enable multi-file partitions inread_parquet(dask#7557) Richard (Rick) ZamoraUn-
xfailtest_daily_stock(dask#7895) James BourbeauUpdate access configuration docs (dask#7837) Naty Clementi
Use packaging for version comparisons (dask#7820) Elliott Sales de Andrade
Handle infinite loops in
merge_asof(dask#7842) gerrymanoim
2021.07.0#
Released on July 9, 2021
Include
fastparquetin upstream CI build (dask#7884) James BourbeauBlockwise: handle non-string constant dependencies (dask#7849) Mads R. B. Kristensen
fastparquetnow supports new time types, including ns precision (dask#7880) Martin DurantAvoid
ParquetDatasetAPI when appending inArrowDatasetEngine(dask#7544) Richard (Rick) ZamoraAdd retry logic to
test_shuffle_priority(dask#7879) Richard (Rick) ZamoraUse strict channel priority in CI (dask#7878) James Bourbeau
Support nested
dask.distributedimports (dask#7866) Matthew RocklinShould check module name only, not the entire directory filepath (dask#7856) Genevieve Buckley
Updates due to dask/fastparquet#623 (dask#7875) Martin Durant
da.eyefix forchunks=-1(dask#7854) Naty ClementiTemporarily xfail
test_daily_stock(dask#7858) James BourbeauSet priority annotations in
SimpleShuffleLayer(dask#7846) Richard (Rick) ZamoraBlockwise: stringify constant key inputs (dask#7838) Mads R. B. Kristensen
Allow mixing dask and numpy arrays in
@guvectorize(dask#6863) Julia SignellDon’t sample dict result of a shuffle group when calculating its size (dask#7834) Florian Jetter
Fix scipy tests (dask#7841) Julia Signell
Deterministically tokenize
datetime.date(dask#7836) James BourbeauAdd
sample_rowstoread_csv-like (dask#7825) Martin DurantFix typo in
config.deserializedocstring (dask#7830) Geoffrey LentnerRemove warning filter in
test_dataframe_picklable(dask#7822) James BourbeauImprovements to
histogramdd(for handling inputs that are sequences-of-arrays). (dask#7634) Doug DavisMake
PY_VERSIONprivate (dask#7824) James Bourbeau
2021.06.2#
Released on June 22, 2021
layers.pycompareparts_outwithset(self.parts_out)(dask#7787) Genevieve BuckleyMake
check_metaunderstand pandas dtypes better (dask#7813) Julia SignellRemove “Educational Resources” doc page (dask#7818) James Bourbeau
2021.06.1#
Released on June 18, 2021
Replace funding page with ‘Supported By’ section on dask.org (dask#7817) James Bourbeau
Add initial deprecation utilities (dask#7810) James Bourbeau
Enforce dtype conservation in ufuncs that explicitly use
dtype=(dask#7808) Doug DavisAdd Coiled to list of paid support organizations (dask#7811) Kristopher Overholt
Small tweaks to the HTML repr for
Layer&HighLevelGraph(dask#7812) Genevieve BuckleyAdd dark mode support to HLG HTML repr (dask#7809) Jacob Tomlinson
Remove compatibility entries for old distributed (dask#7801) Elliott Sales de Andrade
Implementation of HTML repr for
HighLevelGraphlayers (dask#7763) Genevieve BuckleyUpdate default
blockwisetoken to avoid DataFrame column name clash (dask#6546) James BourbeauUse dispatch
concatformerge_asof(dask#7806) Julia SignellFix upstream freq tests (dask#7795) Julia Signell
Use more context managers from the standard library (dask#7796) James Bourbeau
Simplify skips in parquet tests (dask#7802) Elliott Sales de Andrade
Remove check for outdated bokeh (dask#7804) Elliott Sales de Andrade
More test coverage uploads (dask#7799) James Bourbeau
Remove
ImportErrorcatching fromdask/__init__.py(dask#7797) James BourbeauAllow
DataFrame.join()to take a list of DataFrames to merge with (dask#7578) Krishan BhasinFix maximum recursion depth exception in
dask.array.linspace(dask#7667) Daniel Mesejo-LeónFix docs links (dask#7794) Julia Signell
Initial
da.select()implementation and test (dask#7760) Gabriel MirettiLayers must implement
get_output_keysmethod (dask#7790) Genevieve BuckleyDon’t include or expect
freqin divisions (dask#7785) Julia SignellA
HighLevelGraphabstract layer formap_overlap(dask#7595) Genevieve BuckleyAlways include kwarg name in
drop(dask#7784) Julia SignellOnly rechunk for median if needed (dask#7782) Julia Signell
Add
add_(prefix|suffix)to DataFrame and Series (dask#7745) tsugaMove
read_hdftoBlockwise(dask#7625) Richard (Rick) ZamoraMake
Layer.get_output_keysofficially an abstract method (dask#7775) Genevieve BuckleyNon-dask-arrays and broadcasting in
ravel_multi_index(dask#7594) Gabe JosephFix for paths ending with “/” in parquet overwrite (dask#7773) Martin Durant
Fixing calling
.visualize()withfilename=None(dask#7740) Freyam MehtaGenerate unique names for
SubgraphCallable(dask#7637) Bruce MerryPin
fsspecto2021.5.0in CI (dask#7771) James BourbeauEvaluate graph lazily if meta is provided in
from_delayed(dask#7769) Florian JetterAdd
metasupport forDatetimeTZDtype(dask#7627) gerrymanoimAdd dispatch label to automatic PR labeler (dask#7701) James Bourbeau
Fix HDFS tests (dask#7752) Julia Signell
2021.06.0#
Released on June 4, 2021
Remove abstract tokens from graph keys in
rewrite_blockwise(dask#7721) Richard (Rick) ZamoraEnsure correct column order in csv
project_columns(dask#7761) Richard (Rick) ZamoraRenamed inner loop variables to avoid duplication (dask#7741) Boaz Mohar
Do not return delayed object from
to_zarr(dask#7738) Chris RoatArray: correct number of outputs in
apply_gufunc(dask#7669) Gabe JosephRewrite
da.fromfunctionwithda.blockwise(dask#7704) John A KirkhamRename
make_meta_utiltomake_meta(dask#7743) GALI PREM SAGARRepartition before shuffle if the requested partitions are less than input partitions (dask#7715) Vibhu Jawa
Blockwise: handle constant key inputs (dask#7734) Mads R. B. Kristensen
Added raise to
apply_gufunc(dask#7744) Boaz MoharShow failing tests summary in CI (dask#7735) Genevieve Buckley
sizeofsets in Python 3.9 (dask#7739) Mads R. B. KristensenWarn if using pandas datetimelike string in
dataframe.__getitem__(dask#7749) Julia SignellHighlight the
client.dashboard_link(dask#7747) Genevieve BuckleyEasier link for subscribing to the Google calendar (dask#7733) Genevieve Buckley
Automatically show graph visualization in Jupyter notebooks (dask#7716) Genevieve Buckley
Add
autofunctionforunify_chunksin API docs (dask#7730) James Bourbeau
2021.05.1#
Released on May 28, 2021
Pandas compatibility (dask#7712) Julia Signell
Fix
optimize_dataframe_getitembug (dask#7698) Richard (Rick) ZamoraUpdate
make_metaimport in docs (dask#7713) Benjamin ZaitlenFix format string in error message (dask#7706) Jiaming Yuan
Fix
read_sql_tablereturning wrong result for single column loads (dask#7572) c-thielAdd slack join link in
support.rst(dask#7679) Naty ClementiRemove unused alphabet variable (dask#7700) James Bourbeau
Fix meta creation incase of
object(dask#7586) GALI PREM SAGARAdd dispatch for
union_categoricals(dask#7699) GALI PREM SAGARConsolidate array
Dispatchobjects (dask#7505) James BourbeauMove DataFrame
dispatch.registersto their own file (dask#7503) Julia SignellFix delayed with
dataclasseswhereinit=False(dask#7656) Julia SignellAllow a column to be named
divisions(dask#7605) Julia SignellStack nd array with unknown chunks (dask#7562) Chris Roat
Promote the 2021 Dask User Survey (dask#7694) Genevieve Buckley
Fix typo in
DataFrame.set_index()(dask#7691) James LambCleanup array API reference links (dask#7684) David Hoese
Accept
axistuple forflipto be consistent with NumPy (dask#7675) Andrew ChampionBump
pre-commithook versions (dask#7676) James BourbeauCleanup
to_zarrdocstring (dask#7683) David HoeseFix the docstring of
read_orc(dask#7678) Justus MaginDoc
ipyparallel&mpi4pyconcurrent.futures(dask#7665) John A KirkhamUpdate tests to support CuPy 9 (dask#7671) Peter Andreas Entschev
Fix some
HighLevelGraphdocumentation inaccuracies (dask#7662) Mads R. B. KristensenFix spelling in Series
getitemerror message (dask#7659) Maisie Marshall
2021.05.0#
Released on May 14, 2021
Remove deprecated
kindkwarg to comply with pandas 1.3.0 (dask#7653) Julia SignellFix bug in DataFrame column projection (dask#7645) Richard (Rick) Zamora
Merge global annotations when packing (dask#7565) Mads R. B. Kristensen
Avoid
inplace=in pandasset_categories(dask#7633) James BourbeauChange the active-fusion default to
Falsefor Dask-Dataframe (dask#7620) Richard (Rick) ZamoraArray: remove extraneous code from
RandomState(dask#7487) Gabe JosephImplement
str.concatwhenothers=None(dask#7623) Daniel Mesejo-LeónFix
dask.dataframein sandboxed environments (dask#7601) Noah D. BrenowitzSupport for
cupyx.scipy.linalg(dask#7563) Benjamin ZaitlenMove
timeseriesand daily-stock toBlockwise(dask#7615) Richard (Rick) ZamoraFix bugs in broadcast join (dask#7617) Richard (Rick) Zamora
Use
Blockwisefor DataFrame IO (parquet, csv, and orc) (dask#7415) Richard (Rick) ZamoraAdding chunk & type information to Dask
HighLevelGraphs (dask#7309) Genevieve BuckleyRemove skip on test freq (dask#7608) Julia Signell
Remove
ignore_abc_warning(dask#7606) Julia SignellHarden DataFrame merge between column-selection and index (dask#7575) Richard (Rick) Zamora
Get rid of
ignore_abcdecorator (dask#7604) Julia SignellRemove kwarg validation for bokeh (dask#7597) Julia Signell
Add
lokyexample (dask#7590) Naty ClementiDelayed:
noutwhen arguments become tasks (dask#7593) Gabe JosephUpdate distributed version in mindep CI build (dask#7602) James Bourbeau
Support all or no overlap between partition columns and real columns (dask#7541) Richard (Rick) Zamora
2021.04.1#
Released on April 23, 2021
Handle
BlockwiseHLG pack/unpack forconcatenate=True(dask#7455) Richard (Rick) Zamoramap_partitions: use tokenized info as name of theSubgraphCallable(dask#7524) Mads R. B. KristensenUsing
tmp_pathandtmpdirto avoid temporary files and directories hanging in the repo (dask#7592) Naty ClementiContributing to docs (development guide) (dask#7591) Naty Clementi
Add more packages to Python 3.9 CI build (dask#7588) James Bourbeau
Array: Fix NEP-18 dispatching in finalize (dask#7508) Gabe Joseph
Misc fixes for
numpydoc(dask#7569) Matthias BussonnierAvoid pandas
level=keyword deprecation (dask#7577) James BourbeauMap e.g.
.repartition(freq="M")to.repartition(freq="MS")(dask#7504) Ruben van de GeerRemove hash seeding in parallel CI runs (dask#7128) Elliott Sales de Andrade
Add defaults in parameters in
to_parquet(dask#7564) Ray BellSimplify transpose axes cleanup (dask#7561) Julia Signell
Make
ValueError in len(index_names) > 1explicit it’s usingfastparquet(dask#7556) Ray BellFix
dict-column appending forpyarrowparquet engines (dask#7527) Richard (Rick) ZamoraAdd a documentation auto label (dask#7560) Doug Davis
Add
dask.delayed.Delayedto docs so it can be referenced by other sphinx docs (dask#7559) Doug DavisFix upstream
idxmaxminfor unevensplit_every(dask#7538) Julia SignellMake
normalize_tokenfor pandasSeries/DataFramefuture proof (no direct block access) (dask#7318) Joris Van den BosscheRedesigned
__setitem__implementation (dask#7393) David Hassellhistogram,histogramddimprovements (docs; return consistencies) (dask#7520) Doug DavisForce nightly
pyarrowin the upstream build (dask#7530) Joris Van den BosscheFix Configuration Reference (dask#7533) Benjamin Zaitlen
Use
.to_parquetondask.dataframein doc string (dask#7528) Ray BellAvoid double
msgpackserialization of HLGs (dask#7525) Mads R. B. KristensenEncourage usage of
yaml.safe_load()in configuration doc (dask#7529) Hristo GeorgievFix
reshapebug. Add relevant test. Fixes #7171. (dask#7523) JSKenyonSupport
custom_metadata=argument into_parquet(dask#7359) Richard (Rick) ZamoraClean some documentation warnings (dask#7518) Daniel Mesejo-León
Getting rid of more docs warnings (dask#7426) Julia Signell
Added
product(alias ofprod) (dask#7517) Freyam MehtaFix upstream
__array_ufunc__tests (dask#7494) Julia SignellEscape from
map_overlaptomap_blocksif depth is zero (dask#7481) Genevieve BuckleyAdd
check_typeto arrayassert_eq(dask#7491) Julia Signell
2021.04.0#
Released on April 2, 2021
Adding support for multidimensional histograms with
dask.array.histogramdd(dask#7387) Doug DavisUpdate docs on number of threads and workers in default
LocalCluster(dask#7497) cameron16Add labels automatically when certain files are touched in a PR (dask#7506) Julia Signell
Extract
ignore_orderfromkwargs(dask#7500) GALI PREM SAGAROnly provide installation instructions when distributed is missing (dask#7498) Matthew Rocklin
Start adding
isort(dask#7370) Julia SignellAdd
ignore_orderparameter indd.concat(dask#7473) Daniel Mesejo-LeónUse powers-of-two when displaying RAM (dask#7484) crusaderky
Added License Classifier (dask#7485) Tom Augspurger
Replace conda with mamba (dask#7227) crusaderky
Fix typo in array docs (dask#7478) James Lamb
Use
concurrent.futuresin local scheduler (dask#6322) John A Kirkham
2021.03.1#
Released on March 26, 2021
Add a dispatch for
is_categorical_dtypeto handle non-pandas objects (dask#7469) brandon-b-millerUse
multiprocessing.Poolintest_read_text(dask#7472) John A KirkhamAdd missing
metakwarg to gufunc class (dask#7423) Peter Andreas EntschevExample for memory-mapped Dask array (dask#7380) Dieter Weber
Fix NumPy upstream failures
xfailpandas and fastparquet failures (dask#7441) Julia SignellFix bug in repartition with freq (dask#7357) Ruben van de Geer
Fix
__array_function__dispatching fortril/triu(dask#7457) Peter Andreas EntschevUse
concurrent.futures.Executorsin a few tests (dask#7429) John A KirkhamRequire NumPy >=1.16 (dask#7383) crusaderky
Minor
sort_valueshousekeeping (dask#7462) Ryan WilliamsEnsure natural sort order in parquet part paths (dask#7249) Ryan Williams
Remove global env mutation upon running
test_config.py(dask#7464) Hristo GeorgievUpdate NumPy intersphinx URL (dask#7460) Gabe Joseph
Add
rot90(dask#7440) Trevor ManzUpdate docs for required package for endpoint (dask#7454) Nick Vazquez
Master -> main in
slice_arraydocstring (dask#7453) Gabe JosephExpand
dask.utils.is_arraylikedocstring (dask#7445) Doug DavisSimplify
BlockwiseIODepsimporting (dask#7420) Richard (Rick) ZamoraUpdate layer annotation packing method (dask#7430) James Bourbeau
Drop duplicate test in
test_describe_empty(dask#7431) John A KirkhamAdd
Series.dotmethod to dataframe module (dask#7236) Madhu94Added df
kurtosis-method and testing (dask#7273) Jan BorchmannAvoid quadratic-time performance for HLG culling (dask#7403) Bruce Merry
Temporarily skip problematic
sparsetest (dask#7421) James BourbeauUpdate some CI workflow names (dask#7422) James Bourbeau
Fix HDFS test (dask#7418) Julia Signell
Make changelog subtitles match the hierarchy (dask#7419) Julia Signell
Add support for normalize in
value_counts(dask#7342) Julia SignellAvoid unnecessary imports for HLG Layer unpacking and materialization (dask#7381) Richard (Rick) Zamora
Bincount fix slicing (dask#7391) Genevieve Buckley
Add
sliding_window_view(dask#7234) Deepak CherianFix typo in
docs/source/develop.rst(dask#7414) Hristo GeorgievSwitch documentation builds for PRs to readthedocs (dask#7397) James Bourbeau
Adds
sort_valuesto dask.DataFrame (dask#7286) gerrymanoimPin
sqlalchemy<1.4.0in CI (dask#7405) James BourbeauComment fixes (dask#7215) Ryan Williams
Dead code removal / fixes (dask#7388) Ryan Williams
Use single thread for
pa.Table.from_pandascalls (dask#7347) Richard (Rick) ZamoraReplace
'container'with'image'(dask#7389) James LambPass delimiter to
fsspecinbag.read_text(dask#7349) Martin DurantEmbed literals in
SubgraphCallablewhen packingBlockwise(dask#7353) Mads R. B. KristensenUpdate
test_hdf.pyto not reuse file handlers (dask#7044) rs9w33Require additional dependencies: cloudpickle, partd, fsspec, toolz (dask#7345) Julia Signell
Prepare
Blockwise+ IO infrastructure (dask#7281) Richard (Rick) ZamoraRemove duplicated imports from
test_slicing.py(dask#7365) Hristo GeorgievAdd test deps for pip development (dask#7360) Julia Signell
Support int slicing for non-NumPy arrays (dask#7364) Peter Andreas Entschev
Automatically cancel previous CI builds (dask#7348) James Bourbeau
dask.array.asarrayshould handle case wherexarrayclass is in top-level namespace (dask#7335) Tom WhiteHighLevelGraphlength without materializing layers (dask#7274) Gabe JosephDrop support for Python 3.6 (dask#7006) James Bourbeau
Fix fsspec usage in
create_metadata_file(dask#7295) Richard (Rick) ZamoraChange default branch from master to main (dask#7198) Julia Signell
Add Xarray to CI software environment (dask#7338) James Bourbeau
Update repartition argument name in error text (dask#7336) Eoin Shanaghy
Run upstream tests based on commit message (dask#7329) James Bourbeau
Use
pytest.register_assert_rewriteon util modules (dask#7278) Bruce MerryAdd example on using specific chunk sizes in
from_array()(dask#7330) James LambMove NumPy skip into test (dask#7247) Julia Signell
2021.03.0#
Released on March 5, 2021
Note
This is the first release with support for Python 3.9 and the last release with support for Python 3.6
Bump minimum version of
distributed(dask#7328) James BourbeauFix
percentiles_summarywithdask_cudf(dask#7325) Peter Andreas EntschevTemporarily revert recent
Array.__setitem__updates (dask#7326) James BourbeauBlockwise.clone(dask#7312) crusaderkyNEP-35 duck array update (dask#7321) James Bourbeau
Don’t allow setting
.namefor array (dask#7222) Julia SignellUse nearest interpolation for creating percentiles of integer input (dask#7305) Kyle Barron
Test
expwith CuPy arrays (dask#7322) John A KirkhamCheck that computed chunks have right size and dtype (dask#7277) Bruce Merry
pytest.mark.flaky(dask#7319) crusaderkyContributing docs: add note to pull the latest git tags before pip installing Dask (dask#7308) Genevieve Buckley
Support for Python 3.9 (dask#7289) crusaderky
Add broadcast-based merge implementation (dask#7143) Richard (Rick) Zamora
Add
split_everytograph_manipulation(dask#7282) crusaderkyTypo in optimize docs (dask#7306) Julius Busecke
