{kind=link}
dask.array.map_blocks#
- dask.array.map_blocks(func, *args, name=None, token=None, dtype=None, chunks=None, drop_axis=None, new_axis=None, enforce_ndim=False, meta=None, **kwargs)[source]#
Map a function across all blocks of a dask array.
Note that
map_blockswill attempt to automatically determine the output array type by callingfuncon 0-d versions of the inputs. Please refer to themetakeyword argument below if you expect that the function will not succeed when operating on 0-d arrays.- Parameters:
- funccallable
Function to apply to every block in the array. If
funcacceptsblock_info=orblock_id=as keyword arguments, these will be passed dictionaries containing information about input and output chunks/arrays during computation. See examples for details.- argsdask arrays or other objects
- dtypenp.dtype, optional
The
dtypeof the output array. It is recommended to provide this. If not provided, will be inferred by applying the function to a small set of fake data.- chunkstuple, optional
Chunk shape of resulting blocks if the function does not preserve shape. If not provided, the resulting array is assumed to have the same block structure as the first input array.
- drop_axisnumber or iterable, optional
Dimensions lost by the function.
- new_axisnumber or iterable, optional
New dimensions created by the function. Note that these are applied after
drop_axis(if present). The size of each chunk along this dimension will be set to 1. Please specifychunksif the individual chunks have a different size.- enforce_ndimbool, default False
Whether to enforce at runtime that the dimensionality of the array produced by
funcactually matches that of the array returned bymap_blocks. If True, this will raise an error when there is a mismatch.- tokenstring, optional
The key prefix to use for the output array. If not provided, will be determined from the function name.
- namestring, optional
The key name to use for the output array. Note that this fully specifies the output key name, and must be unique. If not provided, will be determined by a hash of the arguments.
- metaarray-like, optional
The
metaof the output array, when specified is expected to be an array of the same type and dtype of that returned when calling.compute()on the array returned by this function. When not provided,metawill be inferred by applying the function to a small set of fake data, usually a 0-d array. It’s important to ensure thatfunccan successfully complete computation without raising exceptions when 0-d is passed to it, providingmetawill be required otherwise. If the output type is known beforehand (e.g.,np.ndarray,cupy.ndarray), an empty array of such type dtype can be passed, for example:meta=np.array((), dtype=np.int32).- **kwargs
Other keyword arguments to pass to function. Values must be constants (not dask.arrays)
See also
dask.array.map_overlapGeneralized operation with overlap between neighbors.
dask.array.blockwiseGeneralized operation with control over block alignment.
Examples
>>> import dask.array as da >>> x = da.arange(6, chunks=3)
>>> x.map_blocks(lambda x: x * 2).compute() array([ 0, 2, 4, 6, 8, 10])
The
da.map_blocksfunction can also accept multiple arrays.>>> d = da.arange(5, chunks=2) >>> e = da.arange(5, chunks=2)
>>> f = da.map_blocks(lambda a, b: a + b**2, d, e) >>> f.compute() array([ 0, 2, 6, 12, 20])
If the function changes shape of the blocks then you must provide chunks explicitly.
>>> y = x.map_blocks(lambda x: x[::2], chunks=((2, 2),))
You have a bit of freedom in specifying chunks. If all of the output chunk sizes are the same, you can provide just that chunk size as a single tuple.
>>> a = da.arange(18, chunks=(6,)) >>> b = a.map_blocks(lambda x: x[:3], chunks=(3,))
If the function changes the dimension of the blocks you must specify the created or destroyed dimensions.