dask.graph_manipulationsupport forxarray.Dataset(dask#7276) crusaderkyAdd plot width and height support for Bokeh 2.3.0 (dask#7297) James Bourbeau
Add NumPy functions
tri,triu_indices,triu_indices_from,tril_indices,tril_indices_from(dask#6997) IllviljanRemove “cleanup” task in DataFrame on-disk shuffle (dask#7260) Sinclair Target
Use development version of
distributedin CI (dask#7279) James BourbeauMoving high level graph pack/unpack Dask (dask#7179) Mads R. B. Kristensen
Improve performance of
merge_percentiles(dask#7172) Ashwin SrinathExample for working with categoricals and parquet (dask#7085) McToel
Adds tree reduction to
bincount(dask#7183) Thomas J. FanImprove documentation of
nameinfrom_array(dask#7264) Bruce MerryFix
cumsumfor empty partitions (dask#7230) Julia SignellAdd
map_blocksexample to dask array creation docs (dask#7221) Julia SignellFix performance issue in
dask.graph_manipulation.wait_on()(dask#7258) crusaderkyReplace coveralls with codecov.io (dask#7246) crusaderky
Pin to a particular
blackrev in pre-commit (dask#7256) Julia SignellMinor typo in documentation:
array-chunks.rst(dask#7254) Magnus NordFix bugs in
BlockwiseandShuffleLayer(dask#7213) Richard (Rick) ZamoraFix parquet filtering bug for
"pyarrow-dataset"with pyarrow-3.0.0 (dask#7200) Richard (Rick) Zamoragraph_manipulationwithout NumPy (dask#7243) crusaderkySupport for NEP-35 (dask#6738) Peter Andreas Entschev
Avoid running unit tests during doctest CI build (dask#7240) James Bourbeau
Run doctests on CI (dask#7238) Julia Signell
Cleanup code quality on set arithmetics (dask#7196) crusaderky
Add
dask.array.delete(dask#7125) Julia SignellUnpin graphviz now that new conda-forge recipe is built (dask#7235) Julia Signell
Don’t use NumPy 1.20 from conda-forge on Mac (dask#7211) crusaderky
map_overlap: Don’t rechunk axes without overlap (dask#7233) Deepak CherianPin graphviz to avoid issue with latest conda-forge build (dask#7232) Julia Signell
Use
html_css_filesin docs for custom CSS (dask#7220) James BourbeauGraph manipulation:
clone,bind,checkpoint,wait_on(dask#7109) crusaderkyFix handling of filter expressions in parquet
pyarrow-datasetengine (dask#7186) Joris Van den BosscheExtend
__setitem__to more closely match numpy (dask#7033) David HassellClean up Python 2 syntax (dask#7195) crusaderky
Fix regression in
Delayed._length(dask#7194) crusaderky__dask_layers__()tests and tweaks (dask#7177) crusaderkyProperly convert
HighLevelGraphin multiprocessing scheduler (dask#7191) Jim Crist-HarifDon’t fail fast in CI (dask#7188) James Bourbeau
2021.02.0#
Released on February 5, 2021
Add
percentilesupport for NEP-35 (dask#7162) Peter Andreas EntschevAdded support for
Float64in column assignment (dask#7173) Nils BraunCoarsen rechunking error (dask#7127) Davis Bennett
Fix upstream CI tests (dask#6896) Julia Signell
Revise
HighLevelGraphMapping API (dask#7160) crusaderkyUpdate low-level graph spec to use any hashable for keys (dask#7163) James Bourbeau
Generically rebuild a collection with different keys (dask#7142) crusaderky
Allow
dask.array.ravelto acceptarray_likeargument (dask#7138) D-StacksFixes link in array design doc (dask#7152) Thomas J. Fan
Fix example of using
blockwisefor an outer product (dask#7119) Bruce MerryDeprecate
HighlevelGraph.dictsin favor of.layers(dask#7145) Amit KumarAlign
FastParquetEnginewith pyarrow engines (dask#7091) Richard (Rick) ZamoraSimplify contents of parts list in
read_parquet(dask#7066) Richard (Rick) Zamoracheck_meta(): use__class__when checking DataFrame types (dask#7099) Mads R. B. KristensenFix parquet
getitemoptimization (dask#7106) Richard (Rick) ZamoraAdd cytoolz back to CI environment (dask#7103) James Bourbeau
2021.01.1#
Released on January 22, 2021
Partially fix
cumprod(dask#7089) Julia SignellTest pandas 1.1.x / 1.2.0 releases and pandas nightly (dask#6996) Joris Van den Bossche
Use assign to avoid
SettingWithCopyWarning(dask#7092) Julia Signell'mode'argument passed tobokeh.output_file()(dask#7034) (dask#7075) patquemSkip empty partitions when doing
groupby.value_counts(dask#7073) Julia SignellAdd error messages to
assert_eq()(dask#7083) James Lamb
2021.01.0#
Released on January 15, 2021
map_partitionswith review comments (dask#6776) Kumar Bharath PrabhuMake sure that
populationis a real list (dask#7027) Julia SignellPropagate
storage_optionsinread_csv(dask#7074) Richard (Rick) ZamoraRemove all
BlockwiseIOcode (dask#7067) Richard (Rick) ZamoraFix CI (dask#7069) James Bourbeau
Add option to control rechunking in
reshape(dask#6753) Tom AugspurgerFix
linalg.lstsqfor complex inputs (dask#7056) Johnnie GrayAdd
compression='infer'default toread_csv(dask#6960) Richard (Rick) ZamoraRevert parameter changes in
svd_compressed#7003 (dask#7004) Eric CzechSkip failing s3 test (dask#7064) Martin Durant
Revert
BlockwiseIO(dask#7048) Richard (Rick) ZamoraAdd some cross-references to
DataFrame.to_bag()andSeries.to_bag()(dask#7049) Rob MaloufRewrite
matmulasblockwisewithout contraction/concatenate (dask#7000) Rafal WojdylaUse
functools.cached_propertyinda.shape(dask#7023) IllviljanUse meta value in series
non_empty(dask#6976) Julia SignellRevert “Temporarly pin sphinx version to 3.3.1 (dask#7002)” (dask#7014) Rafal Wojdyla
Revert
python-graphvizpinning (dask#7037) Julia SignellAccidentally committed print statement (dask#7038) Julia Signell
Pass
dropnaandobservedinagg(dask#6992) Julia SignellAdd index to
metaafter.str.splitwith expand (dask#7026) Ruben van de GeerCI: test pyarrow 2.0 and nightly (dask#7030) Joris Van den Bossche
Temporarily pin
python-graphvizin CI (dask#7031) James BourbeauUnderline section in
numpydoc(dask#7013) Matthias BussonnierKeep normal optimizations when adding custom optimizations (dask#7016) Matthew Rocklin
Temporarily pin sphinx version to 3.3.1 (dask#7002) Rafal Wojdyla
DOC: Misc formatting (dask#6998) Matthias Bussonnier
Add
inline_arrayoption tofrom_array(dask#6773) Tom AugspurgerRevert “Initial pass at blockwise array creation routines (dask#6931)” (:pr:`6995) James Bourbeau
Set
npartitionsinset_index(dask#6978) Julia SignellUpstream
configserialization and inheritance (dask#6987) Jacob TomlinsonBump the minimum time in
test_minimum_time(dask#6988) Martin DurantFix pandas
dtypeinference forread_parquet(dask#6985) Richard (Rick) ZamoraAvoid data loss in
set_indexwithsorted=True(dask#6980) Richard (Rick) ZamoraBugfix in
read_parquetfor handling un-named indices withindex=False(dask#6969) Richard (Rick) ZamoraUse
__class__when comparing meta data (dask#6981) Mads R. B. KristensenComparing string versions won’t always work (dask#6979) Rafal Wojdyla
Initial pass at blockwise array creation routines (dask#6931) Ian Rose
Simplify
has_parallel_type()(dask#6927) Mads R. B. KristensenHandle annotation unpacking in
BlockwiseIO(dask#6934) Simon PerkinsAvoid deprecated
yield_fixtureintest_sql.py(dask#6968) Richard (Rick) ZamoraRemove bad graph logic in
BlockwiseIO(dask#6933) Richard (Rick) ZamoraGet config item if variable is
None(dask#6862) Jacob TomlinsonUpdate
from_pandasdocstring (dask#6957) Richard (Rick) ZamoraPrevent
fuse_rootsfrom clobbering annotations (dask#6955) Simon Perkins
2020.12.0#
Released on December 10, 2020
Highlights#
Switched to CalVer for versioning scheme.
Introduced new APIs for
HighLevelGraphto enable sending high-level representations of task graphs to the distributed scheduler.Introduced new
HighLevelGraphlayer objects includingBasicLayer,Blockwise,BlockwiseIO,ShuffleLayer, and more.Added support for applying custom
Layer-level annotations likepriority,retries, etc. with thedask.annotationscontext manager.Updated minimum supported version of pandas to 0.25.0 and NumPy to 1.15.1.
Support for the
pyarrow.datasetAPI toread_parquet.Several fixes to Dask Array’s SVD.
All changes#
Make
observedkwarg optional (dask#6952) Julia SignellMin supported pandas 0.25.0 numpy 1.15.1 (dask#6895) Julia Signell
Make order of categoricals unambiguous (dask#6949) Julia Signell
Improve “pyarrow-dataset” statistics performance for
read_parquet(dask#6918) Richard (Rick) ZamoraAdd
observedkeyword togroupby(dask#6854) Julia SignellMake sure
include_path_columnworks when there are multiple partitions per file (dask#6911) Julia SignellFix:
array.overlapandarray.map_overlapblock sizes are incorrect when depth is an unsigned bit type (dask#6909) GFleishmanReturn a
Bagfromsample(dask#6941) Shang WangEnable parquet metadata collection in parallel (dask#6921) Richard (Rick) Zamora
Avoid using
_fileinprogressbarif it isNone(dask#6938) Mark HarfoucheAdd Zarr to upstream CI build (dask#6932) James Bourbeau
Introduce
BlockwiseIOlayer (dask#6878) Richard (Rick) ZamoraTransmit
LayerAnnotations to Scheduler (dask#6889) Simon PerkinsUpdate opportunistic caching page to remove experimental warning (dask#6926) Timost
Allow
pyarrow >2.0.0(dask#6772) Richard (Rick) ZamoraSupport
pyarrow.datasetAPI forread_parquet(dask#6534) Richard (Rick) ZamoraAdd more informative error message to
da.coarsenwhen coarsening factors do not divide shape (dask#6908) Davis BennettOnly run the cron CI on
dask/dasknot forks (dask#6905) Jacob TomlinsonAdd
annotationstoShuffleLayers(dask#6913) Matthew RocklinTemporarily xfail
test_from_s3(dask#6915) James BourbeauAdded dataframe
skewmethod (dask#6881) Jan BorchmannFix
dtypein arraymeta(dask#6893) Julia SignellMissing
namearg inhelm install ...(dask#6903) Ruben van de GeerFix: exception when reading an item with filters (dask#6901) Martin Durant
Add support for
cupyxsparse todask.array.dot(dask#6846) Akira NarusePin array mindeps up a bit to get the tests to pass [test-mindeps] (dask#6894) Julia Signell
Update/remove pandas and numpy in mindeps (dask#6888) Julia Signell
Fix
ArrowEnginebug in use ofclear_known_categories(dask#6887) Richard (Rick) ZamoraFix documentation about task scheduler (dask#6879) Zhengnan Zhao
Add human relative time formatting utility (dask#6883) Jacob Tomlinson
Possible fix for 6864
set_indexissue (dask#6866) Richard (Rick) ZamoraBasicLayer: remove dependency arguments (dask#6859) Mads R. B. KristensenSerialization of
Blockwise(dask#6848) Mads R. B. KristensenAddress
columns=[]bug (dask#6871) Richard (Rick) ZamoraAvoid duplicate parquet schema communication (dask#6841) Richard (Rick) Zamora
Add
create_metadata_fileutility for existing parquet datasets (dask#6851) Richard (Rick) ZamoraImprove ordering for workloads with a common terminus (dask#6779) Tom Augspurger
Stringify utilities (dask#6852) Mads R. B. Kristensen
Add keyword
overwrite=Truetoto_parquetto remove dangling files when overwriting a pyarrowDataset. (dask#6825) Greg HayesRemoved
map_tasks()andmap_basic_layers()(dask#6853) Mads R. B. KristensenIntroduce QR iteration to
svd_compressed(dask#6813) RogerMoens__dask_distributed_pack__()now takes aclientargument (dask#6850) Mads R. B. KristensenUse
map_partitionsinstead ofdelayedinset_index(dask#6837) Mads R. B. KristensenAdd doc hit for
as_completed().update(futures)(dask#6817) manuelsBump GHA
setup-minicondaversion (dask#6847) Jacob TomlinsonRemove nans when setting sorted index (dask#6829) Rockwell Weiner
Fix transpose of u in SVD (dask#6799) RogerMoens
Migrate to GitHub Actions (dask#6794) Jacob Tomlinson
Fix sphinx
currentmoduleusage (dask#6839) James BourbeauFix minimum dependencies CI builds (dask#6838) James Bourbeau
Avoid graph materialization during
Blockwiseculling (dask#6815) Richard (Rick) ZamoraFixed typo (dask#6834) Devanshu Desai
Use
HighLevelGraph.mergeincollections_to_dsk(dask#6836) Mads R. B. KristensenRespect
dtypein svdcompression_matrix#2849 (dask#6802) RogerMoensAdd blocksize to task name (dask#6818) Julia Signell
Check for all-NaN partitions (dask#6821) Rockwell Weiner
Change “institutional” SQL doc section to point to main SQL doc (dask#6823) Martin Durant
Fix:
DataFrame.joindoesn’t accept Series as other (dask#6809) David KatzRemove
to_delayedoperations fromto_parquet(dask#6801) Richard (Rick) ZamoraLayer annotation docstrings improvements (dask#6806) Simon Perkins
Avro reader (dask#6780) Martin Durant
Rechunk array if smallest chunk size is smaller than depth (dask#6708) Julia Signell
Add Layer Annotations (dask#6767) Simon Perkins
Add optional IO-subgraph to
BlockwiseLayers (dask#6715) Richard (Rick) ZamoraAdd high level graph pack/unpack for distributed (dask#6786) Mads R. B. Kristensen
Add missing methods of the Dataframe API (dask#6789) Stephannie Jimenez Gacha
Add doc on managing environments (dask#6778) Martin Durant
HLG:
get_all_external_keys()(dask#6774) Mads R. B. KristensenAvoid rechunking in reshape with
chunksize=1(dask#6748) Tom AugspurgerTry to make categoricals work on join (dask#6205) Julia Signell
Fix some minor typos and trailing whitespaces in
array-slice.rst(dask#6771) Magnus NordBugfix for parquet metadata writes of empty dataframe partitions (pyarrow) (dask#6741) Callum Noble
Document
metakwarg inmap_blocksandmap_overlap. (dask#6763) Peter Andreas EntschevBegin experimenting with parallel prefix scan for
cumsumandcumprod(dask#6675) Erik WelchClarify differences in boolean indexing between dask and numpy arrays (dask#6764) Illviljan
Efficient serialization of shuffle layers (dask#6760) James Bourbeau
Config array optimize to skip fusion and return a HLG (dask#6751) Mads R. B. Kristensen
Temporarily use
pyarrow<2in CI (dask#6759) James BourbeauFix meta for
min/maxreductions (dask#6736) Peter Andreas EntschevAdd 2D possibility to
da.linalg.lstsq- mirroring numpy (dask#6749) Pascal BourgaultCI: Fixed bug causing flaky test failure in pivot (dask#6752) Tom Augspurger
Serialization of layers (dask#6693) Mads R. B. Kristensen
Add
attrsproperty to Series/Dataframe (dask#6742) IllviljanRemoved Mutable Default Argument (dask#6747) Mads R. B. Kristensen
Adjust parquet
ArrowEngineto allow more easy subclass for writing (dask#6505) Joris Van den BosscheAdd
ShuffleStageHLG Layer (dask#6650) Richard (Rick) ZamoraHandle literal in
meta_from_array(dask#6731) Peter Andreas EntschevDo balanced rechunking even if chunks are the same (dask#6735) Chris Roat
Fix docstring
DataFrame.set_index(dask#6739) Gil ForsythEnsure
HighLevelGraphlayers always containLayerinstances (dask#6716) James BourbeauMap on
HighLevelGraphLayers (dask#6689) Mads R. B. KristensenUpdate overlap
*_likefunction calls and CuPy tests (dask#6728) Peter Andreas EntschevFixes for
svdwith__array_function__(dask#6727) Peter Andreas EntschevAdded doctest extension for documentation (dask#6397) Jim Circadian
Minor fix to #5628 using @pentschev’s suggestion (dask#6724) John A Kirkham
Change type of Dask array when meta type changes (dask#5628) Matthew Rocklin
HLG:
get_dependencies()of single keys (dask#6699) Mads R. B. KristensenRevert “Revert “Use HighLevelGraph layers everywhere in collections (dask#6510)” (dask#6697)” (dask#6707) Tom Augspurger
Allow
*_likearray creation functions to respect input array type (dask#6680) Genevieve BuckleyUpdate
dask-sphinx-themeversion (dask#6700) Gil Forsyth
2.30.0 / 2020-10-06#
Array#
Allow
rechunkto evenly split into N chunks (dask#6420) Scott Sievert
2.29.0 / 2020-10-02#
Array#
_repr_html_: color sides darker instead of drawing all the lines (dask#6683) Julia SignellRemoves warning from
nanstdandnanvar(dask#6667) Thomas J. FanGet shape of output from original array -
map_overlap(dask#6682) Julia SignellReplace
np.searchsortedwithbisectin indexing (dask#6669) Joachim B Haga
Bag#
Make sure subprocesses have a consistent hash for bag
groupby(dask#6660) Itamar Turner-Trauring
Core#
Revert “Use
HighLevelGraphlayers everywhere in collections (dask#6510)” (dask#6697) Tom AugspurgerUse
pandas.testing(dask#6687) John A KirkhamImprove 128-bit floating-point skip in tests (dask#6676) Elliott Sales de Andrade
DataFrame#
Allow setting dataframe items using a bool dataframe (dask#6608) Julia Signell
Documentation#
2.28.0 / 2020-09-25#
Array#
Partially reverted changes to
Arrayindexing that produces large changes. This restores the behavior from Dask 2.25.0 and earlier, with a warning when large chunks are produced. A configuration option is provided to avoid creating the large chunks, see Efficiency. (dask#6665) Tom AugspurgerAdd
metatoto_dask_array(dask#6651) Kyle NicholsonFix dask#6631 and dask#6611 (dask#6632) Rafal Wojdyla
Infer object in array reductions (dask#6629) Daniel Saxton
Adding
v_basedflag forsvd_flip(dask#6658) Eric CzechFix flakey array
mean(dask#6656) Sam Grayson
Core#
Removed
dskequality check fromSubgraphCallable.__eq__(dask#6666) Mads R. B. KristensenUse
HighLevelGraphlayers everywhere in collections (dask#6510) Mads R. B. KristensenAdds hash dunder method to
SubgraphCallablefor caching purposes (dask#6424) Andrew FultonStop writing commented out config files by default (dask#6647) Matthew Rocklin
DataFrame#
Add support for collect list aggregation via
aggAPI (dask#6655) Madhur TandonSlightly better error message (dask#6657) Julia Signell
2.27.0 / 2020-09-18#
Array#
Preserve
dtypeinsvd(dask#6643) Eric Czech
Core#
store(): create a single HLG layer (dask#6601) Mads R. B. KristensenAdd pre-commit CI build (dask#6645) James Bourbeau
Update
.pre-commit-configto latest black. (dask#6641) Julia SignellUpdate super usage to remove Python 2 compatibility (dask#6630) Poruri Sai Rahul
Remove u string prefixes (dask#6633) Poruri Sai Rahul
DataFrame#
Improve error message for
to_sql(dask#6638) Julia SignellUse empty list as categories (dask#6626) Julia Signell
Documentation#
Add
autofunctionto array api docs for more ufuncs (dask#6644) James BourbeauAdd a number of missing ufuncs to
dask.arraydocs (dask#6642) Ralf GommersAdd
HelmClusterdocs (dask#6290) Jacob Tomlinson
2.26.0 / 2020-09-11#
Array#
Backend-aware dtype inference for single-chunk svd (dask#6623) Eric Czech
Make
array.reductiondocstring match for dtype (dask#6624) Martin DurantSet lower bound on compression level for
svd_compressedusing rows and cols (dask#6622) Eric CzechImprove SVD consistency and small array handling (dask#6616) Eric Czech
Add
svd_flip#6599 (dask#6613) Eric CzechHandle sequences containing dask Arrays (dask#6595) Gabe Joseph
Avoid large chunks from
getitemwith lists (dask#6514) Tom AugspurgerEagerly slice numpy arrays in
from_array(dask#6605) Deepak CherianRestore ability to pickle dask arrays (dask#6594) Noah D. Brenowitz
Add SVD support for short-and-fat arrays (dask#6591) Eric Czech
Add simple chunk type registry and defer as appropriate to upcast types (dask#6393) Jon Thielen
Align coarsen chunks by default (dask#6580) Deepak Cherian
Fixup reshape on unknown dimensions and other testing fixes (dask#6578) Ryan Williams
Core#
Add validation and fixes for
HighLevelGraphdependencies (dask#6588) Mads R. B. KristensenFix linting issue (dask#6598) Tom Augspurger
Skip
bokehversion 2.0.0 (dask#6572) John A Kirkham
DataFrame#
Added bytes/row calculation when using meta (dask#6585) McToel
Handle
min_countinSeries.sum/prod(dask#6618) Daniel SaxtonAlways compute 0 and 1 quantiles during quantile calculations (dask#6564) Erik Welch
Fix wrong path when reading empty csv file (dask#6573) Abdulelah Bin Mahfoodh
Documentation#
Doc: Troubleshooting dashboard 404 (dask#6215) Kilian Lieret
Fixup
extraConfigexample (dask#6625) Tom AugspurgerUpdate supported Python versions (dask#6609) Julia Signell
Document dask/daskhub helm chart (dask#6560) Tom Augspurger
2.25.0 / 2020-08-28#
Core#
Compare key hashes in
subs()(dask#6559) Mads R. B. KristensenRerun with latest
blackrelease (dask#6568) James BourbeauLicense update (dask#6554) Tom Augspurger
DataFrame#
Documentation#
Remove version from documentation page names (dask#6558) James Bourbeau
Update
kubernetes-helm.rst(dask#6523) David SheldonStop 2020 survey (dask#6547) Tom Augspurger
2.24.0 / 2020-08-22#
Array#
Fix setting random seed in tests. (dask#6518) Elliott Sales de Andrade
Support meta in apply gufunc (dask#6521) joshreback
Replace cupy.sparse with cupyx.scipy.sparse (dask#6530) John A Kirkham
Dataframe#
Bump up tolerance for rolling tests (dask#6502) Julia Signell
Implement DatFrame.__len__ (dask#6515) Tom Augspurger
Infer arrow schema in to_parquet (for ArrowEngine`) (dask#6490) Richard (Rick) Zamora
Fix parquet test when no pyarrow (dask#6524) Martin Durant
Remove problematic
filterarguments in ArrowEngine (dask#6527) Richard (Rick) ZamoraAvoid schema validation by default in ArrowEngine (dask#6536) Richard (Rick) Zamora
Core#
Use unpack_collections in make_blockwise_graph (dask#6517) Thomas J. Fan
Move key_split() from optimization.py to utils.py (dask#6529) Mads R. B. Kristensen
Make tests run on moto server (dask#6528) Martin Durant
2.23.0 / 2020-08-14#
Array#
Reduce
np.zeros,ones, andfullarray size with broadcasting (dask#6491) Matthias BussonnierAdd missing
meta=fortriminmap_overlap(dask#6494) Peter Andreas Entschev
Bag#
Bag repartition partition size (dask#6371) joshreback
Core#
Scalar.__dask_layers__()to returnself._nameinstead ofself.key(dask#6507) Mads R. B. KristensenUpdate dependencies correctly in
fuse_rootoptimization (dask#6508) Mads R. B. Kristensen
DataFrame#
Adds
itemsto dataframe (dask#6503) Thomas J. FanInclude compression in
write_tablecall (dask#6499) Julia SignellFixed warning in
nonempty_series(dask#6485) Tom AugspurgerIntelligently determine partitions based on type of first arg (dask#6479) Matthew Rocklin
Fix pyarrow
mkdirs(dask#6475) Julia SignellFix duplicate parquet output in
to_parquet(dask#6451) michaelnarodovitch
Documentation#
Fix documentation
da.histogram(dask#6439) Roberto PanaiFixed a few typos in the SQL docs (dask#6489) Mike McCarty
Docs for SQLing (dask#6453) Martin Durant
2.22.0 / 2020-07-31#
Array#
Compatibility for NumPy dtype deprecation (dask#6430) Tom Augspurger
Core#
Implement
sizeoffor somebytes-like objects (dask#6457) John A KirkhamHTTP error for new
fsspec(dask#6446) Martin DurantWhen
RecursionErroris raised, return uuid fromtokenizefunction (dask#6437) Julia SignellInstall deps of upstream-dev packages (dask#6431) Tom Augspurger
Use updated link in
setup.cfg(dask#6426) Zhengnan Zhao
DataFrame#
Add single quotes around column names if strings (dask#6471) Gil Forsyth
Refactor
ArrowEnginefor betterread_parquetperformance (dask#6346) Richard (Rick) ZamoraAdd
tolistdispatch (dask#6444) GALI PREM SAGARCompatibility with pandas 1.1.0rc0 (dask#6429) Tom Augspurger
Multi value pivot table (dask#6428) joshreback
Duplicate argument definitions in
to_csvdocstring (dask#6411) Jun Han (Johnson) Ooi
Documentation#
Add utility to docs to convert YAML config to env vars and back (dask#6472) Jacob Tomlinson
Fix parameter server rendering (dask#6466) Scott Sievert
Fixes broken links (dask#6403) Jim Circadian
Complete parameter server implementation in docs (dask#6449) Scott Sievert
Fix typo (dask#6436) Jack Xiaosong Xu
2.21.0 / 2020-07-17#
Array#
Correct error message in
array.routines.gradient()(dask#6417) johnomotaniFix blockwise concatenate for array with some
dimension=1(dask#6342) Matthias Bussonnier
Bag#
Fix
bag.takeexample (dask#6418) Roberto Panai
Core#
Groups values in optimization pass should only be graph and keys – not an optimization + keys (dask#6409) Benjamin Zaitlen
Call custom optimizations once, with
kwargsprovided (dask#6382) Clark ZinzowInclude
pickle5for testing on Python 3.7 (dask#6379) John A Kirkham
DataFrame#
Correct typo in error message (dask#6422) Tom McTiernan
Use
pytest.warnsto check forUserWarning(dask#6378) Richard (Rick) ZamoraParse
bytes_per_chunk keywordfrom string (dask#6370) Matthew Rocklin
Documentation#
Numpydoc formatting (dask#6421) Matthias Bussonnier
Unpin
numpydocfollowing 1.1 release (dask#6407) Gil ForsythNumpydoc formatting (dask#6402) Matthias Bussonnier
Add instructions for using conda when installing code for development (dask#6399) Ray Bell
Update
visualizedocstrings (dask#6383) Zhengnan Zhao
2.20.0 / 2020-07-02#
Array#
Register
sizeoffor numpy zero-strided arrays (dask#6343) Matthias BussonnierUse
concatenate_lookupinconcatenate(dask#6339) John A KirkhamFix rechunking of arrays with some zero-length dimensions (dask#6335) Matthias Bussonnier
DataFrame#
Dispatch
iloc`calls togetitem(dask#6355) Gil ForsythHandle unnamed pandas
RangeIndexin fastparquet engine (dask#6350) Richard (Rick) ZamoraPreserve index when writing partitioned parquet datasets with pyarrow (dask#6282) Richard (Rick) Zamora
Use
ignore_indexfor pandas’group_split_dispatch(dask#6251) Richard (Rick) Zamora
Documentation#
2.19.0 / 2020-06-19#
Array#
Cast chunk sizes to python int
dtype(dask#6326) Gil ForsythAdd
shape=Noneto*_like()array creation functions (dask#6064) Anderson Banihirwe
Core#
Update expected error msg for protocol difference in fsspec (dask#6331) Gil Forsyth
Fix for floats < 1 in
parse_bytes(dask#6311) Gil ForsythFix exception causes all over the codebase (dask#6308) Ram Rachum
Fix duplicated tests (dask#6303) James Lamb
Remove unused testing function (dask#6304) James Lamb
DataFrame#
Add high-level CSV Subgraph (dask#6262) Gil Forsyth
Fix
ValueErrorwhen merging an index-only 1-partition dataframe (dask#6309) Krishan BhasinMake
index.mapclear divisions. (dask#6285) Julia Signell
Documentation#
Add link to 2020 survey (dask#6328) Tom Augspurger
Update
bag.rst(dask#6317) Ben Shaver
2.18.1 / 2020-06-09#
Array#
Don’t try to set name on
full(dask#6299) Julia SignellHistogram: support lazy values for range/bins (another way) (dask#6252) Gabe Joseph
Core#
Fix exception causes in
utils.py(dask#6302) Ram RachumImprove performance of
HighLevelGraphconstruction (dask#6293) Julia Signell
Documentation#
Now readthedocs builds unrelased features’ docstrings (dask#6295) Antonio Ercole De Luca
Add
asyncsshintersphinx mappings (dask#6298) Jacob Tomlinson
2.18.0 / 2020-06-05#
Array#
Cast slicing index to dask array if same shape as original (dask#6273) Julia Signell
Fix
stackerror message (dask#6268) Stephanie Gottfull&full_like: error on non-scalarfill_value(dask#6129) HuiteSupport for multiple arrays in
map_overlap(dask#6165) Eric CzechPad resample divisions so that edges are counted (dask#6255) Julia Signell
Bag#
Random sampling of k elements from a dask bag #4799 (dask#6239) Antonio Ercole De Luca
DataFrame#
Add
dropna,sort, andascendingtosort_values(dask#5880) Julia SignellGeneralize
from_dask_array(dask#6263) GALI PREM SAGARAdd derived docstring for
SeriesGroupby.nunique(dask#6284) Julia SignellRemove
NotImplementedErrorin resample with rule (dask#6274) Abdulelah Bin MahfoodhAdd
dd.to_sql(dask#6038) Ryan Williams
Documentation#
2.17.2 / 2020-05-28#
Core#
Re-add the
completeextra (dask#6257) Jim Crist-Harif
DataFrame#
Raise error if
resampleisn’t going to give right answer (dask#6244) Julia Signell
2.17.1 / 2020-05-28#
Array#
Empty array rechunk (dask#6233) Andrew Fulton
Core#
Make
pyyamlrequired (dask#6250) Jim Crist-HarifFix install commands from
ImportError(dask#6238) Gaurav SheniRemove issue template (dask#6249) Jacob Tomlinson
DataFrame#
Pass
ignore_indextodd_shufflefromDataFrame.shuffle(dask#6247) Richard (Rick) ZamoraCope with missing HDF keys (dask#6204) Martin Durant
Generalize
describe&quantileapis (dask#5137) GALI PREM SAGAR
2.17.0 / 2020-05-26#
Array#
Bag#
Random Choice on Bags (dask#6208) Antonio Ercole De Luca
Core#
Raise warning
delayed.visualise()(dask#6216) Amol UmbarkarEnsure other pickle arguments work (dask#6229) John A Kirkham
Overhaul
fuse()config (dask#6198) crusaderkyUpdate
dask.order.orderto consider “next” nodes using both FIFO and LIFO (dask#5872) Erik Welch
DataFrame#
Use 0 as
fill_valuefor more agg methods (dask#6245) Julia SignellGeneralize
rearrange_by_column_tasksand addDataFrame.shuffle(dask#6066) Richard (Rick) ZamoraXfail
test_rolling_numba_enginefor newer numba and older pandas (dask#6236) James BourbeauGeneralize
fix_overlap(dask#6240) GALI PREM SAGARAvoid shuffle when setting a presorted index with overlapping divisions (dask#6226) Krishan Bhasin
Adjust the Parquet engine classes to allow more easily subclassing (dask#6211) Marius van Niekerk
Fix
dd.merge_asofwithleft_on='col'&right_index=True(dask#6192) noreentryMove
AUTO_BLOCKSIZEout ofread_csvsignature (dask#6214) Jim Crist-Harif.locindexing with callable (dask#6185) Endre Mark BorzaAvoid apply in
_compute_sum_of_squaresfor groupby std agg (dask#6186) Richard (Rick) ZamoraMinor correction to
test_parquet(dask#6190) Brian LarsenAdhering to the passed pat for delimeter join and fix error message (dask#6194) GALI PREM SAGAR
Skip
test_to_parquet_with_getif no parquet libs available (dask#6188) Scott Sanderson
Documentation#
Added documentation for
distributed.Eventclass (dask#6231) Nils Braun
2.16.0 / 2020-05-08#
Array#
Fix array general-reduction name (dask#6176) Nick Evans
Replace
dimwithshapeinunravel_index(dask#6155) Julia SignellMoment: handle all elements being masked (dask#5339) Gabe Joseph
Core#
Remove Redundant string concatenations in dask code-base (dask#6137) GALI PREM SAGAR
Upstream compat (dask#6159) Tom Augspurger
Ensure
sizeofof dict and sequences returns an integer (dask#6179) James BourbeauEstimate python collection sizes with random sampling (dask#6154) Florian Jetter
Update test upstream (dask#6146) Tom Augspurger
Skip test for mindeps build (dask#6144) Tom Augspurger
Switch default multiprocessing context to “spawn” (dask#4003) Itamar Turner-Trauring
Update manifest to include dask-schema (dask#6140) Benjamin Zaitlen
DataFrame#
Harden inconsistent-schema handling in pyarrow-based
read_parquet(dask#6160) Richard (Rick) ZamoraAdd compute
kwargsto methods that write data to disk (dask#6056) Krishan BhasinFix issue where
uniquereturns an index like result from backends (dask#6153) GALI PREM SAGARFix internal error in
map_partitionswith collections (dask#6103) Tom Augspurger
Documentation#
Add phase of computation to index TOC (dask#6157) Benjamin Zaitlen
Remove unused imports in scheduling script (dask#6138) James Lamb
Fix indent (dask#6147) Martin Durant
Add Tom’s log config example (dask#6143) Martin Durant
2.15.0 / 2020-04-24#
Array#
Update
dask.array.from_arrayto warn when passed a Dask collection (dask#6122) James BourbeauUn-numpy like behaviour in
dask.array.pad(dask#6042) Mark BoerAdd support for
repeats=0inda.repeat(dask#6080) James Bourbeau
Core#
Fix yaml layout for schema (dask#6132) Benjamin Zaitlen
Configuration Reference (dask#6069) Benjamin Zaitlen
Add configuration option to turn off task fusion (dask#6087) Matthew Rocklin
Skip pyarrow on windows (dask#6094) Tom Augspurger
Set limit to maximum length of fused key (dask#6057) Lucas Rademaker
Add test against #6062 (dask#6072) Martin Durant
Bump checkout action to v2 (dask#6065) James Bourbeau
DataFrame#
Generalize categorical calls to support cudf
Categorical(dask#6113) GALI PREM SAGARAvoid reading
_metadataon every worker (dask#6017) Richard (Rick) ZamoraUse
group_split_dispatchandignore_indexinapply_concat_apply(dask#6119) Richard (Rick) ZamoraHandle new (dtype) pandas metadata with pyarrow (dask#6090) Richard (Rick) Zamora
Skip
test_partition_on_cats_pyarrowif pyarrow is not installed (dask#6112) James BourbeauUpdate DataFrame len to handle columns with the same name (dask#6111) James Bourbeau
ArrowEnginebug fixes and test coverage (dask#6047) Richard (Rick) ZamoraAdded mode (dask#5958) Adam Lewis
Documentation#
Update “helm install” for helm 3 usage (dask#6130) JulianWgs
Extend preload documentation (dask#6077) Matthew Rocklin
Fixed small typo in DataFrame
map_partitions()docstring (dask#6115) Eugene HuangFix typo: “double” should be times, not plus (dask#6091) David Chudzicki
Fix first line of
array.random.*docs (dask#6063) Martin DurantAdd section about
Semaphorein distributed (dask#6053) Florian Jetter
2.14.0 / 2020-04-03#
Array#
Added
np.iscomplexobjimplementation (dask#6045) Tom Augspurger
Core#
Update
test_rearrange_disk_cleanup_with_exceptionto pass without cloudpickle installed (dask#6052) James BourbeauFixed flaky
test-rearrange(dask#5977) Tom Augspurger
DataFrame#
Use
_meta_nonemptyfor dtype casting instack_partitions(dask#6061) mlondschienFix bugs in
_metadatacreation and filtering in parquetArrowEngine(dask#6023) Richard (Rick) Zamora
Documentation#
DOC: Add name caveats (dask#6040) Tom Augspurger
2.13.0 / 2020-03-25#
Array#
Support
dtypeand other keyword arguments inda.random(dask#6030) Matthew RocklinRegister support for
cupysparsehstack/vstack(dask#5735) Corey J. NoletForce
self.nametostrindask.array(dask#6002) Chuanzhu Xu
Bag#
Set
rename_fused_keystoNoneby default inbag.optimize(dask#6000) Lucas Rademaker
Core#
Copy dict in
to_graphvizto prevent overwriting (dask#5996) JulianWgsStricter pandas
xfail(dask#6024) Tom AugspurgerFix CI failures (dask#6013) James Bourbeau
Update
toolzto 0.8.2 and usetlz(dask#5997) Ryan GroutMove Windows CI builds to GitHub Actions (dask#5862) James Bourbeau
DataFrame#
Improve path-related exceptions in
read_hdf(dask#6032) psimajFix
dtypehandling indd.concat(dask#6006) mlondschienHandle cudf’s leftsemi and leftanti joins (dask#6025) Richard J Zamora
Remove unused
npartitionsvariable indd.from_pandas(dask#6019) Daniel Saxton
Documentation#
Fix indentation in scheduler-overview docs (dask#6022) Matthew Rocklin
Update task graphs in optimize docs (dask#5928) Julia Signell
Optionally get rid of intermediary boxes in visualize, and add more labels (dask#5976) Julia Signell
2.12.0 / 2020-03-06#
Array#
Improve reuse of temporaries with numpy (dask#5933) Bruce Merry
Make
map_blockswithblock_infoproduce aBlockwise(dask#5896) Bruce MerryOptimize
make_blockwise_graph(dask#5940) Bruce MerryFix axes ordering in
da.tensordot(dask#5975) Gil ForsythAdds empty mode to
array.pad(dask#5931) Thomas J. Fan
Core#
Remove
toolz.memoizedependency indask.utils(dask#5978) Ryan GroutClose pool leaking subprocess (dask#5979) Tom Augspurger
Pin
numpydocto0.8.0(fix double autoescape) (dask#5961) Gil ForsythRegister deterministic tokenization for
rangeobjects (dask#5947) James BourbeauUnpin
msgpackin CI (dask#5930) JAmes BourbeauEnsure dot results are placed in unique files. (dask#5937) Elliott Sales de Andrade
Add remaining optional dependencies to Travis 3.8 CI build environment (dask#5920) James Bourbeau
DataFrame#
Skip parquet
getitemoptimization for some keys (dask#5917) Tom AugspurgerAdd
ignore_indexargument torearrange_by_columncode path (dask#5973) Richard J ZamoraAdd DataFrame and Series
memory_usage_per_partitionmethods (dask#5971) James Bourbeauxfailtest_describe when using Pandas 0.24.2 (dask#5948) James BourbeauImplement
dask.dataframe.to_numeric(dask#5929) Julia SignellAdd new error message content when columns are in a different order (dask#5927) Julia Signell
Use shallow copy for assign operations when possible (dask#5740) Richard J Zamora
Documentation#
Changed above to below in
dask.array.triudocs (dask#5984) Henrik AnderssonArray slicing: fix typo in
slice_with_int_dask_arrayerror message (dask#5981) Gabe JosephGrammar and formatting updates to docstrings (dask#5963) James Lamb
Update title of DataFrame extension docs (dask#5954) James Bourbeau
Fixed typos in documentation (dask#5962) James Lamb
Add original class or module as a
kwargon_bind_*methods (dask#5946) Julia SignellUpdate optimization doc for python 3 (dask#5926) Julia Signell
2.11.0 / 2020-02-19#
Array#
Cache result of
Array.shape(dask#5916) Bruce MerryImprove accuracy of
estimate_graph_sizeforrechunk(dask#5907) Bruce MerrySkip rechunk steps that do not alter chunking (dask#5909) Bruce Merry
Support
dtypeand otherkwargsincoarsen(dask#5903) Matthew RocklinPush chunk override from
map_blocksinto blockwise (dask#5895) Bruce MerryAvoid using
rewrite_blockwisefor a singleton (dask#5890) Bruce MerryOptimize
slices_from_chunks(dask#5891) Bruce MerryAvoid unnecessary