>>> b = a.map_blocks(lambda x: x[None, :, None], chunks=(1, 6, 1), ... new_axis=[0, 2])
If
chunksis specified butnew_axisis not, then it is inferred to add the necessary number of axes on the left.Note that
map_blocks()will concatenate chunks along axes specified by the keyword parameterdrop_axisprior to applying the function. This is illustrated in the figure below: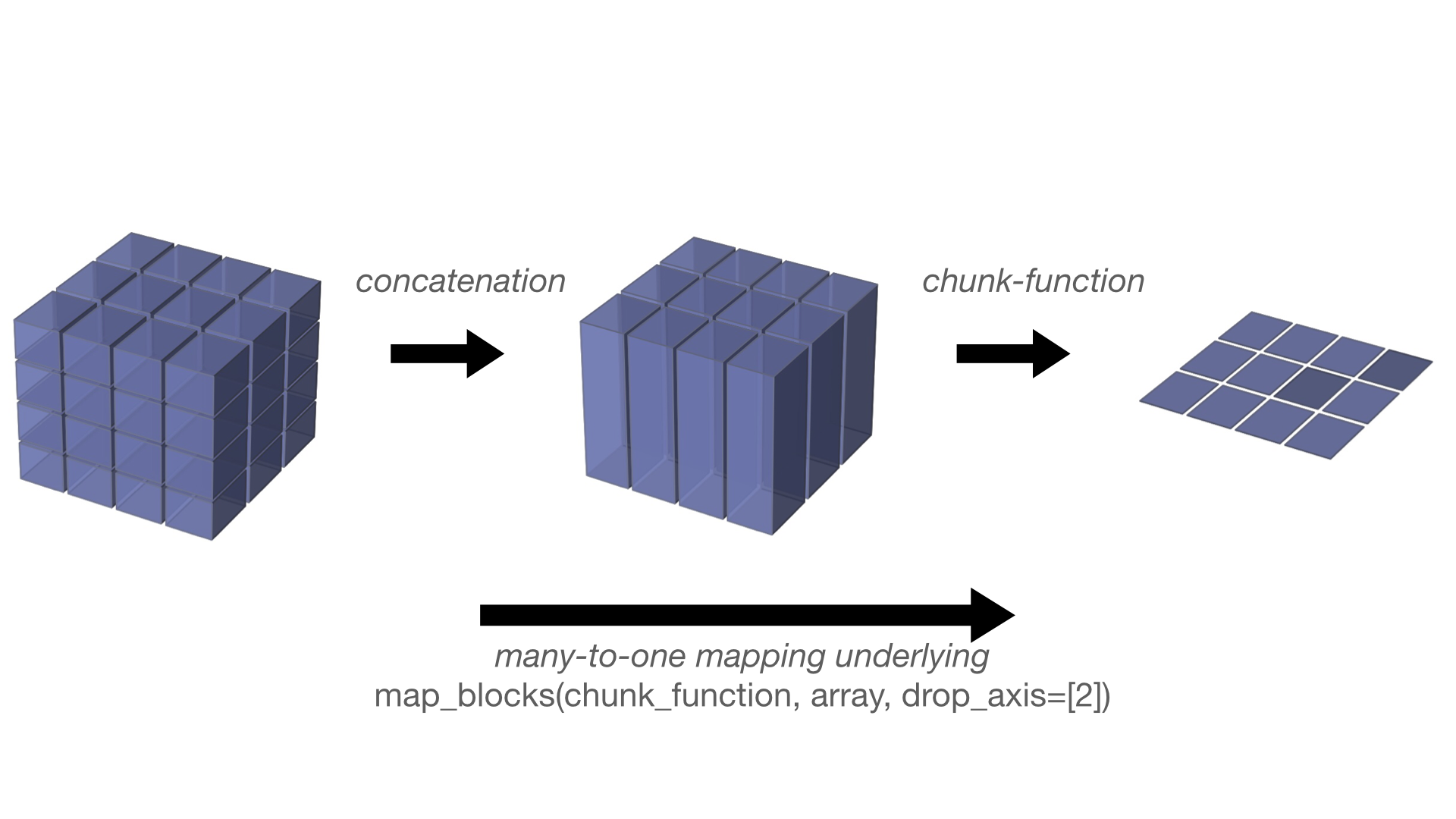
Due to memory-size-constraints, it is often not advisable to use
drop_axison an axis that is chunked. In that case, it is better not to usemap_blocksbut ratherdask.array.reduction(..., axis=dropped_axes, concatenate=False)which maintains a leaner memory footprint while it drops any axis.Map_blocks aligns blocks by block positions without regard to shape. In the following example we have two arrays with the same number of blocks but with different shape and chunk sizes.