__getitem__inblock()when chunks have correct dimensionality (dask#5884) Thomas Robitaille
Bag#
Add
include_pathoption fordask.bag.read_text(dask#5836) Yifan GuFixes
ValueErrorin delayed execution of bagged NumPy array (dask#5828) Surya Avala
Core#
CI: Pin
msgpack(dask#5923) Tom AugspurgerRename
test_innertotest_outer(dask#5922) Shiva Raisinghaniquoteshould quote dicts too (dask#5905) Bruce MerryRegister a normalizer for literal (dask#5898) Bruce Merry
Improve layer name synthesis for non-HLGs (dask#5888) Bruce Merry
Replace flake8 pre-commit-hook with upstream (dask#5892) Julia Signell
Call pip as a module to avoid warnings (dask#5861) Cyril Shcherbin
Close
ThreadPoolat exit (dask#5852) Tom AugspurgerRemove
dask.dataframeimport in tokenization code (dask#5855) James Bourbeau
DataFrame#
Require
pandas>=0.23(dask#5883) Tom AugspurgerRemove lambda from dataframe aggregation (dask#5901) Matthew Rocklin
Fix exception chaining in
dataframe/__init__.py(dask#5882) Ram RachumAdd support for reductions on empty dataframes (dask#5804) Shiva Raisinghani
Expose
sort=argument for groupby (dask#5801) Richard J ZamoraUse parquet read speed-ups from
fastparquet.api.paths_to_cats. (dask#5821) Igor Gotlibovych
Documentation#
Deprecate
doc_wraps(dask#5912) Tom AugspurgerUpdate array internal design docs for HighLevelGraph era (dask#5889) Bruce Merry
Move over dashboard connection docs (dask#5877) Matthew Rocklin
Move prometheus docs from distributed.dask.org (dask#5876) Matthew Rocklin
Removing duplicated DO block at the end (dask#5878) K.-Michael Aye
map_blockssee also (dask#5874) Tom AugspurgerMore derived from (dask#5871) Julia Signell
Fix typo (dask#5866) Yetunde Dada
Fix typo in
cloud.rst(dask#5860) Andrew ThomasAdd note pointing to code of conduct and diversity statement (dask#5844) Matthew Rocklin
2.10.1 / 2020-01-30#
Fix Pandas 1.0 version comparison (dask#5851) Tom Augspurger
Fix typo in distributed diagnostics documentation (dask#5841) Gerrit Holl
2.10.0 / 2020-01-28#
Support for pandas 1.0’s new
BooleanDtypeandStringDtype(dask#5815) Tom AugspurgerCompatibility with pandas 1.0’s API breaking changes and deprecations (dask#5792) Tom Augspurger
Fixed non-deterministic tokenization of some extension-array backed pandas objects (dask#5813) Tom Augspurger
Fixed handling of dataclass class objects in collections (dask#5812) Matteo De Wint
Fixed resampling with tz-aware dates when one of the endpoints fell in a non-existent time (dask#5807) dfonnegra
Delay initial Zarr dataset creation until the computation occurs (dask#5797) Chris Roat
Use parquet dataset statistics in more cases with the
pyarrowengine (dask#5799) Richard J ZamoraFixed exception in
groupby.std()when some of the keys were large integers (dask#5737) H. Thomson Comer
2.9.2 / 2020-01-16#
Array#
Unify chunks in
broadcast_arrays(dask#5765) Matthew Rocklin
Core#
xfailCSV encoding tests (dask#5791) Tom AugspurgerUpdate order to handle empty dask graph (dask#5789) James Bourbeau
Redo
dask.order.order(dask#5646) Erik Welch
DataFrame#
Add transparent compression for on-disk shuffle with
partd(dask#5786) Christian WespFix
reprfor empty dataframes (dask#5781) Shiva RaisinghaniPandas 1.0.0RC0 compat (dask#5784) Tom Augspurger
Remove buggy assertions (dask#5783) Tom Augspurger
Pandas 1.0 compat (dask#5782) Tom Augspurger
Fix bug in pyarrow-based
read_parqueton partitioned datasets (dask#5777) Richard J ZamoraCompat for pandas 1.0 (dask#5779) Tom Augspurger
Fix groupby/mean error with with categorical index (dask#5776) Richard J Zamora
Support empty partitions when performing cumulative aggregation (dask#5730) Matthew Rocklin
set_indexaccepts single-item unnested list (dask#5760) Wes RoachFixed partitioning in set index for ordered
Categorical(dask#5715) Tom Augspurger
Documentation#
Note additional use case for
normalize_token.register(dask#5766) Thomas A CaswellSmall typos (dask#5771) Maarten Breddels
Fix typo in Task Expectations docs (dask#5767) James Bourbeau
Add docs section on task expectations to graph page (dask#5764) Devin Petersohn
2.9.1 / 2019-12-27#
Array#
Support Array.view with dtype=None (dask#5736) Anderson Banihirwe
Add dask.array.nanmedian (dask#5684) Deepak Cherian
Core#
xfail test_temporary_directory on Python 3.8 (dask#5734) James Bourbeau
Add support for Python 3.8 (dask#5603) James Bourbeau
Use id to dedupe constants in rewrite_blockwise (dask#5696) Jim Crist
DataFrame#
Raise error when converting a dask dataframe scalar to a boolean (dask#5743) James Bourbeau
Ensure dataframe groupby-variance is greater than zero (dask#5728) Matthew Rocklin
Fix DataFrame.__iter__ (dask#5719) Tom Augspurger
Support Parquet filters in disjunctive normal form, like PyArrow (dask#5656) Matteo De Wint
Auto-detect categorical columns in ArrowEngine-based read_parquet (dask#5690) Richard J Zamora
Skip parquet getitem optimization tests if no engine found (dask#5697) James Bourbeau
Fix independent optimization of parquet-getitem (dask#5613) Tom Augspurger
Documentation#
Link to examples.dask.org in several places (dask#5733) Tom Augspurger
Add missing “ in performance report example (dask#5724) James Bourbeau
Resolve several documentation build warnings (dask#5685) James Bourbeau
add info on performance_report (dask#5713) Benjamin Zaitlen
Add more docs disclaimers (dask#5710) Julia Signell
Update numpydoc dependency (dask#5694) James Bourbeau
2.9.0 / 2019-12-06#
Array#
Fix
da.stdto work with NumPy arrays (dask#5681) James Bourbeau
Core#
Register
sizeoffunctions for Numba and RMM (dask#5668) John A KirkhamUpdate meeting time (dask#5682) Tom Augspurger
DataFrame#
Modify
dd.DataFrame.dropto use shallow copy (dask#5675) Richard J ZamoraFix bug in
_get_md_row_groups(dask#5673) Richard J ZamoraClose sqlalchemy engine after querying DB (dask#5629) Krishan Bhasin
Allow
dd.map_partitionsto not enforce meta (dask#5660) Matthew RocklinGeneralize
concat_unindexed_dataframesto support cudf-backend (dask#5659) Richard J ZamoraAdd dataframe resample methods (dask#5636) Benjamin Zaitlen
Compute length of dataframe as length of first column (dask#5635) Matthew Rocklin
Documentation#
Doc fixup (dask#5665) James Bourbeau
Update doc build instructions (dask#5640) James Bourbeau
Add documentation build (dask#5617) James Bourbeau
2.8.1 / 2019-11-22#
Array#
Use auto rechunking in
da.rechunkif no value given (dask#5605) Matthew Rocklin
Core#
Add simple action to activate GH actions (dask#5619) James Bourbeau
DataFrame#
Fix “file_path_0” bug in
aggregate_row_groups(dask#5627) Richard J ZamoraAdd
chunksizeargument toread_parquet(dask#5607) Richard J ZamoraChange
test_repartition_npartitionsto support arch64 architecture (dask#5620) ossdev07Categories lost after groupby + agg (dask#5423) Oliver Hofkens
Fixed relative path issue with parquet metadata file (dask#5608) Nuno Gomes Silva
Enable gpu-backed covariance/correlation in dataframes (dask#5597) Richard J Zamora
Documentation#
Fix institutional faq and unknown doc warnings (dask#5616) James Bourbeau
Add doc for some utils (dask#5609) Tom Augspurger
Removes
html_extra_path(dask#5614) James BourbeauFixed See Also referencence (dask#5612) Tom Augspurger
2.8.0 / 2019-11-14#
Array#
Implement complete dask.array.tile function (dask#5574) Bouwe Andela
Add median along an axis with automatic rechunking (dask#5575) Matthew Rocklin
Allow da.asarray to chunk inputs (dask#5586) Matthew Rocklin
Bag#
Use key_split in Bag name (dask#5571) Matthew Rocklin
Core#
Switch Doctests to Py3.7 (dask#5573) Ryan Nazareth
Relax get_colors test to adapt to new Bokeh release (dask#5576) Matthew Rocklin
Add dask.blockwise.fuse_roots optimization (dask#5451) Matthew Rocklin
Add sizeof implementation for small dicts (dask#5578) Matthew Rocklin
Update fsspec, gcsfs, s3fs (dask#5588) Tom Augspurger
DataFrame#
Add dropna argument to groupby (dask#5579) Richard J Zamora
Revert “Remove import of dask_cudf, which is now a part of cudf (dask#5568)” (dask#5590) Matthew Rocklin
Documentation#
Add best practice for dask.compute function (dask#5583) Matthew Rocklin
Create FUNDING.yml (dask#5587) Gina Helfrich
Add screencast for coordination primitives (dask#5593) Matthew Rocklin
Move funding to .github repo (dask#5589) Tom Augspurger
Update calendar link (dask#5569) Tom Augspurger
2.7.0 / 2019-11-08#
This release drops support for Python 3.5
Array#
Update da.array to always return a dask array (dask#5510) James Bourbeau
Skip transpose on trivial inputs (dask#5523) Ryan Abernathey
Avoid NumPy scalar string representation in tokenize (dask#5527) James Bourbeau
Remove unnecessary tiledb shape constraint (dask#5545) Norman Barker
Removes bytes from sparse array HTML repr (dask#5556) James Bourbeau
Core#
Drop Python 3.5 (dask#5528) James Bourbeau
Update the use of fixtures in distributed tests (dask#5497) Matthew Rocklin
Changed deprecated bokeh-port to dashboard-address (dask#5507) darindf
Avoid updating with identical dicts in ensure_dict (dask#5501) James Bourbeau
Test Upstream (dask#5516) Tom Augspurger
Accelerate reverse_dict (dask#5479) Ryan Grout
Update test_imports.sh (dask#5534) James Bourbeau
Support cgroups limits on cpu count in multiprocess and threaded schedulers (dask#5499) Albert DeFusco
Update minimum pyarrow version on CI (dask#5562) James Bourbeau
Make cloudpickle optional (dask#5511) crusaderky
DataFrame#
Add an example of index_col usage (dask#3072) Bruno Bonfils
Explicitly use iloc for row indexing (dask#5500) Krishan Bhasin
Accept dask arrays on columns assignemnt (dask#5224) Henrique Ribeiro-
Implement unique and value_counts for SeriesGroupBy (dask#5358) Scott Sievert
Add sizeof definition for pyarrow tables and columns (dask#5522) Richard J Zamora
Enable row-group task partitioning in pyarrow-based read_parquet (dask#5508) Richard J Zamora
Removes npartitions=’auto’ from dd.merge docstring (dask#5531) James Bourbeau
Apply enforce error message shows non-overlapping columns. (dask#5530) Tom Augspurger
Optimize meta_nonempty for repetitive dtypes (dask#5553) Petio Petrov
Remove import of dask_cudf, which is now a part of cudf (dask#5568) Mads R. B. Kristensen
Documentation#
Make capitalization more consistent in FAQ docs (dask#5512) Matthew Rocklin
Add CONTRIBUTING.md (dask#5513) Jacob Tomlinson
Document optional dependencies (dask#5456) Prithvi MK
Update helm chart docs to reflect new chart repo (dask#5539) Jacob Tomlinson
Add Resampler to API docs (dask#5551) James Bourbeau
Add adaptive deployments screencast [skip ci] (dask#5566) Matthew Rocklin
2.6.0 / 2019-10-15#
Core#
Call
ensure_dicton graphs before enteringtoolz.merge(dask#5486) Matthew RocklinConsolidating hash dispatch functions (dask#5476) Richard J Zamora
DataFrame#
Support Python 3.5 in Parquet code (dask#5491) Benjamin Zaitlen
Avoid identity check in
warn_dtype_mismatch(dask#5489) Tom AugspurgerEnable unused groupby tests (dask#3480) Jörg Dietrich
Remove old parquet and bcolz dataframe optimizations (dask#5484) Matthew Rocklin
Add getitem optimization for
read_parquet(dask#5453) Tom AugspurgerUse
_constructor_slicedmethod to determine Series type (dask#5480) Richard J ZamoraFix map(series) for unsorted base series index (dask#5459) Justin Waugh
Fix
KeyErrorwith Groupby label (dask#5467) Ryan Nazareth
Documentation#
Use Zoom meeting instead of appear.in (dask#5494) Matthew Rocklin
Update SSH docs to include
SSHCluster(dask#5482) Matthew RocklinUpdate “Why Dask?” page (dask#5473) Matthew Rocklin
2.5.2 / 2019-10-04#
Array#
Correct chunk size logic for asymmetric overlaps (dask#5449) Ben Jeffery
Make da.unify_chunks public API (dask#5443) Matthew Rocklin
DataFrame#
Fix dask.dataframe.fillna handling of Scalar object (dask#5463) Zhenqing Li
Documentation#
Remove boxes in Spark comparison page (dask#5445) Matthew Rocklin
Update cloud documentation (dask#5444) Matthew Rocklin
2.5.0 / 2019-09-27#
Core#
Add sentinel no_default to get_dependencies task (dask#5420) James Bourbeau
Update fsspec version (dask#5415) Matthew Rocklin
DataFrame#
Add option to not check meta in dd.from_delayed (dask#5436) Christopher J. Wright
Fix test_timeseries_nulls_in_schema failures with pyarrow master (dask#5421) Richard J Zamora
Reduce read_metadata output size in pyarrow/parquet (dask#5391) Richard J Zamora
Test numeric edge case for repartition with npartitions. (dask#5433) amerkel2
Unxfail pandas-datareader test (dask#5430) Tom Augspurger
Add DataFrame.pop implementation (dask#5422) Matthew Rocklin
Enable merge/set_index for cudf-based dataframes with cupy
values(dask#5322) Richard J Zamoradrop_duplicates support for positional subset parameter (dask#5410) Wes Roach
Documentation#
Add screencasts to array, bag, dataframe, delayed, futures and setup (dask#5429) (dask#5424) Matthew Rocklin
Fix delimeter parsing documentation (dask#5428) Mahmut Bulut
Update overview image (dask#5404) James Bourbeau
2.4.0 / 2019-09-13#
Array#
Adds explicit
h5py.Filemode (dask#5390) James BourbeauProvides method to compute unknown array chunks sizes (dask#5312) Scott Sievert
Ignore runtime warning in Array
compute_meta(dask#5356) estebanagAdd
_metatoArray.__dask_postpersist__(dask#5353) Benoit BovyFixup
da.asarrayandda.asanyarrayfor datetime64 dtype and xarray objects (dask#5334) Stephan HoyerAdd shape implementation (dask#5293) Tom Augspurger
Add chunktype to array text repr (dask#5289) James Bourbeau
Array.random.choice: handle array-like non-arrays (dask#5283) Gabe Joseph
Core#
Fix
funcnamewhen vectorized func has no__name__(dask#5399) James BourbeauTruncate
funcnameto avoid long key names (dask#5383) Matthew RocklinAdd support for
numpy.vectorizeinfuncname(dask#5396) James BourbeauFixed HDFS upstream test (dask#5395) Tom Augspurger
Support numbers and None in
parse_bytes/timedelta(dask#5384) Matthew RocklinFix tokenizing of subindexes on memmapped numpy arrays (dask#5351) Henry Pinkard
Upstream fixups (dask#5300) Tom Augspurger
DataFrame#
Allow pandas to cast type of statistics (dask#5402) Richard J Zamora
Preserve index dtype after applying
dd.pivot_table(dask#5385) therhaagImplement explode for Series and DataFrame (dask#5381) Arpit Solanki
set_indexon categorical fails with less categories than partitions (dask#5354) Oliver HofkensSupport output to a single CSV file (dask#5304) Hongjiu Zhang
Add
groupby().transform()(dask#5327) Oliver HofkensAdding filter kwarg to pyarrow dataset call (dask#5348) Richard J Zamora
Implement and check compression defaults for parquet (dask#5335) Sarah Bird
Pass sqlalchemy params to delayed objects (dask#5332) Arpit Solanki
Fixing schema handling in arrow-parquet (dask#5307) Richard J Zamora
Add support for DF and Series
groupby().idxmin/max()(dask#5273) Oliver HofkensAdd correlation calculation and add test (dask#5296) Benjamin Zaitlen
Documentation#
Minor edits to Array chunk documentation (dask#5372) Scott Sievert
Add methods to API docs (dask#5387) Tom Augspurger
Add namespacing to configuration example (dask#5374) Matthew Rocklin
Add get_task_stream and profile to the diagnostics page (dask#5375) Matthew Rocklin
Add best practice to load data with Dask (dask#5369) Matthew Rocklin
Add threads and processes note to the best practices (dask#5340) Matthew Rocklin
Update cuDF links (dask#5328) James Bourbeau
Fixed small typo with parentheses placement (dask#5311) Eugene Huang
Update link in reshape docstring (dask#5297) James Bourbeau
2.3.0 / 2019-08-16#
Array#
Raise exception when
from_arrayis given a dask array (dask#5280) David HoeseAvoid adjusting gufunc’s meta dtype twice (dask#5274) Peter Andreas Entschev
Add
meta=keyword to map_blocks and add test with sparse (dask#5269) Matthew RocklinAdd rollaxis and moveaxis (dask#4822) Tobias de Jong
Always increment old chunk index (dask#5256) James Bourbeau
Shuffle dask array (dask#3901) Tom Augspurger
Fix ordering when indexing a dask array with a bool dask array (dask#5151) James Bourbeau
Bag#
Add workaround for memory leaks in bag generators (dask#5208) Marco Neumann
Core#
Set strict xfail option (dask#5220) James Bourbeau
test-upstream (dask#5267) Tom Augspurger
Fixed HDFS CI failure (dask#5234) Tom Augspurger
Ensure parquet tests are skipped if fastparquet and pyarrow not installed (dask#5217) James Bourbeau
Add fsspec to readthedocs (dask#5207) Matthew Rocklin
Bump NumPy and Pandas to 1.17 and 0.25 in CI test (dask#5179) John A Kirkham
DataFrame#
Fix
DataFrame.querydocstring (incorrect numexpr API) (dask#5271) Doug DavisParquet metadata-handling improvements (dask#5218) Richard J Zamora
Improve messaging around sorted parquet columns for index (dask#5265) Martin Durant
Add
rearrange_by_divisionsandset_indexsupport for cudf (dask#5205) Richard J ZamoraFix
groupby.std()with integer colum names (dask#5096) Nicolas HugGeneralize
hash_pandas_objectto work for non-pandas backends (dask#5184) GALI PREM SAGARAdd rolling cov (dask#5154) Ivars Geidans
Add columns argument in drop function (dask#5223) Henrique Ribeiro
Documentation#
Update institutional FAQ doc (dask#5277) Matthew Rocklin
Add draft of institutional FAQ (dask#5214) Matthew Rocklin
Make boxes for dask-spark page (dask#5249) Martin Durant
Add motivation for shuffle docs (dask#5213) Matthew Rocklin
Fix links and API entries for best-practices (dask#5246) Martin Durant
Remove “bytes” (internal data ingestion) doc page (dask#5242) Martin Durant
Redirect from our local distributed page to distributed.dask.org (dask#5248) Matthew Rocklin
Cleanup API page (dask#5247) Matthew Rocklin
Remove excess endlines from install docs (dask#5243) Matthew Rocklin
Remove item list in phases of computation doc (dask#5245) Martin Durant
Remove custom graphs from the TOC sidebar (dask#5241) Matthew Rocklin
Remove experimental status of custom collections (dask#5236) James Bourbeau
Adds table of contents to Why Dask? (dask#5244) James Bourbeau
Moves bag overview to top-level bag page (dask#5240) James Bourbeau
Remove use-cases in favor of stories.dask.org (dask#5238) Matthew Rocklin
Removes redundant TOC information in index.rst (dask#5235) James Bourbeau
Elevate dashboard in distributed diagnostics documentation (dask#5239) Martin Durant
Updates “add” layer in HLG docs example (dask#5237) James Bourbeau
Update GUFunc documentation (dask#5232) Matthew Rocklin
2.2.0 / 2019-08-01#
Array#
Use da.from_array(…, asarray=False) if input follows NEP-18 (dask#5074) Matthew Rocklin
Add missing attributes to from_array documentation (dask#5108) Peter Andreas Entschev
Fix meta computation for some reduction functions (dask#5035) Peter Andreas Entschev
Raise informative error in to_zarr if unknown chunks (dask#5148) James Bourbeau
Remove invalid pad tests (dask#5122) Tom Augspurger
Ignore NumPy warnings in compute_meta (dask#5103) Peter Andreas Entschev
Fix kurtosis calc for single dimension input array (dask#5177) @andrethrill
Support Numpy 1.17 in tests (dask#5192) Matthew Rocklin
Bag#
Supply pool to bag test to resolve intermittent failure (dask#5172) Tom Augspurger
Core#
Base dask on fsspec (dask#5064) (dask#5121) Martin Durant
Various upstream compatibility fixes (dask#5056) Tom Augspurger
Make distributed tests optional again. (dask#5128) Elliott Sales de Andrade
Fix HDFS in dask (dask#5130) Martin Durant
Ignore some more invalid value warnings. (dask#5140) Elliott Sales de Andrade
DataFrame#
Fix pd.MultiIndex size estimate (dask#5066) Brett Naul
Generalizing has_known_categories (dask#5090) GALI PREM SAGAR
Refactor Parquet engine (dask#4995) Richard J Zamora
Add divide method to series and dataframe (dask#5094) msbrown47
fix flaky partd test (dask#5111) Tom Augspurger
Adjust is_dataframe_like to adjust for value_counts change (dask#5143) Tom Augspurger
Generalize rolling windows to support non-Pandas dataframes (dask#5149) Nick Becker
Avoid unnecessary aggregation in pivot_table (dask#5173) Daniel Saxton
Add column names to apply_and_enforce error message (dask#5180) Matthew Rocklin
Add schema keyword argument to to_parquet (dask#5150) Sarah Bird
Allow fastparquet to handle gather_statistics=False for file lists (dask#5157) Richard J Zamora
Documentation#
Adds NumFOCUS badge to the README (dask#5086) James Bourbeau
Document DataFrame.set_index computataion behavior Natalya Rapstine
Use pip install . instead of calling setup.py (dask#5139) Matthias Bussonier
Close user survey (dask#5147) Tom Augspurger
Fix Google Calendar meeting link (dask#5155) Loïc Estève
Add docker image customization example (dask#5171) James Bourbeau
Update remote-data-services after fsspec (dask#5170) Martin Durant
Fix typo in spark.rst (dask#5164) Xavier Holt
Update setup/python docs for async/await API (dask#5163) Matthew Rocklin
Update Local Storage HPC documentation (dask#5165) Matthew Rocklin
2.1.0 / 2019-07-08#
Array#
Add
recompute=keyword tosvd_compressedfor lower-memory use (dask#5041) Matthew RocklinChange
__array_function__implementation for backwards compatibility (dask#5043) Ralf GommersAdded
dtypeandshapekwargs toapply_along_axis(dask#3742) Davis BennettFix reduction with empty tuple axis (dask#5025) Peter Andreas Entschev
Drop size 0 arrays in
stack(dask#4978) John A Kirkham
Core#
Removes index keyword from pandas
to_parquetcall (dask#5075) James BourbeauFixes upstream dev CI build installation (dask#5072) James Bourbeau
Ensure scalar arrays are not rendered to SVG (dask#5058) Willi Rath
Environment creation overhaul (dask#5038) Tom Augspurger
s3fs, moto compatibility (dask#5033) Tom Augspurger
pytest 5.0 compat (dask#5027) Tom Augspurger
DataFrame#
Fix
compute_metarecursion in blockwise (dask#5048) Peter Andreas EntschevRemove hard dependency on pandas in
get_dummies(dask#5057) GALI PREM SAGARCheck dtypes unchanged when using
DataFrame.assign(dask#5047) asmith26Fix cumulative functions on tables with more than 1 partition (dask#5034) tshatrov
Handle non-divisible sizes in repartition (dask#5013) George Sakkis
Handles timestamp and
preserve_indexchanges in pyarrow (dask#5018) Richard J ZamoraFix undefined
metaforstr.split(expand=False)(dask#5022) Brett NaulRemoved checks used for debugging
merge_asof(dask#5011) Cody JohnsonDon’t use type when getting accessor in dataframes (dask#4992) Matthew Rocklin
Add
meltas a method of Dask DataFrame (dask#4984) Dustin TindallAdds path-like support to
to_hdf(dask#5003) James Bourbeau
Documentation#
Point to latest K8s setup article in JupyterHub docs (dask#5065) Sean McKenna
Changes vizualize to visualize (dask#5061) David Brochart
Fix
from_sequencetypo in delayed best practices (dask#5045) James BourbeauAdd user survey link to docs (dask#5026) James Bourbeau
Fixes typo in optimization docs (dask#5015) James Bourbeau
Update community meeting information (dask#5006) Tom Augspurger
2.0.0 / 2019-06-25#
Array#
Support automatic chunking in da.indices (dask#4981) James Bourbeau
Err if there are no arrays to stack (dask#4975) John A Kirkham
Asymmetrical Array Overlap (dask#4863) Michael Eaton
Dispatch concatenate where possible within dask array (dask#4669) Hameer Abbasi
Fix tokenization of memmapped numpy arrays on different part of same file (dask#4931) Henry Pinkard
Preserve NumPy condition in da.asarray to preserve output shape (dask#4945) Alistair Miles
Expand foo_like_safe usage (dask#4946) Peter Andreas Entschev
Defer order/casting einsum parameters to NumPy implementation (dask#4914) Peter Andreas Entschev
Remove numpy warning in moment calculation (dask#4921) Matthew Rocklin
Fix meta_from_array to support Xarray test suite (dask#4938) Matthew Rocklin
Cache chunk boundaries for integer slicing (dask#4923) Bruce Merry
Drop size 0 arrays in concatenate (dask#4167) John A Kirkham
Raise ValueError if concatenate is given no arrays (dask#4927) John A Kirkham
Promote types in concatenate using _meta (dask#4925) John A Kirkham
Add chunk type to html repr in Dask array (dask#4895) Matthew Rocklin
- Add Dask Array._meta attribute (dask#4543) Peter Andreas Entschev
Fix _meta slicing of flexible types (dask#4912) Peter Andreas Entschev
Minor meta construction cleanup in concatenate (dask#4937) Peter Andreas Entschev
Further relax Array meta checks for Xarray (dask#4944) Matthew Rocklin
Support meta= keyword in da.from_delayed (dask#4972) Matthew Rocklin
Concatenate meta along axis (dask#4977) John A Kirkham
Use meta in stack (dask#4976) John A Kirkham
Move blockwise_meta to more general compute_meta function (dask#4954) Matthew Rocklin
Alias .partitions to .blocks attribute of dask arrays (dask#4853) Genevieve Buckley
Drop outdated numpy_compat functions (dask#4850) John A Kirkham
Allow da.eye to support arbitrary chunking sizes with chunks=’auto’ (dask#4834) Anderson Banihirwe
Fix CI warnings in dask.array tests (dask#4805) Tom Augspurger
Make map_blocks work with drop_axis + block_info (dask#4831) Bruce Merry
Add SVG image and table in Array._repr_html_ (dask#4794) Matthew Rocklin
ufunc: avoid __array_wrap__ in favor of __array_function__ (dask#4708) Peter Andreas Entschev
Ensure trivial padding returns the original array (dask#4990) John A Kirkham
Test
da.blockwith 0-size arrays (dask#4991) John A Kirkham
Core#
Quiet dependency installs in CI (dask#4960) Tom Augspurger
Raise on warnings in tests (dask#4916) Tom Augspurger
Add a diagnostics extra to setup.py (includes bokeh) (dask#4924) John A Kirkham
Overload HighLevelGraphs values method (dask#4918) James Bourbeau
Add __await__ method to Dask collections (dask#4901) Matthew Rocklin
Also ignore AttributeErrors which may occur if snappy (not python-snappy) is installed (dask#4908) Mark Bell
Canonicalize key names in config.rename (dask#4903) Ian Bolliger
Bump minimum partd to 0.3.10 (dask#4890) Tom Augspurger
Catch async def SyntaxError (dask#4836) James Bourbeau
catch IOError in ensure_file (dask#4806) Justin Poehnelt
Cleanup CI warnings (dask#4798) Tom Augspurger
Move distributed’s parse and format functions to dask.utils (dask#4793) Matthew Rocklin
Apply black formatting (dask#4983) James Bourbeau
Package license file in wheels (dask#4988) John A Kirkham
DataFrame#
Add an optional partition_size parameter to repartition (dask#4416) George Sakkis
merge_asof and prefix_reduction (dask#4877) Cody Johnson
Allow dataframes to be indexed by dask arrays (dask#4882) Endre Mark Borza
Avoid deprecated message parameter in pytest.raises (dask#4962) James Bourbeau
Update test_to_records to test with lengths argument(dask#4515) asmith26
Remove pandas pinning in Dataframe accessors (dask#4955) Matthew Rocklin
Fix correlation of series with same names (dask#4934) Philipp S. Sommer
Map Dask Series to Dask Series (dask#4872) Justin Waugh
Add groupby Covariance/Correlation (dask#4889) Benjamin Zaitlen
keep index name with to_datetime (dask#4905) Ian Bolliger
Add Parallel variance computation for dataframes (dask#4865) Ksenia Bobrova
Add divmod implementation to arrays and dataframes (dask#4884) Henrique Ribeiro
Add documentation for dataframe reshape methods (dask#4896) tpanza
Avoid use of pandas.compat (dask#4881) Tom Augspurger
Added accessor registration for Series, DataFrame, and Index (dask#4829) Tom Augspurger
Add read_function keyword to read_json (dask#4810) Richard J Zamora
Provide full type name in check_meta (dask#4819) Matthew Rocklin
Correctly estimate bytes per row in read_sql_table (dask#4807) Lijo Jose
Adding support of non-numeric data to describe() (dask#4791) Ksenia Bobrova
Scalars for extension dtypes. (dask#4459) Tom Augspurger
Call head before compute in dd.from_delayed (dask#4802) Matthew Rocklin
Add support for rolling operations with larger window that partition size in DataFrames with Time-based index (dask#4796) Jorge Pessoa
Update groupby-apply doc with warning (dask#4800) Tom Augspurger
Change groupby-ness tests in _maybe_slice (dask#4786) Benjamin Zaitlen
Add master best practices document (dask#4745) Matthew Rocklin
Add document for how Dask works with GPUs (dask#4792) Matthew Rocklin
Add cli API docs (dask#4788) James Bourbeau
Ensure concat output has coherent dtypes (dask#4692) Guillaume Lemaitre
Fixes pandas_datareader dependencies installation (dask#4989) James Bourbeau
Accept pathlib.Path as pattern in read_hdf (dask#3335) Jörg Dietrich
Documentation#
Move CLI API docs to relavant pages (dask#4980) James Bourbeau
Add to_datetime function to dataframe API docs Matthew Rocklin
Add documentation entry for dask.array.ma.average (dask#4970) Bouwe Andela
Add bag.read_avro to bag API docs (dask#4969) James Bourbeau
Remove requirement to modify changelog (dask#4915) Matthew Rocklin
Add documentation about meta column order (dask#4887) Tom Augspurger
Add documentation note in DataFrame.shift (dask#4886) Tom Augspurger
Docs: Fix typo (dask#4868) Paweł Kordek
Put do/don’t into boxes for delayed best practice docs (dask#3821) Martin Durant
Doc fixups (dask#2528) Tom Augspurger
Add quansight to paid support doc section (dask#4838) Martin Durant
Add document for custom startup (dask#4833) Matthew Rocklin
Allow utils.derive_from to accept functions, apply across array (dask#4804) Martin Durant
Add “Avoid Large Partitions” section to best practices (dask#4808) Matthew Rocklin
Update URL for joblib to new website hosting their doc (dask#4816) Christian Hudon
1.2.2 / 2019-05-08#
Array#
Clarify regions kwarg to array.store (dask#4759) Martin Durant
Add dtype= parameter to da.random.randint (dask#4753) Matthew Rocklin
Use “row major” rather than “C order” in docstring (dask#4452) @asmith26
Normalize Xarray datasets to Dask arrays (dask#4756) Matthew Rocklin
Remove normed keyword in da.histogram (dask#4755) Matthew Rocklin
Bag#
Add key argument to Bag.distinct (dask#4423) Daniel Severo
Core#
Add core dask config file (dask#4774) Matthew Rocklin
Add core dask config file to MANIFEST.in (dask#4780) James Bourbeau
Enabling glob with HTTP file-system (dask#3926) Martin Durant
HTTPFile.seek with whence=1 (dask#4751) Martin Durant
DataFrame#
Remove explicit references to Pandas in dask.dataframe.groupby (dask#4778) Matthew Rocklin
Add support for group_keys kwarg in DataFrame.groupby() (dask#4771) Brian Chu
Describe doc (dask#4762) Martin Durant
Remove explicit pandas check in cumulative aggregations (dask#4765) Nick Becker
Added meta for read_json and test (dask#4588) Abhinav Ralhan
Add test for dtype casting (dask#4760) Martin Durant
Implement Series.str.split(expand=True) (dask#4744) Matthew Rocklin
Documentation#
Tweaks to develop.rst from trying to run tests (dask#4772) Christian Hudon
Add document describing phases of computation (dask#4766) Matthew Rocklin
Point users to Dask-Yarn from spark documentation (dask#4770) Matthew Rocklin
Update images in delayed doc to remove labels (dask#4768) Martin Durant
Explain intermediate storage for dask arrays (dask#4025) John A Kirkham
Specify bash code-block in array best practices (dask#4764) James Bourbeau
Add array best practices doc (dask#4705) Matthew Rocklin
Update optimization docs now that cull is not automatic (dask#4752) Matthew Rocklin
1.2.1 / 2019-04-29#
Array#
Fix map_blocks with block_info and broadcasting (dask#4737) Bruce Merry
Make ‘minlength’ keyword argument optional in da.bincount (dask#4684) Genevieve Buckley
Add support for map_blocks with no array arguments (dask#4713) Bruce Merry
Add dask.array.trace (dask#4717) Danilo Horta
Add sizeof support for cupy.ndarray (dask#4715) Peter Andreas Entschev
Add name kwarg to from_zarr (dask#4663) Michael Eaton
Add chunks=’auto’ to from_array (dask#4704) Matthew Rocklin
Raise TypeError if dask array is given as shape for da.ones, zeros, empty or full (dask#4707) Genevieve Buckley
Add TileDB backend (dask#4679) Isaiah Norton
Core#
Delay long list arguments (dask#4735) Matthew Rocklin
Bump to numpy >= 1.13, pandas >= 0.21.0 (dask#4720) Jim Crist
Remove file “test” (dask#4710) James Bourbeau
Reenable development build, uses upstream libraries (dask#4696) Peter Andreas Entschev
Remove assertion in HighLevelGraph constructor (dask#4699) Matthew Rocklin
DataFrame#
Change cum-aggregation last-nonnull-value algorithm (dask#4736) Nick Becker
Refactor array.percentile and dataframe.quantile to use t-digest (dask#4677) Janne Vuorela
Allow naive concatenation of sorted dataframes (dask#4725) Matthew Rocklin
Remove hard pandas dependency for melt by using methodcaller (dask#4719) Nick Becker
Add Dataframe.replace (dask#4714) Matthew Rocklin
Add ‘threshold’ parameter to pd.DataFrame.dropna (dask#4625) Nathan Matare
Documentation#
Add warning about derived docstrings early in the docstring (dask#4716) Matthew Rocklin
Create dataframe best practices doc (dask#4703) Matthew Rocklin
Uncomment dask_sphinx_theme (dask#4728) James Bourbeau
Fix minor typo fix in a Queue/fire_and_forget example (dask#4709) Matthew Rocklin
Update from_pandas docstring to match signature (dask#4698) James Bourbeau
1.2.0 / 2019-04-12#
Array#
Fixed mean() and moment() on sparse arrays (dask#4525) Peter Andreas Entschev
Add test for NEP-18. (dask#4675) Hameer Abbasi
Allow None to say “no chunking” in normalize_chunks (dask#4656) Matthew Rocklin
Fix limit value in auto_chunks (dask#4645) Matthew Rocklin
Core#
Updated diagnostic bokeh test for compatibility with bokeh>=1.1.0 (dask#4680) Philipp Rudiger
Adjusts codecov’s target/threshold, disable patch (dask#4671) Peter Andreas Entschev
Always start with empty http buffer, not None (dask#4673) Martin Durant
DataFrame#
Propagate index dtype and name when create dask dataframe from array (dask#4686) Henrique Ribeiro
Clean up and document rearrange_column_by_tasks (dask#4674) Matthew Rocklin
Mark some parquet tests xfail (dask#4667) Peter Andreas Entschev
Fix parquet breakages with arrow 0.13.0 (dask#4668) Martin Durant
Allow sample to be False when reading CSV from a remote URL (dask#4634) Ian Rose
Fix timezone metadata inference on parquet load (dask#4655) Martin Durant
Use is_dataframe/index_like in dd.utils (dask#4657) Matthew Rocklin
Add min_count parameter to groupby sum method (dask#4648) Henrique Ribeiro
Correct quantile to handle unsorted quantiles (dask#4650) gregrf
Documentation#
Add delayed extra dependencies to install docs (dask#4660) James Bourbeau
1.1.5 / 2019-03-29#
Array#
Ensure that we use the dtype keyword in normalize_chunks (dask#4646) Matthew Rocklin
Core#
Use recursive glob in LocalFileSystem (dask#4186) Brett Naul
Avoid YAML deprecation (dask#4603)
Fix CI and add set -e (dask#4605) James Bourbeau
Support builtin sequence types in dask.visualize (dask#4602)
unpack/repack orderedDict (dask#4623) Justin Poehnelt
Add da.random.randint to API docs (dask#4628) James Bourbeau
Add zarr to CI environment (dask#4604) James Bourbeau
Enable codecov (dask#4631) Peter Andreas Entschev
DataFrame#
Support setting the index (dask#4565)
DataFrame.itertuples accepts index, name kwargs (dask#4593) Dan O’Donovan
Support non-Pandas series in dd.Series.unique (dask#4599) Benjamin Zaitlen
Replace use of explicit type check with ._is_partition_type predicate (dask#4533)
Remove additional pandas warnings in tests (dask#4576)
Check object for name/dtype attributes rather than type (dask#4606)
Fixing warning from setting categorical codes to floats (dask#4624) Julia Signell
Fix renaming on index to_frame method (dask#4498) Henrique Ribeiro
Fix divisions when joining two single-partition dataframes (dask#4636) Justin Waugh
Warn if partitions overlap in compute_divisions (dask#4600) Brian Chu
Give informative meta= warning (dask#4637) Matthew Rocklin
Add informative error message to Series.__getitem__ (dask#4638) Matthew Rocklin
Add clear exception message when using index or index_col in read_csv (dask#4651) Álvaro Abella Bascarán
Documentation#