>>> x = da.arange(1000, chunks=(100,)) >>> y = da.arange(100, chunks=(10,))
The relevant attribute to match is numblocks.
>>> x.numblocks (10,) >>> y.numblocks (10,)
If these match (up to broadcasting rules) then we can map arbitrary functions across blocks
>>> def func(a, b): ... return np.array([a.max(), b.max()])
>>> da.map_blocks(func, x, y, chunks=(2,), dtype='i8') dask.array<func, shape=(20,), dtype=int64, chunksize=(2,), chunktype=numpy.ndarray>
>>> _.compute() array([ 99, 9, 199, 19, 299, 29, 399, 39, 499, 49, 599, 59, 699, 69, 799, 79, 899, 89, 999, 99])
Your block function can get information about where it is in the array by accepting a special
block_infoorblock_idkeyword argument. During computation, they will contain information about each of the input and output chunks (and dask arrays) relevant to each call offunc.>>> def func(block_info=None): ... pass
This will receive the following information:
>>> block_info {0: {'shape': (1000,), 'num-chunks': (10,), 'chunk-location': (4,), 'array-location': [(400, 500)]}, None: {'shape': (1000,), 'num-chunks': (10,), 'chunk-location': (4,), 'array-location': [(400, 500)], 'chunk-shape': (100,), 'dtype': dtype('float64')}}
The keys to the
block_infodictionary indicate which is the input and output Dask array:Input Dask array(s):
block_info[0]refers to the first input Dask array. The dictionary key is0because that is the argument index corresponding to the first input Dask array. In cases where multiple Dask arrays have been passed as input to the function, you can access them with the number corresponding to the input argument, eg:block_info[1],block_info[2], etc. (Note that if you pass multiple Dask arrays as input to map_blocks, the arrays must match each other by having matching numbers of chunks, along corresponding dimensions up to broadcasting rules.)Output Dask array:
block_info[None]refers to the output Dask array, and contains information about the output chunks. The output chunk shape and dtype may may be different than the input chunks.
For each dask array,
block_infodescribes:shape: the shape of the full Dask array,num-chunks: the number of chunks of the full array in each dimension,chunk-location: the chunk location (for example the fourth chunk over in the first dimension), andarray-location: the array location within the full Dask array (for example the slice corresponding to40:50).
In addition to these, there are two extra parameters described by
block_infofor the output array (inblock_info[None]):chunk-shape: the output chunk shape, anddtype: the output dtype.
These features can be combined to synthesize an array from scratch, for example:
>>> def func(block_info=None): ... loc = block_info[None]['array-location'][0] ... return np.arange(loc[0], loc[1])
>>> da.map_blocks(func, chunks=((4, 4),), dtype=np.float64) dask.array<func, shape=(8,), dtype=float64, chunksize=(4,), chunktype=numpy.ndarray>
>>> _.compute() array([0, 1, 2, 3, 4, 5, 6, 7])
block_idis similar toblock_infobut contains only thechunk_location:>>> def func(block_id=None): ... pass
This will receive the following information:
>>> block_id (4, 3)
You may specify the key name prefix of the resulting task in the graph with the optional
tokenkeyword argument.>>> x.map_blocks(lambda x: x + 1, name='increment') dask.array<increment, shape=(1000,), dtype=int64, chunksize=(100,), chunktype=numpy.ndarray>
For functions that may not handle 0-d arrays, it’s also possible to specify
metawith an empty array matching the type of the expected result. In the example below,funcwill result in anIndexErrorwhen computingmeta:>>> rng = da.random.default_rng() >>> da.map_blocks(lambda x: x[2], rng.random(5), meta=np.array(())) dask.array<lambda, shape=(5,), dtype=float64, chunksize=(5,), chunktype=numpy.ndarray>
Similarly, it’s possible to specify a non-NumPy array to
meta, and provide adtype:>>> import cupy >>> rng = da.random.default_rng(cupy.random.default_rng()) >>> dt = np.float32 >>> da.map_blocks(lambda x: x[2], rng.random(5, dtype=dt), meta=cupy.array((), dtype=dt)) dask.array<lambda, shape=(5,), dtype=float32, chunksize=(5,), chunktype=cupy.ndarray>