Add documentation for custom groupby aggregations (dask#4571)
Docs dataframe joins (dask#4569)
Specify fork-based contributions (dask#4619) James Bourbeau
correct to_parquet example in docs (dask#4641) Aaron Fowles
Update and secure several references (dask#4649) Søren Fuglede Jørgensen
1.1.4 / 2019-03-08#
Array#
Use mask selection in compress (dask#4548) John A Kirkham
Use asarray in extract (dask#4549) John A Kirkham
Use correct dtype when test concatenation. (dask#4539) Elliott Sales de Andrade
Fix CuPy tests or properly marks as xfail (dask#4564) Peter Andreas Entschev
Core#
Fix local scheduler callback to deal with custom caching (dask#4542) Yu Feng
Use parse_bytes in read_bytes(sample=…) (dask#4554) Matthew Rocklin
DataFrame#
Fix up groupby-standard deviation again on object dtype keys (dask#4541) Matthew Rocklin
TST/CI: Updates for pandas 0.24.1 (dask#4551) Tom Augspurger
Add ability to control number of unique elements in timeseries (dask#4557) Matthew Rocklin
Add support in read_csv for parameter skiprows for other iterables (dask#4560) @JulianWgs
Documentation#
DataFrame to Array conversion and unknown chunks (dask#4516) Scott Sievert
Add docs for random array creation (dask#4566) Matthew Rocklin
Fix typo in docstring (dask#4572) Shyam Saladi
1.1.3 / 2019-03-01#
Array#
Modify mean chunk functions to return dicts rather than arrays (dask#4513) Matthew Rocklin
Change sparse installation in CI for NumPy/Python2 compatibility (dask#4537) Matthew Rocklin
DataFrame#
Make merge dispatchable on pandas/other dataframe types (dask#4522) Matthew Rocklin
read_sql_table - datetime index fix and index type checking (dask#4474) Joe Corbett
Use generalized form of index checking (is_index_like) (dask#4531) Benjamin Zaitlen
Add tests for groupby reductions with object dtypes (dask#4535) Matthew Rocklin
Fixes #4467 : Updates time_series for pandas deprecation (dask#4530) @HSR05
Documentation#
Add missing method to documentation index (dask#4528) Bart Broere
1.1.2 / 2019-02-25#
Array#
Fix another unicode/mixed-type edge case in normalize_array (dask#4489) Marco Neumann
Add dask.array.diagonal (dask#4431) Danilo Horta
Modify moment chunk functions to return dicts (dask#4519) Peter Andreas Entschev
Bag#
Ensure that bag.from_sequence always includes at least one partition (dask#4475) Anderson Banihirwe
Implement out_type for bag.fold (dask#4502) Matthew Rocklin
Remove map from bag keynames (dask#4500) Matthew Rocklin
Avoid itertools.repeat in map_partitions (dask#4507) Matthew Rocklin
DataFrame#
Fix relative path parsing on windows when using fastparquet (dask#4445) Janne Vuorela
Fix bug in pyarrow and hdfs (dask#4453) (dask#4455) Michał Jastrzębski
df getitem with integer slices is not implemented (dask#4466) Jim Crist
Replace cudf-specific code with dask-cudf import (dask#4470) Matthew Rocklin
Avoid groupby.agg(callable) in groupby-var (dask#4482) Matthew Rocklin
Consider uint types as numerical in check_meta (dask#4485) Marco Neumann
Fix some typos in groupby comments (dask#4494) Daniel Saxton
Add error message around set_index(inplace=True) (dask#4501) Matthew Rocklin
meta_nonempty works with categorical index (dask#4505) Jim Crist
Add module name to expected meta error message (dask#4499) Matthew Rocklin
Propagate index metadata if not specified (dask#4509) Jim Crist
Documentation#
Update docs to use
from_zarr(dask#4472) John A KirkhamDOC: add section of Using Other S3-Compatible Services for remote-data-services (dask#4405) Aploium
Fix header level of section in changelog (dask#4483) Bruce Merry
Add quotes to pip install [skip-ci] (dask#4508) James Bourbeau
Core#
Extend started_cbs AFTER state is initialized (dask#4460) Marco Neumann
Fix bug in HTTPFile._fetch_range with headers (dask#4479) (dask#4480) Ross Petchler
Repeat optimize_blockwise for diamond fusion (dask#4492) Matthew Rocklin
1.1.1 / 2019-01-31#
Array#
Add support for cupy.einsum (dask#4402) Johnnie Gray
Provide byte size in chunks keyword (dask#4434) Adam Beberg
Raise more informative error for histogram bins and range (dask#4430) James Bourbeau
DataFrame#
Lazily register more cudf functions and move to backends file (dask#4396) Matthew Rocklin
rearrange_by_column: ensure that shuffle arg defaults to ‘disk’ if it’s None in dask.config (dask#4414) George Sakkis
Implement filters for _read_pyarrow (dask#4415) George Sakkis
Avoid checking against types in is_dataframe_like (dask#4418) Matthew Rocklin
Pass username as ‘user’ when using pyarrow (dask#4438) Roma Sokolov
Delayed#
Fix DelayedAttr return value (dask#4440) Matthew Rocklin
Documentation#
Use SVG for pipeline graphic (dask#4406) John A Kirkham
Add doctest-modules to py.test documentation (dask#4427) Daniel Severo
Core#
Work around psutil 5.5.0 not allowing pickling Process objects Janne Vuorela
1.1.0 / 2019-01-18#
Array#
Fix the average function when there is a masked array (dask#4236) Damien Garaud
Add allow_unknown_chunksizes to hstack and vstack (dask#4287) Paul Vecchio
Fix tensordot for 27+ dimensions (dask#4304) Johnnie Gray
Fixed block_info with axes. (dask#4301) Tom Augspurger
Use safe_wraps for matmul (dask#4346) Mark Harfouche
Use chunks=”auto” in array creation routines (dask#4354) Matthew Rocklin
Fix np.matmul in dask.array.Array.__array_ufunc__ (dask#4363) Stephan Hoyer
COMPAT: Re-enable multifield copy->view change (dask#4357) Diane Trout
Calling np.dtype on a delayed object works (dask#4387) Jim Crist
Rework normalize_array for numpy data (dask#4312) Marco Neumann
DataFrame#
Add fill_value support for series comparisons (dask#4250) James Bourbeau
Add schema name in read_sql_table for empty tables (dask#4268) Mina Farid
Adjust check for bad chunks in map_blocks (dask#4308) Tom Augspurger
Use atop fusion in dask dataframe (dask#4229) Matthew Rocklin
Use parallel_types() in from_pandas (dask#4331) Matthew Rocklin
Change DataFrame._repr_data to method (dask#4330) Matthew Rocklin
Install pyarrow fastparquet for Appveyor (dask#4338) Gábor Lipták
Remove explicit pandas checks and provide cudf lazy registration (dask#4359) Matthew Rocklin
Replace isinstance(…, pandas) with is_dataframe_like (dask#4375) Matthew Rocklin
ENH: Support 3rd-party ExtensionArrays (dask#4379) Tom Augspurger
Pandas 0.24.0 compat (dask#4374) Tom Augspurger
Documentation#
Fix link to ‘map_blocks’ function in array api docs (dask#4258) David Hoese
Add a paragraph on Dask-Yarn in the cloud docs (dask#4260) Jim Crist
Copy edit documentation (dask#4267), (dask#4263), (dask#4262), (dask#4277), (dask#4271), (dask#4279), (dask#4265), (dask#4295), (dask#4293), (dask#4296), (dask#4302), (dask#4306), (dask#4318), (dask#4314), (dask#4309), (dask#4317), (dask#4326), (dask#4325), (dask#4322), (dask#4332), (dask#4333), Miguel Farrajota
Doc: Update array-api.rst (dask#4259) (dask#4282) Prabakaran Kumaresshan
Update hpc doc (dask#4266) Guillaume Eynard-Bontemps
Doc: Replace from_avro with read_avro in documents (dask#4313) Prabakaran Kumaresshan
Remove reference to “get” scheduler functions in docs (dask#4350) Matthew Rocklin
Fix typo in docstring (dask#4376) Daniel Saxton
Added documentation for dask.dataframe.merge (dask#4382) Jendrik Jördening
Core#
Avoid recursion in dask.core.get (dask#4219) Matthew Rocklin
Remove verbose flag from pytest setup.cfg (dask#4281) Matthew Rocklin
Support Pytest 4.0 by specifying marks explicitly (dask#4280) Takahiro Kojima
Add High Level Graphs (dask#4092) Matthew Rocklin
Fix SerializableLock locked and acquire methods (dask#4294) Stephan Hoyer
Pin boto3 to earlier version in tests to avoid moto conflict (dask#4276) Martin Durant
Treat None as missing in config when updating (dask#4324) Matthew Rocklin
Update Appveyor to Python 3.6 (dask#4337) Gábor Lipták
Use parse_bytes more liberally in dask.dataframe/bytes/bag (dask#4339) Matthew Rocklin
Add a better error message when cloudpickle is missing (dask#4342) Mark Harfouche
Support pool= keyword argument in threaded/multiprocessing get functions (dask#4351) Matthew Rocklin
Allow updates from arbitrary Mappings in config.update, not only dicts. (dask#4356) Stuart Berg
Move dask/array/top.py code to dask/blockwise.py (dask#4348) Matthew Rocklin
Add has_parallel_type (dask#4395) Matthew Rocklin
CI: Update Appveyor (dask#4381) Tom Augspurger
1.0.0 / 2018-11-28#
Array#
Add nancumsum/nancumprod unit tests (dask#4215) crusaderky
DataFrame#
Add index to to_dask_dataframe docstring (dask#4232) James Bourbeau
Text and fix when appending categoricals with fastparquet (dask#4245) Martin Durant
Don’t reread metadata when passing ParquetFile to read_parquet (dask#4247) Martin Durant
Documentation#
Core#
Avoid a few warnings (dask#4223) Matthew Rocklin
Remove dask.store module (dask#4221) Matthew Rocklin
Remove AUTHORS.md Jim Crist
0.20.2 / 2018-11-15#
Array#
Avoid fusing dependencies of atop reductions (dask#4207) Matthew Rocklin
Dataframe#
Improve memory footprint for dataframe correlation (dask#4193) Damien Garaud
Add empty DataFrame check to boundary_slice (dask#4212) James Bourbeau
Documentation#
Copy edit documentation (dask#4197) (dask#4204) (dask#4198) (dask#4199) (dask#4200) (dask#4202) (dask#4209) Miguel Farrajota
Add stats module namespace (dask#4206) James Bourbeau
Fix link in dataframe documentation (dask#4208) James Bourbeau
0.20.1 / 2018-11-09#
Array#
Only allocate the result space in wrapped_pad_func (dask#4153) John A Kirkham
Generalize expand_pad_width to expand_pad_value (dask#4150) John A Kirkham
Test da.pad with 2D linear_ramp case (dask#4162) John A Kirkham
Rewrite Dask Array’s pad to add only new chunks (dask#4152) John A Kirkham
Validate index inputs to atop (dask#4182) Matthew Rocklin
Core#
Dask.config set and get normalize underscores and hyphens (dask#4143) James Bourbeau
Only subs on core collections, not subclasses (dask#4159) Matthew Rocklin
Add block_size=0 option to HTTPFileSystem. (dask#4171) Martin Durant
Add traverse support for dataclasses (dask#4165) Armin Berres
Avoid optimization on sharedicts without dependencies (dask#4181) Matthew Rocklin
Update the pytest version for TravisCI (dask#4189) Damien Garaud
Use key_split rather than funcname in visualize names (dask#4160) Matthew Rocklin
Dataframe#
Add fix for DataFrame.__setitem__ for index (dask#4151) Anderson Banihirwe
Fix column choice when passing list of files to fastparquet (dask#4174) Martin Durant
Pass engine_kwargs from read_sql_table to sqlalchemy (dask#4187) Damien Garaud
Documentation#
Fix documentation in Delayed best practices example that returned an empty list (dask#4147) Jonathan Fraine
Copy edit documentation (dask#4164) (dask#4175) (dask#4185) (dask#4192) (dask#4191) (dask#4190) (dask#4180) Miguel Farrajota
Fix typo in docstring (dask#4183) Carlos Valiente
0.20.0 / 2018-10-26#
Array#
Fuse Atop operations (dask#3998), (dask#4081) Matthew Rocklin
Support da.asanyarray on dask dataframes (dask#4080) Matthew Rocklin
Remove unnecessary endianness check in datetime test (dask#4113) Elliott Sales de Andrade
Set name=False in array foo_like functions (dask#4116) Matthew Rocklin
Remove dask.array.ghost module (dask#4121) Matthew Rocklin
Fix use of getargspec in dask array (dask#4125) Stephan Hoyer
Adds dask.array.invert (dask#4127), (dask#4131) Anderson Banihirwe
Raise informative error on arg-reduction on unknown chunksize (dask#4128), (dask#4135) Matthew Rocklin
Normalize reversed slices in dask array (dask#4126) Matthew Rocklin
Bag#
Add bag.to_avro (dask#4076) Martin Durant
Core#
Pull num_workers from config.get (dask#4086), (dask#4093) James Bourbeau
Fix invalid escape sequences with raw strings (dask#4112) Elliott Sales de Andrade
Raise an error on the use of the get= keyword and set_options (dask#4077) Matthew Rocklin
Add import for Azure DataLake storage, and add docs (dask#4132) Martin Durant
Avoid collections.Mapping/Sequence (dask#4138) Matthew Rocklin
Dataframe#
Include index keyword in to_dask_dataframe (dask#4071) Matthew Rocklin
Implement min_count for the DataFrame methods sum and prod (dask#4090) Bart Broere
Remove pandas warnings in concat (dask#4095) Matthew Rocklin
DataFrame.to_csv header option to only output headers in the first chunk (dask#3909) Rahul Vaidya
Remove Series.to_parquet (dask#4104) Justin Dennison
Avoid warnings and deprecated pandas methods (dask#4115) Matthew Rocklin
Swap ‘old’ and ‘previous’ when reporting append error (dask#4130) Martin Durant
Documentation#
Copy edit documentation (dask#4073), (dask#4074), (dask#4094), (dask#4097), (dask#4107), (dask#4124), (dask#4133), (dask#4139) Miguel Farrajota
Fix typo in code example (dask#4089) Antonino Ingargiola
Quick description for gcsfs (dask#4109) Martin Durant
Fixed typo in docstrings of read_sql_table method (dask#4114) TakaakiFuruse
Make target directories in redirects if they don’t exist (dask#4136) Matthew Rocklin
0.19.4 / 2018-10-09#
Array#
Implement
apply_gufunc(..., axes=..., keepdims=...)(dask#3985) Markus Gonser
Bag#
Fix typo in datasets.make_people (dask#4069) Matthew Rocklin
Dataframe#
Added percentiles options for dask.dataframe.describe method (dask#4067) Zhenqing Li
Add DataFrame.partitions accessor similar to Array.blocks (dask#4066) Matthew Rocklin
Core#
Pass get functions and Clients through scheduler keyword (dask#4062) Matthew Rocklin
Documentation#
Fix Typo on hpc example. (missing = in kwarg). (dask#4068) Matthias Bussonier
Extensive copy-editing: (dask#4065), (dask#4064), (dask#4063) Miguel Farrajota
0.19.3 / 2018-10-05#
Array#
Make da.RandomState extensible to other modules (dask#4041) Matthew Rocklin
Support unknown dims in ravel no-op case (dask#4055) Jim Crist
Add basic infrastructure for cupy (dask#4019) Matthew Rocklin
Avoid asarray and lock arguments for from_array(getitem) (dask#4044) Matthew Rocklin
Move local imports in corrcoef to global imports (dask#4030) John A Kirkham
Move local indices import to global import (dask#4029) John A Kirkham
Fix-up Dask Array’s fromfunction w.r.t. dtype and kwargs (dask#4028) John A Kirkham
Don’t use dummy expansion for trim_internal in overlapped (dask#3964) Mark Harfouche
Add unravel_index (dask#3958) John A Kirkham
Bag#
Sort result in Bag.frequencies (dask#4033) Matthew Rocklin
Add support for npartitions=1 edge case in groupby (dask#4050) James Bourbeau
Add new random dataset for people (dask#4018) Matthew Rocklin
Improve performance of bag.read_text on small files (dask#4013) Eric Wolak
Add bag.read_avro (dask#4000) (dask#4007) Martin Durant
Dataframe#
Added an
indexparameter todask.dataframe.from_dask_array()for creating a dask DataFrame from a dask Array with a given index. (dask#3991) Tom AugspurgerImprove sub-classability of dask dataframe (dask#4015) Matthew Rocklin
fuse_subgraphs works without normal fuse (dask#4042) Jim Crist
Make path for reading many parquet files without prescan (dask#3978) Martin Durant
Index in dd.from_dask_array (dask#3991) Tom Augspurger
Making skiprows accept lists (dask#3975) Julia Signell
Fail early in fastparquet read for nonexistent column (dask#3989) Martin Durant
Core#
Add support for npartitions=1 edge case in groupby (dask#4050) James Bourbeau
Automatically wrap large arguments with dask.delayed in map_blocks/partitions (dask#4002) Matthew Rocklin
Make multiprocessing context configurable (dask#3763) Itamar Turner-Trauring
Documentation#
Extensive copy-editing (dask#4049), (dask#4034), (dask#4031), (dask#4020), (dask#4021), (dask#4022), (dask#4023), (dask#4016), (dask#4017), (dask#4010), (dask#3997), (dask#3996), Miguel Farrajota
Update shuffle method selection docs (dask#4048) James Bourbeau
Remove docs/source/examples, point to examples.dask.org (dask#4014) Matthew Rocklin
Replace readthedocs links with dask.org (dask#4008) Matthew Rocklin
Updates DataFrame.to_hdf docstring for returned values (dask#3992) James Bourbeau
0.19.2 / 2018-09-17#
Array#
apply_gufuncimplements automatic infer of functions output dtypes (dask#3936) Markus GonserFix array histogram range error when array has nans (dask#3980) James Bourbeau
from_array: add @martindurant’s explaining of how hashing is done for an array. (dask#3965) Mark Harfouche
Support gradient with coordinate (dask#3949) Keisuke Fujii
Core#
Fix use of has_keyword with partial in Python 2.7 (dask#3966) Mark Harfouche
Set pyarrow as default for HDFS (dask#3957) Matthew Rocklin
Documentation#
Use dask_sphinx_theme (dask#3963) Matthew Rocklin
Use JupyterLab in Binder links from main page Matthew Rocklin
DOC: fixed sphinx syntax (dask#3960) Tom Augspurger
0.19.1 / 2018-09-06#
Array#
Don’t enforce dtype if result has no dtype (dask#3928) Matthew Rocklin
Fix NumPy issubtype deprecation warning (dask#3939) Bruce Merry
Fix arg reduction tokens to be unique with different arguments (dask#3955) Tobias de Jong
Coerce numpy integers to ints in slicing code (dask#3944) Yu Feng
Linalg.norm ndim along axis partial fix (dask#3933) Tobias de Jong
Dataframe#
Deterministic DataFrame.set_index (dask#3867) George Sakkis
Fix divisions in read_parquet when dealing with filters #3831 #3930 (dask#3923) (dask#3931) @andrethrill
Fixing returning type in categorical.as_known (dask#3888) Sriharsha Hatwar
Fix DataFrame.assign for callables (dask#3919) Tom Augspurger
Include partitions with no width in repartition (dask#3941) Matthew Rocklin
Don’t constrict stage/k dtype in dataframe shuffle (dask#3942) Matthew Rocklin
Documentation#
DOC: Add hint on how to render task graphs horizontally (dask#3922) Uwe Korn
Add try-now button to main landing page (dask#3924) Matthew Rocklin
0.19.0 / 2018-08-29#
Array#
Support coordinate in gradient (dask#3949) Keisuke Fujii
Fix argtopk split_every bug (dask#3810) crusaderky
Ensure result computing dask.array.isnull() always gives a numpy array (dask#3825) Stephan Hoyer
Support concatenate for scipy.sparse in dask array (dask#3836) Matthew Rocklin
Fix argtopk on 32-bit systems. (dask#3823) Elliott Sales de Andrade
Normalize keys in rechunk (dask#3820) Matthew Rocklin
Allow shape of dask.array to be a numpy array (dask#3844) Mark Harfouche
Fix numpy deprecation warning on tuple indexing (dask#3851) Tobias de Jong
Rename ghost module to overlap (dask#3830) Robert Sare
Re-add the ghost import to da __init__ (dask#3861) Jim Crist
Ensure copy preserves masked arrays (dask#3852) Tobias de Jong
DataFrame#
Added
dtypeandsparsekeywords todask.dataframe.get_dummies()(dask#3792) Tom AugspurgerAdded
dask.dataframe.to_dask_array()for converting a Dask Series or DataFrame to a Dask Array, possibly with known chunk sizes (dask#3884) Tom AugspurgerChanged the behavior for
dask.array.asarray()for dask dataframe and series inputs. Previously, the series was eagerly converted to an in-memory NumPy array before creating a dask array with known chunks sizes. This caused unexpectedly high memory usage. Now, no intermediate NumPy array is created, and a Dask array with unknown chunk sizes is returned (dask#3884) Tom AugspurgerDataFrame.iloc (dask#3805) Tom Augspurger
When reading multiple paths, expand globs. (dask#3828) Irina Truong
Added index column name after resample (dask#3833) Eric Bonfadini
Add (lazy) shape property to dataframe and series (dask#3212) Henrique Ribeiro
Rename to_csv keys for diagnostics (dask#3890) Matthew Rocklin
Match pandas warnings for concat sort (dask#3897) Tom Augspurger
Include filename in read_csv (dask#3908) Julia Signell
Core#
Better error message on import when missing common dependencies (dask#3771) Danilo Horta
Add DASK_ROOT_CONFIG environment variable (dask#3849) Joe Hamman
Don’t cull in local scheduler, do cull in delayed (dask#3856) Jim Crist
Add python_requires and Trove classifiers (dask#3855) @hugovk
Fix collections.abc deprecation warnings in Python 3.7.0 (dask#3876) Jan Margeta
Allow dot jpeg to xfail in visualize tests (dask#3896) Matthew Rocklin
Add Python 3.7 to travis.yml (dask#3894) Matthew Rocklin
Add expand_environment_variables to dask.config (dask#3893) Joe Hamman
Docs#
Fix typo in import statement of diagnostics (dask#3826) John Mrziglod
fix of minor typos in landing page index.html (dask#3746) Christoph Moehl
Update delayed-custom.rst (dask#3850) Anderson Banihirwe
DOC: clarify delayed docstring (dask#3709) Scott Sievert
Add dask array normalize_chunks to documentation (dask#3878) Daniel Rothenberg
Docs: Fix link to snakeviz (dask#3900) Hans Moritz Günther
0.18.2 / 2018-07-23#
Array#
Reimplemented
argtopkto make it release the GIL (dask#3610) crusaderkyDon’t overlap on non-overlapped dimensions in
map_overlap(dask#3653) Matthew RocklinFix
linalg.tsqrfor dimensions of uncertain length (dask#3662) Jeremy ChenBreak apart uneven array-of-int slicing to separate chunks (dask#3648) Matthew Rocklin
Align auto chunks to provided chunks, rather than shape (dask#3679) Matthew Rocklin
Adds endpoint and retstep support for linspace (dask#3675) James Bourbeau
Implement
.blocksaccessor (dask#3689) Matthew RocklinAdd
block_infokeyword tomap_blocksfunctions (dask#3686) Matthew RocklinSlice by dask array of ints (dask#3407) crusaderky
Support
dtypeinarange(dask#3722) crusaderkyFix
argtopkwith uneven chunks (dask#3720) crusaderkyRaise error when
replace=Falseinda.choice(dask#3765) James BourbeauUpdate chunks in
Array.__setitem__(dask#3767) Itamar Turner-TrauringAdd a
chunksizeconvenience property (dask#3777) Jacob TomlinsonFix and simplify array slicing behavior when
step < 0(dask#3702) Ziyao WeiEnsure
to_zarrwithreturn_storedTruereturns a Dask Array (dask#3786) John A Kirkham
Bag#
Add
last_endlineoptional parameter into_textfiles(dask#3745) George Sakkis
Dataframe#
Add aggregate function for rolling objects (dask#3772) Gerome Pistre
Properly tokenize cumulative groupby aggregations (dask#3799) Cloves Almeida
Delayed#
Add the
@operator to the delayed objects (dask#3691) Mark HarfoucheAdd delayed best practices to documentation (dask#3737) Matthew Rocklin
Fix
@delayeddecorator for methods and add tests (dask#3757) Ziyao Wei
Core#
Fix extra progressbar (dask#3669) Mike Neish
Allow tasks back onto ordering stack if they have one dependency (dask#3652) Matthew Rocklin
Prefer end-tasks with low numbers of dependencies when ordering (dask#3588) Tom Augspurger
Add
assert_eqto top-level modules (dask#3726) Matthew RocklinTest that dask collections can hold
scipy.sparsearrays (dask#3738) Matthew RocklinFix setup of lz4 decompression functions (dask#3782) Elliott Sales de Andrade
Add datasets module (dask#3780) Matthew Rocklin
0.18.1 / 2018-06-22#
Array#
from_arraynow supports scalar types and nested lists/tuples in input, just like all numpy functions do; it also produces a simpler graph when the input is a plain ndarray (dask#3568) crusaderkyFix slicing of big arrays due to cumsum dtype bug (dask#3620) Marco Rossi
Add Dask Array implementation of pad (dask#3578) John A Kirkham
Fix array random API examples (dask#3625) James Bourbeau
Add average function to dask array (dask#3640) James Bourbeau
Tokenize ghost_internal with axes (dask#3643) Matthew Rocklin
Add outer for Dask Arrays (dask#3658) John A Kirkham
DataFrame#
Add Index.to_series method (dask#3613) Henrique Ribeiro
Fix missing partition columns in pyarrow-parquet (dask#3636) Martin Durant
Core#
Minor tweaks to CI (dask#3629) crusaderky
Add back dask.utils.effective_get (dask#3642) Matthew Rocklin
DASK_CONFIG dictates config write location (dask#3621) Jim Crist
Replace ‘collections’ key in unpack_collections with unique key (dask#3632) Yu Feng
Avoid deepcopy in dask.config.set (dask#3649) Matthew Rocklin
0.18.0 / 2018-06-14#
Array#
Add to/from_zarr for Zarr-format datasets and arrays (dask#3460) Martin Durant
Experimental addition of generalized ufunc support,
apply_gufunc,gufunc, andas_gufunc(dask#3109) (dask#3526) (dask#3539) Markus GonserAvoid unnecessary rechunking tasks (dask#3529) Matthew Rocklin
Compute dtypes at runtime for fft (dask#3511) Matthew Rocklin
Generate UUIDs for all da.store operations (dask#3540) Martin Durant
Correct internal dimension of Dask’s SVD (dask#3517) John A Kirkham
BUG: do not raise IndexError for identity slice in array.vindex (dask#3559) Scott Sievert
Adds isneginf and isposinf (dask#3581) John A Kirkham
Drop Dask Array’s learn module (dask#3580) John A Kirkham
added sfqr (short-and-fat) as a counterpart to tsqr… (dask#3575) Jeremy Chen
Allow 0-width chunks in dask.array.rechunk (dask#3591) Marc Pfister
Document Dask Array’s nan_to_num in public API (dask#3599) John A Kirkham
Show block example (dask#3601) John A Kirkham
Replace token= keyword with name= in map_blocks (dask#3597) Matthew Rocklin
Disable locking in to_zarr (needed for using to_zarr in a distributed context) (dask#3607) John A Kirkham
Support Zarr Arrays in to_zarr/from_zarr (dask#3561) John A Kirkham
Added recursion to array/linalg/tsqr to better manage the single core bottleneck (dask#3586) Jeremy Chan (dask#3396) crusaderky
Dataframe#
Add to/read_json (dask#3494) Martin Durant
Adds
indexto unsupported arguments forDataFrame.renamemethod (dask#3522) James BourbeauAdds support to subset Dask DataFrame columns using
numpy.ndarray,pandas.Series, andpandas.Indexobjects (dask#3536) James BourbeauRaise error if meta columns do not match dataframe (dask#3485) Christopher Ren
Add index to unsupprted argument for DataFrame.rename (dask#3522) James Bourbeau
Adds support for subsetting DataFrames with pandas Index/Series and numpy ndarrays (dask#3536) James Bourbeau
Dataframe sample method docstring fix (dask#3566) James Bourbeau
fixes dd.read_json to infer file compression (dask#3594) Matt Lee
Adds n to sample method (dask#3606) James Bourbeau
Add fastparquet ParquetFile object support (dask#3573) @andrethrill
Bag#
Rename method= keyword to shuffle= in bag.groupby (dask#3470) Matthew Rocklin
Core#
Replace get= keyword with scheduler= keyword (dask#3448) Matthew Rocklin
Add centralized dask.config module to handle configuration for all Dask subprojects (dask#3432) (dask#3513) (dask#3520) Matthew Rocklin
Add dask-ssh CLI Options and Description. (dask#3476) @beomi
Read whole files fix regardless of header for HTTP (dask#3496) Martin Durant
Adds synchronous scheduler syntax to debugging docs (dask#3509) James Bourbeau
Replace dask.set_options with dask.config.set (dask#3502) Matthew Rocklin
Update sphinx readthedocs-theme (dask#3516) Matthew Rocklin
Introduce “auto” value for normalize_chunks (dask#3507) Matthew Rocklin
Fix check in configuration with env=None (dask#3562) Simon Perkins
Update sizeof definitions (dask#3582) Matthew Rocklin
Remove –verbose flag from travis-ci (dask#3477) Matthew Rocklin
Remove “da.random” from random array keys (dask#3604) Matthew Rocklin
0.17.5 / 2018-05-16#
Array#
Fix
rechunkwith chunksize of -1 in a dict (dask#3469) Stephan Hoyereinsumnow accepts thesplit_everyparameter (dask#3471) crusaderky
DataFrame#
Compatibility with pandas 0.23.0 (dask#3499) Tom Augspurger
0.17.4 / 2018-05-03#
Dataframe#
Add support for indexing Dask DataFrames with string subclasses (dask#3461) James Bourbeau
Allow using both sorted_index and chunksize in read_hdf (dask#3463) Pierre Bartet
Pass filesystem to arrow piece reader (dask#3466) Martin Durant
Switches to using dask.compat string_types (dask#3462) James Bourbeau
0.17.3 / 2018-05-02#
Array#
Add
einsumfor Dask Arrays (dask#3412) Simon PerkinsAdd
piecewisefor Dask Arrays (dask#3350) John A KirkhamFix handling of
naninbroadcast_shapes(dask#3356) John A KirkhamAdd
isinfor dask arrays (dask#3363). Stephan HoyerOverhauled
topkfor Dask Arrays: faster algorithm, particularly for large k’s; added support for multiple axes, recursive aggregation, and an option to pick the bottom k elements instead. (dask#3395) crusaderkyThe
topkAPI has changed from topk(k, array) to the more conventional topk(array, k). The legacy API still works but is now deprecated. (dask#2965) crusaderkyNew function
argtopkfor Dask Arrays (dask#3396) crusaderkyFix handling partial depth and boundary in
map_overlap(dask#3445) John A KirkhamAdd
gradientfor Dask Arrays (dask#3434) John A Kirkham
DataFrame#
Allow t as shorthand for table in to_hdf for pandas compatibility (dask#3330) Jörg Dietrich
Added top level isna method for Dask DataFrames (dask#3294) Christopher Ren
Fix selection on partition column on
read_parquetforengine="pyarrow"(dask#3207) Uwe KornAdded DataFrame.squeeze method (dask#3366) Christopher Ren
Added infer_divisions option to
read_parquetto specify whether read engines should compute divisions (dask#3387) Jon MeaseAdded support for inferring division for
engine="pyarrow"(dask#3387) Jon MeaseProvide more informative error message for meta= errors (dask#3343) Matthew Rocklin
add orc reader (dask#3284) Martin Durant
Default compression for parquet now always Snappy, in line with pandas (dask#3373) Martin Durant
Fixed bug in Dask DataFrame and Series comparisons with NumPy scalars (dask#3436) James Bourbeau
Remove outdated requirement from repartition docstring (dask#3440) Jörg Dietrich
Fixed bug in aggregation when only a Series is selected (dask#3446) Jörg Dietrich
Add default values to make_timeseries (dask#3421) Matthew Rocklin
Core#
Support traversing collections in persist, visualize, and optimize (dask#3410) Jim Crist
Add schedule= keyword to compute and persist. This replaces common use of the get= keyword (dask#3448) Matthew Rocklin
0.17.2 / 2018-03-21#
Array#
Add
broadcast_arraysfor Dask Arrays (dask#3217) John A KirkhamAdd
bitwise_*ufuncs (dask#3219) John A KirkhamAdd optional
axisargument tosqueeze(dask#3261) John A KirkhamValidate inputs to atop (dask#3307) Matthew Rocklin
Avoid calls to astype in concatenate if all parts have the same dtype (dask#3301) Martin Durant
DataFrame#
Fixed bug in shuffle due to aggressive truncation (dask#3201) Matthew Rocklin
Support specifying categorical columns on
read_parquetwithcategories=[…]forengine="pyarrow"(dask#3177) Uwe KornAdd
dd.tseries.Resampler.agg(dask#3202) Richard PostelnikSupport operations that mix dataframes and arrays (dask#3230) Matthew Rocklin
Support extra Scalar and Delayed args in
dd.groupby._Groupby.apply(dask#3256) Gabriele Lanaro
Bag#
Support joining against single-partitioned bags and delayed objects (dask#3254) Matthew Rocklin
Core#
Fixed bug when using unexpected but hashable types for keys (dask#3238) Daniel Collins
Fix bug in task ordering so that we break ties consistently with the key name (dask#3271) Matthew Rocklin
Avoid sorting tasks in order when the number of tasks is very large (dask#3298) Matthew Rocklin
0.17.1 / 2018-02-22#
Array#
Corrected dimension chunking in indices (dask#3166, dask#3167) Simon Perkins
Inline
store_chunkcalls forstore’sreturn_storedoption (dask#3153) John A KirkhamCompatibility with struct dtypes for NumPy 1.14.1 release (dask#3187) Matthew Rocklin
DataFrame#
Bugfix to allow column assignment of pandas datetimes(dask#3164) Max Epstein
Core#
New file-system for HTTP(S), allowing direct loading from specific URLs (dask#3160) Martin Durant
Fix bug when tokenizing partials with no keywords (dask#3191) Matthew Rocklin
Use more recent LZ4 API (dask#3157) Thrasibule
Introduce output stream parameter for progress bar (dask#3185) Dieter Weber
0.17.0 / 2018-02-09#
Array#
Added a support object-type arrays for nansum, nanmin, and nanmax (dask#3133) Keisuke Fujii
Update error handling when len is called with empty chunks (dask#3058) Xander Johnson
Fixes a metadata bug with
store’sreturn_storedoption (dask#3064) John A KirkhamFix a bug in
optimization.fuse_sliceto properly handle when first input isNone(dask#3076) James BourbeauSupport arrays with unknown chunk sizes in percentile (dask#3107) Matthew Rocklin
Tokenize scipy.sparse arrays and np.matrix (dask#3060) Roman Yurchak
DataFrame#
Support month timedeltas in repartition(freq=…) (dask#3110) Matthew Rocklin
Avoid mutation in dataframe groupby tests (dask#3118) Matthew Rocklin
read_csv,read_table, andread_parquetaccept iterables of paths (dask#3124) Jim CristDeprecates the
dd.to_delayedfunction in favor of the existing method (dask#3126) Jim CristReturn dask.arrays from df.map_partitions calls when the UDF returns a numpy array (dask#3147) Matthew Rocklin
Change handling of
columnsandindexindd.read_parquetto be more consistent, especially in handling of multi-indices (dask#3149) Jim Cristfastparquet append=True allowed to create new dataset (dask#3097) Martin Durant
dtype rationalization for sql queries (dask#3100) Martin Durant
Bag#
Core#
Change default task ordering to prefer nodes with few dependents and then many downstream dependencies (dask#3056) Matthew Rocklin
Add color= option to visualize to color by task order (dask#3057) (dask#3122) Matthew Rocklin
Remove short-circuit hdfs reads handling due to maintenance costs. May be re-added in a more robust manner later (dask#3079) Jim Crist
Add
dask.base.optimizefor optimizing multiple collections without computing. (dask#3071) Jim CristRename
dask.optimizemodule todask.optimization(dask#3071) Jim CristChange task ordering to do a full traversal (dask#3066) Matthew Rocklin
Adds an
optimize_graphkeyword to allto_delayedmethods to allow controlling whether optimizations occur on conversion. (dask#3126) Jim CristSupport using
pyarrowfor hdfs integration (dask#3123) Jim CristMove HDFS integration and tests into dask repo (dask#3083) Jim Crist
0.16.1 / 2018-01-09#
Array#
Fix handling of scalar percentile values in
percentile(dask#3021) James BourbeauPrevent
bool()coercion from calling compute (dask#2958) Albert DeFuscoAdd
matmul(dask#2904) John A KirkhamSupport N-D arrays with
matmul(dask#2909) John A KirkhamAdd
vdot(dask#2910) John A KirkhamExplicit
chunksargument forbroadcast_to(dask#2943) Stephan HoyerAdd
meshgrid(dask#2938) John A Kirkham and (dask#3001) Markus GonserPreserve singleton chunks in
fftshift/ifftshift(dask#2733) John A KirkhamFix handling of negative indexes in
vindexand raise errors for out of bounds indexes (dask#2967) Stephan HoyerAdd
flip,flipud,fliplr(dask#2954) John A KirkhamAdd
float_powerufunc (dask#2962) (dask#2969) John A KirkhamCompatibility for changes to structured arrays in the upcoming NumPy 1.14 release (dask#2964) Tom Augspurger
Add
block(dask#2650) John A KirkhamAdd the
return_storedoption tostorefor chaining stored results (dask#2980) John A Kirkham
DataFrame#
Fixed naming bug in cumulative aggregations (dask#3037) Martijn Arts
Fixed
dd.read_csvwhennamesis given butheaderis not set toNone(dask#2976) Martijn ArtsFixed
dd.read_csvso that passing instances ofCategoricalDtypeindtypewill result in known categoricals (dask#2997) Tom AugspurgerPrevent
bool()coercion from calling compute (dask#2958) Albert DeFuscoDataFrame.read_sql()(dask#2928) to an empty database tables returns an empty dask dataframe Apostolos VlachopoulosCompatibility for reading Parquet files written by PyArrow 0.8.0 (dask#2973) Tom Augspurger
Correctly handle the column name (df.columns.name) when reading in
dd.read_parquet(dask#2973) Tom AugspurgerFixed
dd.concatlosing the index dtype when the data contained a categorical (dask#2932) Tom AugspurgerDataFrame.merge()now supports merging on a combination of columns and the index (dask#2960) Jon MeaseRemoved the deprecated
dd.rolling*methods, in preparation for their removal in the next pandas release (dask#2995) Tom AugspurgerFix metadata inference bug in which single-partition series were mistakenly special cased (dask#3035) Jim Crist
Core#
Improve 32-bit compatibility (dask#2937) Matthew Rocklin
Change task prioritization to avoid upwards branching (dask#3017) Matthew Rocklin
0.16.0 / 2017-11-17#
This is a major release. It includes breaking changes, new protocols, and a large number of bug fixes.
Array#
Add
atleast_1d,atleast_2d, andatleast_3d(dask#2760) (dask#2765) John A KirkhamAdd
allclose(dask#2771) by John A KirkhamRemove
random.different_seedsfrom Dask Array API docs (dask#2772) John A KirkhamDeprecate
vnormin favor ofdask.array.linalg.norm(dask#2773) John A KirkhamReimplement
uniqueto be lazy (dask#2775) John A KirkhamSupport broadcasting of Dask Arrays with 0-length dimensions (dask#2784) John A Kirkham
Add
asarrayandasanyarrayto Dask Array API docs (dask#2787) James BourbeauSupport
unique’sreturn_*arguments (dask#2779) John A KirkhamSimplify
_unique_internal(dask#2850) (dask#2855) John A KirkhamAvoid removing some getter calls in array optimizations (dask#2826) Jim Crist
DataFrame#
Fixed
DataFrame.quantileandSeries.quantilereturningnanwhen missing values are present (dask#2791) Tom AugspurgerFixed
DataFrame.quantilelosing the result.namewhenqis a scalar (dask#2791) Tom AugspurgerFixed
dd.concatreturn adask.Dataframewhen concatenating a single series along the columns, matching pandas’ behavior (dask#2800) James MunroeFixed default inplace parameter for
DataFrame.evalto match the pandas defualt for pandas >= 0.21.0 (dask#2838) Tom AugspurgerFix exception when calling
DataFrame.set_indexon text column where one of the partitions was empty (dask#2831) Jesse VogtDo not raise exception when calling
DataFrame.set_indexon empty dataframe (dask#2827) Jesse VogtFixed bug in
Dataframe.fillnawhen filling with aSeriesvalue (dask#2810) Tom AugspurgerDeprecate old argument ordering in
dd.to_parquetto better match convention of putting the dataframe first (dask#2867) Jim Cristdf.astype(categorical_dtype -> known categoricals (dask#2835) Jim Crist
Test against Pandas release candidate (dask#2814) Tom Augspurger
Add more tests for read_parquet(engine=’pyarrow’) (dask#2822) Uwe Korn
Remove unnecessary map_partitions in aggregate (dask#2712) Christopher Prohm
Fix bug calling sample on empty partitions (dask#2818) @xwang777
Error nicely when parsing dates in read_csv (dask#2863) Jim Crist
Cleanup handling of passing filesystem objects to PyArrow readers (dask#2527) @fjetter
Support repartitioning even if there are no divisions (dask#2873) @Ced4
Support reading/writing to hdfs using
pyarrowindd.to_parquet(dask#2894, dask#2881) Jim Crist
Core#
Allow tuples as sharedict keys (dask#2763) Matthew Rocklin
Calling compute within a dask.distributed task defaults to distributed scheduler (dask#2762) Matthew Rocklin
Auto-import gcsfs when gcs:// protocol is used (dask#2776) Matthew Rocklin
Fully remove dask.async module, use dask.local instead (dask#2828) Thomas Caswell
Compatibility with bokeh 0.12.10 (dask#2844) Tom Augspurger
Update Dask collection interface during XArray integration (dask#2847) Matthew Rocklin
Close resource profiler process on __exit__ (dask#2871) Jim Crist
Fix port for bokeh dashboard in docs (dask#2889) Ian Hopkinson
Wrap Dask filesystems for PyArrow compatibility (dask#2881) Jim Crist
0.15.4 / 2017-10-06#
Array#
DataFrame#
Bag#
Add tree reduction support for foldby (dask#2710)
Core#
Drop s3fs from
pip install dask[complete](dask#2750)
0.15.3 / 2017-09-24#
Array#
Add masked arrays (dask#2301)
Add
*_like array creation functions(dask#2640)Indexing with unsigned integer array (dask#2647)
Improved slicing with boolean arrays of different dimensions (dask#2658)
Support literals in
topandatop(dask#2661)Optional axis argument in cumulative functions (dask#2664)
Improve tests on scalars with
assert_eq(dask#2681)Fix norm keepdims (dask#2683)
Add
ptp(dask#2691)Add apply_along_axis (dask#2690) and apply_over_axes (dask#2702)
DataFrame#
Added
Series.str[index](dask#2634)Allow the groupby by param to handle columns and index levels (dask#2636)
DataFrame.to_csvandBag.to_textfilesnow return the filenames towhich they have written (dask#2655)
Fix combination of
partition_onandappendinto_parquet(dask#2645)Fix for parquet file schemes (dask#2667)
Repartition works with mixed categoricals (dask#2676)
Core#
0.15.2 / 2017-08-25#
Array#
Remove spurious keys from map_overlap graph (dask#2520)
where works with non-bool condition and scalar values (dask#2543) (dask#2549)
Add argwhere, _nonzero, and where(cond) (dask#2539)
Generalize vindex in dask.array to handle multi-dimensional indices (dask#2573)
Add choose method (dask#2584)
Split code into reorganized files (dask#2595)
Add linalg.norm (dask#2597)
Improve dtype inference and reflection (dask#2571)
Bag#
Remove deprecated Bag behaviors (dask#2525)
DataFrame#
Core#
Remove bare
except:blocks everywhere (dask#2590)
0.15.1 / 2017-07-08#
0.15.0 / 2017-06-09#
Array#
Add dask.array.stats submodule (dask#2269)
Support
ufunc.outer(dask#2345)Optimize fancy indexing by reducing graph overhead (dask#2333) (dask#2394)
Faster array tokenization using alternative hashes (dask#2377)
Added the matmul
@operator (dask#2349)Improved coverage of the
numpy.fftmodule (dask#2320) (dask#2322) (dask#2327) (dask#2323)Support NumPy’s
__array_ufunc__protocol (dask#2438)
Bag#
DataFrame#
Core#
0.14.3 / 2017-05-05#
DataFrame#
Pandas 0.20.0 support
0.14.2 / 2017-05-03#
Array#
Add da.indices (dask#2268), da.tile (dask#2153), da.roll (dask#2135)
Simultaneously support drop_axis and new_axis in da.map_blocks (dask#2264)
Rechunk and concatenate work with unknown chunksizes (dask#2235) and (dask#2251)
Support non-numpy container arrays, notably sparse arrays (dask#2234)
Tensordot contracts over multiple axes (dask#2186)
Allow delayed targets in da.store (dask#2181)
Support interactions against lists and tuples (dask#2148)
Constructor plugins for debugging (dask#2142)
Multi-dimensional FFTs (single chunk) (dask#2116)
Bag#
to_dataframe enforces consistent types (dask#2199)
DataFrame#
Core#
0.14.1 / 2017-03-22#
Array#
Micro-optimize optimizations (dask#2058)
Change slicing optimizations to avoid fusing raw numpy arrays (dask#2075) (dask#2080)
Dask.array operations now work on numpy arrays (dask#2079)
Reshape now works in a much broader set of cases (dask#2089)
Support deepcopy python protocol (dask#2090)
Allow user-provided FFT implementations in
da.fft(dask#2093)
DataFrame#
Fix to_parquet with empty partitions (dask#2020)
Optional
npartitions='auto'mode inset_index(dask#2025)Optimize shuffle performance (dask#2032)
Support efficient repartitioning along time windows like
repartition(freq='12h')(dask#2059)Improve speed of categorize (dask#2010)
Support single-row dataframe arithmetic (dask#2085)
Automatically avoid shuffle when setting index with a sorted column (dask#2091)
Improve handling of integer-na handling in read_csv (dask#2098)
Delayed#
Repeated attribute access on delayed objects uses the same key (dask#2084)
Core#
0.14.0 / 2017-02-24#
Array#
Bag#
DataFrame#
Delayed#
Core#
Improve windows path parsing in corner cases (dask#1910)
Rename tasks when fusing (dask#1919)
Add top level
persistfunction (dask#1927)Propagate
errors=keyword in byte handling (dask#1954)Dask.compute traverses Python collections (dask#1975)
Structural sharing between graphs in dask.array and dask.delayed (dask#1985)
0.13.0 / 2017-01-02#
Array#
Mandatory dtypes on dask.array. All operations maintain dtype information and UDF functions like map_blocks now require a dtype= keyword if it can not be inferred. (dask#1755)
Support arrays without known shapes, such as arises when slicing arrays with arrays or converting dataframes to arrays (dask#1838)
Support mutation by setting one array with another (dask#1840)
Tree reductions for covariance and correlations. (dask#1758)
Add SerializableLock for better use with distributed scheduling (dask#1766)
Improved atop support (dask#1800)
Bag#
Avoid wrong results when recomputing the same groupby twice (dask#1867)
DataFrame#
Add
map_overlapfor custom rolling operations (dask#1769)Add
shift(dask#1773)Add Parquet support (dask#1782) (dask#1792) (dask#1810), (dask#1843), (dask#1859), (dask#1863)
Add missing methods combine, abs, autocorr, sem, nsmallest, first, last, prod, (dask#1787)
Reductions with multiple output partitions (for operations like drop_duplicates) (dask#1808), (dask#1823) (dask#1828)
Add delitem and copy to DataFrames, increasing mutation support (dask#1858)
Delayed#
Changed behaviour for
delayed(nout=0)anddelayed(nout=1):delayed(nout=1)does not default toout=Noneanymore, anddelayed(nout=0)is also enabled. I.e. functions with return tuples of length 1 or 0 can be handled correctly. This is especially handy, if functions with a variable amount of outputs are wrapped bydelayed. E.g. a trivial example:delayed(lambda *args: args, nout=len(vals))(*vals)
Core#
0.12.0 / 2016-11-03#
DataFrame#
Return a series when functions given to
dataframe.map_partitionsreturn scalars (dask#1515)Fix type size inference for series (dask#1513)
dataframe.DataFrame.categorizeno longer includes missing values in thecategories. This is for compatibility with a pandas change (dask#1565)Fix head parser error in
dataframe.read_csvwhen some lines have quotes (dask#1495)Add
dataframe.reductionandseries.reductionmethods to apply generic row-wise reduction to dataframes and series (dask#1483)Add
dataframe.select_dtypes, which mirrors the pandas method (dask#1556)dataframe.read_hdfnow supports readingSeries(dask#1564)Support Pandas 0.19.0 (dask#1540)
Implement
select_dtypes(dask#1556)String accessor works with indexes (dask#1561)
Add pipe method to dask.dataframe (dask#1567)
Add
indicatorkeyword to merge (dask#1575)Support Series in
read_hdf(dask#1575)Support Categories with missing values (dask#1578)
Support inplace operators like
df.x += 1(dask#1585)Str accessor passes through args and kwargs (dask#1621)
Improved groupby support for single-machine multiprocessing scheduler (dask#1625)
Tree reductions (dask#1663)
Pivot tables (dask#1665)
Add clip (dask#1667), align (dask#1668), combine_first (dask#1725), and any/all (dask#1724)
Improved handling of divisions on dask-pandas merges (dask#1666)
Add
groupby.aggregatemethod (dask#1678)Add
dd.read_tablefunction (dask#1682)Improve support for multi-level columns (dask#1697) (dask#1712)
Support 2d indexing in
loc(dask#1726)Extend
resampleto include DataFrames (dask#1741)Support dask.array ufuncs on dask.dataframe objects (dask#1669)
Array#
Add information about how
dask.arraychunksargument work (dask#1504)Fix field access with non-scalar fields in
dask.array(dask#1484)Add concatenate= keyword to atop to concatenate chunks of contracted dimensions
Extend
atopwith aconcatenate=(dask#1609)new_axes=(dask#1612) andadjust_chunks=(dask#1716) keywordsAdd clip (dask#1610) swapaxes (dask#1611) round (dask#1708) repeat
Automatically align chunks in
atop-backed operations (dask#1644)Cull dask.arrays on slicing (dask#1709)
Bag#
Administration#
Added changelog (dask#1526)
Create new threadpool when operating from thread (dask#1487)
Unify example documentation pages into one (dask#1520)
Add versioneer for git-commit based versions (dask#1569)
Pass through node_attr and edge_attr keywords in dot visualization (dask#1614)
Add continuous testing for Windows with Appveyor (dask#1648)
Remove use of multiprocessing.Manager (dask#1653)
Add global optimizations keyword to compute (dask#1675)
Micro-optimize get_dependencies (dask#1722)
0.11.0 / 2016-08-24#
Major Points#
DataFrames now enforce knowing full metadata (columns, dtypes) everywhere.
Previously we would operate in an ambiguous state when functions lost dtype
information (such as apply). Now all dataframes always know their dtypes
and raise errors asking for information if they are unable to infer (which
they usually can). Some internal attributes like _pd and
_pd_nonempty have been moved.
The internals of the distributed scheduler have been refactored to transition tasks between explicit states. This improves resilience, reasoning about scheduling, plugin operation, and logging. It also makes the scheduler code easier to understand for newcomers.
Breaking Changes#
The
distributed.s3anddistributed.hdfsnamespaces are gone. Use protocols in normal methods likeread_text('s3://...'instead.Dask.array.reshapenow errs in some cases where previously it would have create a very large number of tasks
0.10.2 / 2016-07-27#
More Dataframe shuffles now work in distributed settings, ranging from setting-index to hash joins, to sorted joins and groupbys.
Dask passes the full test suite when run when under in Python’s optimized-OO mode.
On-disk shuffles were found to produce wrong results in some highly-concurrent situations, especially on Windows. This has been resolved by a fix to the partd library.
Fixed a growth of open file descriptors that occurred under large data communications
Support ports in the
--bokeh-whitelistoption ot dask-scheduler to better routing of web interface messages behind non-trivial network settingsSome improvements to resilience to worker failure (though other known failures persist)
You can now start an IPython kernel on any worker for improved debugging and analysis
Improvements to
dask.dataframe.read_hdf, especially when reading from multiple files and docs
0.10.0 / 2016-06-13#
Major Changes#
This version drops support for Python 2.6
Conda packages are built and served from conda-forge
The
dask.distributedexecutables have been renamed from dfoo to dask-foo. For example dscheduler is renamed to dask-schedulerBoth Bag and DataFrame include a preliminary distributed shuffle.
Bag#
Add task-based shuffle for distributed groupbys
Add accumulate for cumulative reductions
DataFrame#
Add a task-based shuffle suitable for distributed joins, groupby-applys, and set_index operations. The single-machine shuffle remains untouched (and much more efficient.)
Add support for new Pandas rolling API with improved communication performance on distributed systems.
Add
groupby.std/varPass through S3/HDFS storage options in
read_csvImprove categorical partitioning
Add eval, info, isnull, notnull for dataframes
Distributed#
Rename executables like dscheduler to dask-scheduler
Improve scheduler performance in the many-fast-tasks case (important for shuffling)
Improve work stealing to be aware of expected function run-times and data sizes. The drastically increases the breadth of algorithms that can be efficiently run on the distributed scheduler without significant user expertise.
Support maximum buffer sizes in streaming queues
Improve Windows support when using the Bokeh diagnostic web interface
Support compression of very-large-bytestrings in protocol
Support clean cancellation of submitted futures in Joblib interface
Other#
All dask-related projects (dask, distributed, s3fs, hdfs, partd) are now building conda packages on conda-forge.
Change credential handling in s3fs to only pass around delegated credentials if explicitly given secret/key. The default now is to rely on managed environments. This can be changed back by explicitly providing a keyword argument. Anonymous mode must be explicitly declared if desired.
0.9.0 / 2016-05-11#
API Changes#
dask.doanddask.valuehave been renamed todask.delayeddask.bag.from_filenameshas been renamed todask.bag.read_textAll S3/HDFS data ingest functions like
db.from_s3ordistributed.s3.read_csvhave been moved into the plainread_text,read_csv functions, which now support protocols, likedd.read_csv('s3://bucket/keys*.csv')
Array#
Add support for
scipy.LinearOperatorImprove optional locking to on-disk data structures
Change rechunk to expose the intermediate chunks
Bag#
Rename
from_filenames toread_textRemove
from_s3in favor ofread_text('s3://...')
DataFrame#
Fixed numerical stability issue for correlation and covariance
Allow no-hash
from_pandasfor speedy round-trips to and from-pandas objectsGenerally reengineered
read_csvto be more in line with Pandas behaviorSupport fast
set_indexoperations for sorted columns
Delayed#
Rename
do/valuetodelayedRename
to/from_imperativetoto/from_delayed
Distributed#
Move s3 and hdfs functionality into the dask repository
Adaptively oversubscribe workers for very fast tasks
Improve PyPy support
Improve work stealing for unbalanced workers
Scatter data efficiently with tree-scatters
Other#
Add lzma/xz compression support
Raise a warning when trying to split unsplittable compression types, like gzip or bz2
Improve hashing for single-machine shuffle operations
Add new callback method for start state
General performance tuning
0.8.1 / 2016-03-11#
Array#
Bugfix for range slicing that could periodically lead to incorrect results.
Improved support and resiliency of
argreductions (argmin,argmax, etc.)
Bag#
Add
zipfunction
DataFrame#
Add
corrandcovfunctionsAdd
meltfunctionBugfixes for io to bcolz and hdf5
0.8.0 / 2016-02-20#
Array#
Changed default array reduction split from 32 to 4
Linear algebra,
tril,triu,LU,inv,cholesky,solve,solve_triangular,eye,lstsq,diag,corrcoef.
Bag#
Add tree reductions
Add range function
drop
from_hdfsfunction (better functionality now exists in hdfs3 and distributed projects)
DataFrame#
Refactor
dask.dataframeto include a full empty pandas dataframe as metadata. Drop the.columnsattribute on SeriesAdd Series categorical accessor, series.nunique, drop the
.columnsattribute for series.read_csvfixes (multi-column parse_dates, integer column names, etc. )Internal changes to improve graph serialization
Other#
Documentation updates
Add from_imperative and to_imperative functions for all collections
Aesthetic changes to profiler plots
Moved the dask project to a new dask organization
0.7.6 / 2016-01-05#
Array#
Improve thread safety
Tree reductions
Add
view,compress,hstack,dstack,vstackmethodsmap_blockscan now remove and add dimensions
DataFrame#
Improve thread safety
Extend sampling to include replacement options
Imperative#
Removed optimization passes that fused results.
Core#
Removed
dask.distributedImproved performance of blocked file reading
Serialization improvements
Test Python 3.5
0.7.4 / 2015-10-23#
This was mostly a bugfix release. Some notable changes:
Fix minor bugs associated with the release of numpy 1.10 and pandas 0.17
Fixed a bug with random number generation that would cause repeated blocks due to the birthday paradox
Use locks in
dask.dataframe.read_hdfby default to avoid concurrency issuesChange
dask.getto point todask.async.get_syncby defaultAllow visualization functions to accept general graphviz graph options like rankdir=’LR’
Add reshape and ravel to
dask.arraySupport the creation of
dask.arraysfromdask.imperativeobjects
Deprecation#
This release also includes a deprecation warning for dask.distributed, which
will be removed in the next version.
Future development in distributed computing for dask is happening here: https://distributed.dask.org . General feedback on that project is most welcome from this community.
0.7.3 / 2015-09-25#
Diagnostics#
A utility for profiling memory and cpu usage has been added to the
dask.diagnosticsmodule.
DataFrame#
This release improves coverage of the pandas API. Among other things
it includes nunique, nlargest, quantile. Fixes encoding issues
with reading non-ascii csv files. Performance improvements and bug fixes
with resample. More flexible read_hdf with globbing. And many more. Various
bug fixes in dask.imperative and dask.bag.
0.7.0 / 2015-08-15#
DataFrame#
This release includes significant bugfixes and alignment with the Pandas API. This has resulted both from use and from recent involvement by Pandas core developers.
New operations: query, rolling operations, drop
Improved operations: quantiles, arithmetic on full dataframes, dropna, constructor logic, merge/join, elemwise operations, groupby aggregations
Bag#
Fixed a bug in fold where with a null default argument
Array#
New operations: da.fft module, da.image.imread
Infrastructure#
The array and dataframe collections create graphs with deterministic keys. These tend to be longer (hash strings) but should be consistent between computations. This will be useful for caching in the future.
All collections (Array, Bag, DataFrame) inherit from common subclass
0.6.1 / 2015-07-23#
Distributed#
Improved (though not yet sufficient) resiliency for
dask.distributedwhen workers die
DataFrame#
Improved writing to various formats, including to_hdf, to_castra, and to_csv
Improved creation of dask DataFrames from dask Arrays and Bags
Improved support for categoricals and various other methods
Array#
Various bug fixes
Histogram function
Scheduling#
Added tie-breaking ordering of tasks within parallel workloads to better handle and clear intermediate results
Other#
Added the dask.do function for explicit construction of graphs with normal python code
Traded pydot for graphviz library for graph printing to support Python3
There is also a gitter chat room and a stackoverflow tag